 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Mar 03, 2025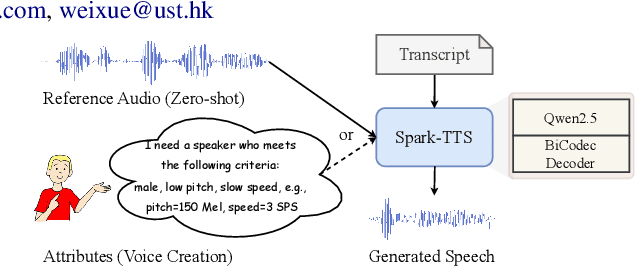
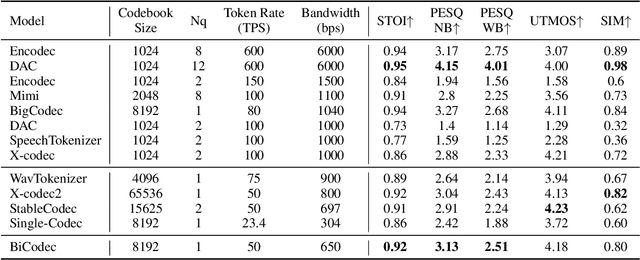
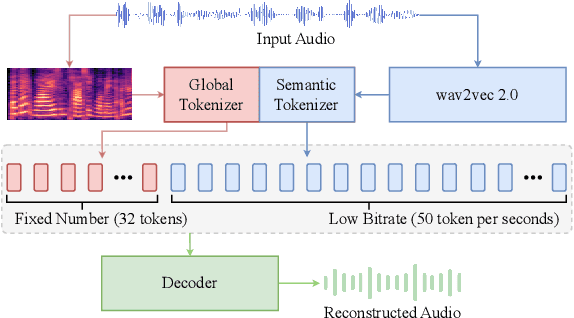
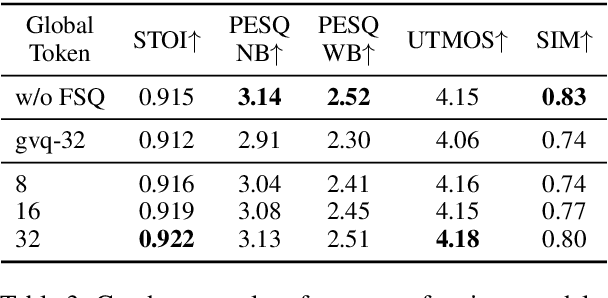
Recent advancements in large language models (LLMs) have driven significant progress in zero-shot text-to-speech (TTS) synthesis. However, existing foundation models rely on multi-stage processing or complex architectures for predicting multiple codebooks, limiting efficiency and integration flexibility. To overcome these challenges, we introduce Spark-TTS, a novel system powered by BiCodec, a single-stream speech codec that decomposes speech into two complementary token types: low-bitrate semantic tokens for linguistic content and fixed-length global tokens for speaker attributes. This disentangled representation, combined with the Qwen2.5 LLM and a chain-of-thought (CoT) generation approach, enables both coarse-grained control (e.g., gender, speaking style) and fine-grained adjustments (e.g., precise pitch values, speaking rate). To facilitate research in controllable TTS, we introduce VoxBox, a meticulously curated 100,000-hour dataset with comprehensive attribute annotations. Extensive experiments demonstrate that Spark-TTS not only achieves state-of-the-art zero-shot voice cloning but also generates highly customizable voices that surpass the limitations of reference-based synthesis. Source code, pre-trained models, and audio samples are available at https://github.com/SparkAudio/Spark-TTS.
Llasa: Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis
Feb 06, 2025Recent advances in text-based large language models (LLMs), particularly in the GPT series and the o1 model, have demonstrated the effectiveness of scaling both training-time and inference-time compute. However, current state-of-the-art TTS systems leveraging LLMs are often multi-stage, requiring separate models (e.g., diffusion models after LLM), complicating the decision of whether to scale a particular model during training or testing. This work makes the following contributions: First, we explore the scaling of train-time and inference-time compute for speech synthesis. Second, we propose a simple framework Llasa for speech synthesis that employs a single-layer vector quantizer (VQ) codec and a single Transformer architecture to fully align with standard LLMs such as Llama. Our experiments reveal that scaling train-time compute for Llasa consistently improves the naturalness of synthesized speech and enables the generation of more complex and accurate prosody patterns. Furthermore, from the perspective of scaling inference-time compute, we employ speech understanding models as verifiers during the search, finding that scaling inference-time compute shifts the sampling modes toward the preferences of specific verifiers, thereby improving emotional expressiveness, timbre consistency, and content accuracy. In addition, we released the checkpoint and training code for our TTS model (1B, 3B, 8B) and codec model publicly available.
