 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Multi-speaker Multi-style Voice Cloning Challenge 2021
Apr 05, 2021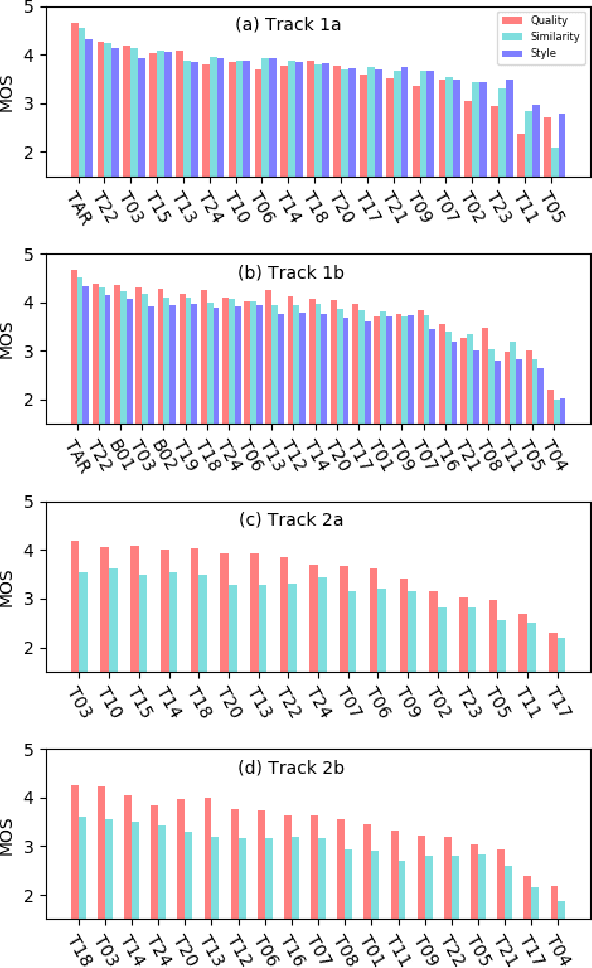
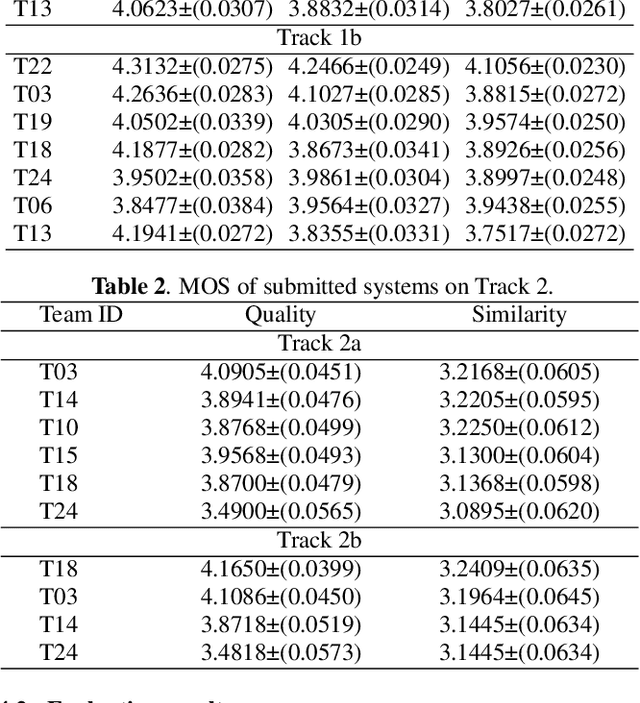
The Multi-speaker Multi-style Voice Cloning Challenge (M2VoC) aims to provide a common sizable dataset as well as a fair testbed for the benchmarking of the popular voice cloning task. Specifically, we formulate the challenge to adapt an average TTS model to the stylistic target voice with limited data from target speaker, evaluated by speaker identity and style similarity. The challenge consists of two tracks, namely few-shot track and one-shot track, where the participants are required to clone multiple target voices with 100 and 5 samples respectively. There are also two sub-tracks in each track. For sub-track a, to fairly compare different strategies, the participants are allowed to use only the training data provided by the organizer strictly. For sub-track b, the participants are allowed to use any data publicly available. In this paper, we present a detailed explanation on the tasks and data used in the challenge, followed by a summary of submitted systems and evaluation results.