 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptSpeaker: Speaker Generation Based on Text Descriptions
Oct 08, 2023



Recently, text-guided content generation has received extensive attention. In this work, we explore the possibility of text description-based speaker generation, i.e., using text prompts to control the speaker generation process. Specifically, we propose PromptSpeaker, a text-guided speaker generation system. PromptSpeaker consists of a prompt encoder, a zero-shot VITS, and a Glow model, where the prompt encoder predicts a prior distribution based on the text description and samples from this distribution to obtain a semantic representation. The Glow model subsequently converts the semantic representation into a speaker representation, and the zero-shot VITS finally synthesizes the speaker's voice based on the speaker representation. We verify that PromptSpeaker can generate speakers new from the training set by objective metrics, and the synthetic speaker voice has reasonable subjective matching quality with the speaker prompt.
PromptStyle: Controllable Style Transfer for Text-to-Speech with Natural Language Descriptions
Jun 01, 2023Style transfer TTS has shown impressive performance in recent years. However, style control is often restricted to systems built on expressive speech recordings with discrete style categories. In practical situations, users may be interested in transferring style by typing text descriptions of desired styles, without the reference speech in the target style. The text-guided content generation techniques have drawn wide attention recently. In this work, we explore the possibility of controllable style transfer with natural language descriptions. To this end, we propose PromptStyle, a text prompt-guided cross-speaker style transfer system. Specifically, PromptStyle consists of an improved VITS and a cross-modal style encoder. The cross-modal style encoder constructs a shared space of stylistic and semantic representation through a two-stage training process. Experiments show that PromptStyle can achieve proper style transfer with text prompts while maintaining relatively high stability and speaker similarity. Audio samples are available in our demo page.
The Multi-speaker Multi-style Voice Cloning Challenge 2021
Apr 05, 2021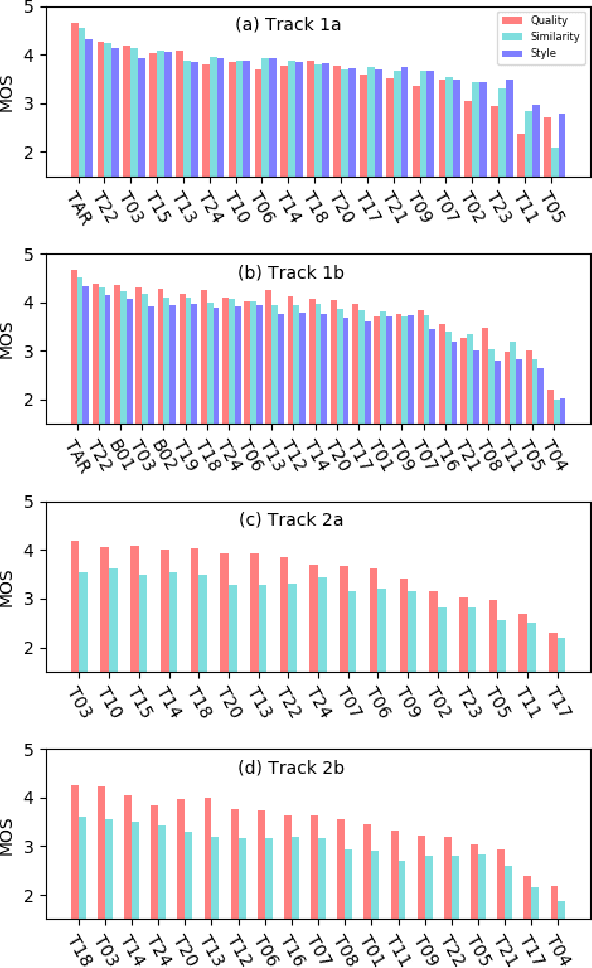
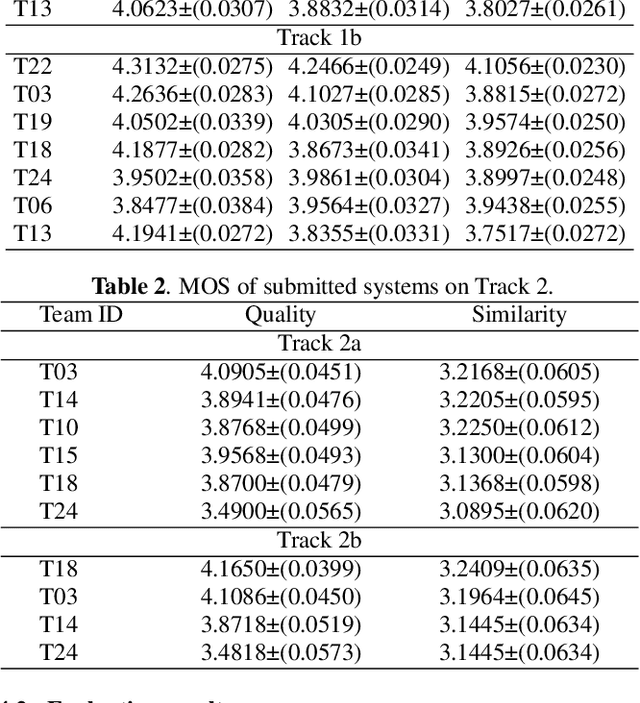
The Multi-speaker Multi-style Voice Cloning Challenge (M2VoC) aims to provide a common sizable dataset as well as a fair testbed for the benchmarking of the popular voice cloning task. Specifically, we formulate the challenge to adapt an average TTS model to the stylistic target voice with limited data from target speaker, evaluated by speaker identity and style similarity. The challenge consists of two tracks, namely few-shot track and one-shot track, where the participants are required to clone multiple target voices with 100 and 5 samples respectively. There are also two sub-tracks in each track. For sub-track a, to fairly compare different strategies, the participants are allowed to use only the training data provided by the organizer strictly. For sub-track b, the participants are allowed to use any data publicly available. In this paper, we present a detailed explanation on the tasks and data used in the challenge, followed by a summary of submitted systems and evaluation results.