 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Codec: Single-Codebook Speech Codec towards High-Performance Speech Generation
Paper and Code



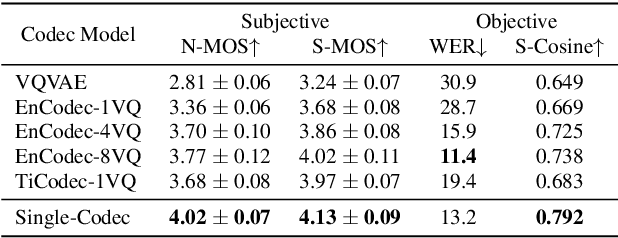
The multi-codebook speech codec enables the application of large language models (LLM) in TTS but bottlenecks efficiency and robustness due to multi-sequence prediction. To avoid this obstacle, we propose Single-Codec, a single-codebook single-sequence codec, which employs a disentangled VQ-VAE to decouple speech into a time-invariant embedding and a phonetically-rich discrete sequence. Furthermore, the encoder is enhanced with 1) contextual modeling with a BLSTM module to exploit the temporal information, 2) a hybrid sampling module to alleviate distortion from upsampling and downsampling, and 3) a resampling module to encourage discrete units to carry more phonetic information. Compared with multi-codebook codecs, e.g., EnCodec and TiCodec, Single-Codec demonstrates higher reconstruction quality with a lower bandwidth of only 304bps. The effectiveness of Single-Code is further validated by LLM-TTS experiments, showing improved naturalness and intelligibility.