Single-Codec: Single-Codebook Speech Codec towards High-Performance Speech Generation
Jun 11, 2024


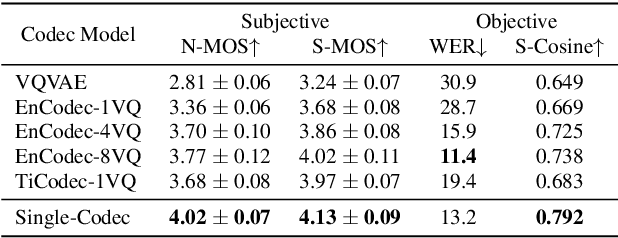
The multi-codebook speech codec enables the application of large language models (LLM) in TTS but bottlenecks efficiency and robustness due to multi-sequence prediction. To avoid this obstacle, we propose Single-Codec, a single-codebook single-sequence codec, which employs a disentangled VQ-VAE to decouple speech into a time-invariant embedding and a phonetically-rich discrete sequence. Furthermore, the encoder is enhanced with 1) contextual modeling with a BLSTM module to exploit the temporal information, 2) a hybrid sampling module to alleviate distortion from upsampling and downsampling, and 3) a resampling module to encourage discrete units to carry more phonetic information. Compared with multi-codebook codecs, e.g., EnCodec and TiCodec, Single-Codec demonstrates higher reconstruction quality with a lower bandwidth of only 304bps. The effectiveness of Single-Code is further validated by LLM-TTS experiments, showing improved naturalness and intelligibility.
SponTTS: modeling and transferring spontaneous style for TTS
Nov 13, 2023Spontaneous speaking style exhibits notable differences from other speaking styles due to various spontaneous phenomena (e.g., filled pauses, prolongation) and substantial prosody variation (e.g., diverse pitch and duration variation, occasional non-verbal speech like smile), posing challenges to modeling and prediction of spontaneous style. Moreover, the limitation of high-quality spontaneous data constrains spontaneous speech generation for speakers without spontaneous data. To address these problems, we propose SponTTS, a two-stage approach based on bottleneck (BN) features to model and transfer spontaneous style for TTS. In the first stage, we adopt a Conditional Variational Autoencoder (CVAE) to capture spontaneous prosody from a BN feature and involve the spontaneous phenomena by the constraint of spontaneous phenomena embedding prediction loss. Besides, we introduce a flow-based predictor to predict a latent spontaneous style representation from the text, which enriches the prosody and context-specific spontaneous phenomena during inference. In the second stage, we adopt a VITS-like module to transfer the spontaneous style learned in the first stage to target speakers. Experiments demonstrate that SponTTS is effective in modeling spontaneous style and transferring the style to the target speakers, generating spontaneous speech with high naturalness, expressiveness, and speaker similarity. The zero-shot spontaneous style TTS test further verifies the generalization and robustness of SponTTS in generating spontaneous speech for unseen speakers.
PromptSpeaker: Speaker Generation Based on Text Descriptions
Oct 08, 2023



Recently, text-guided content generation has received extensive attention. In this work, we explore the possibility of text description-based speaker generation, i.e., using text prompts to control the speaker generation process. Specifically, we propose PromptSpeaker, a text-guided speaker generation system. PromptSpeaker consists of a prompt encoder, a zero-shot VITS, and a Glow model, where the prompt encoder predicts a prior distribution based on the text description and samples from this distribution to obtain a semantic representation. The Glow model subsequently converts the semantic representation into a speaker representation, and the zero-shot VITS finally synthesizes the speaker's voice based on the speaker representation. We verify that PromptSpeaker can generate speakers new from the training set by objective metrics, and the synthetic speaker voice has reasonable subjective matching quality with the speaker prompt.
PromptStyle: Controllable Style Transfer for Text-to-Speech with Natural Language Descriptions
Jun 01, 2023Style transfer TTS has shown impressive performance in recent years. However, style control is often restricted to systems built on expressive speech recordings with discrete style categories. In practical situations, users may be interested in transferring style by typing text descriptions of desired styles, without the reference speech in the target style. The text-guided content generation techniques have drawn wide attention recently. In this work, we explore the possibility of controllable style transfer with natural language descriptions. To this end, we propose PromptStyle, a text prompt-guided cross-speaker style transfer system. Specifically, PromptStyle consists of an improved VITS and a cross-modal style encoder. The cross-modal style encoder constructs a shared space of stylistic and semantic representation through a two-stage training process. Experiments show that PromptStyle can achieve proper style transfer with text prompts while maintaining relatively high stability and speaker similarity. Audio samples are available in our demo page.