 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGS4: Generalizable Sparse Splatting Semantic SLAM
Jun 06, 2025Traditional SLAM algorithms are excellent at camera tracking but might generate lower resolution and incomplete 3D maps. Recently, Gaussian Splatting (GS) approaches have emerged as an option for SLAM with accurate, dense 3D map building. However, existing GS-based SLAM methods rely on per-scene optimization which is time-consuming and does not generalize to diverse scenes well. In this work, we introduce the first generalizable GS-based semantic SLAM algorithm that incrementally builds and updates a 3D scene representation from an RGB-D video stream using a learned generalizable network. Our approach starts from an RGB-D image recognition backbone to predict the Gaussian parameters from every downsampled and backprojected image location. Additionally, we seamlessly integrate 3D semantic segmentation into our GS framework, bridging 3D mapping and recognition through a shared backbone. To correct localization drifting and floaters, we propose to optimize the GS for only 1 iteration following global localization. We demonstrate state-of-the-art semantic SLAM performance on the real-world benchmark ScanNet with an order of magnitude fewer Gaussians compared to other recent GS-based methods, and showcase our model's generalization capability through zero-shot transfer to the NYUv2 and TUM RGB-D datasets.
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Mar 03, 2025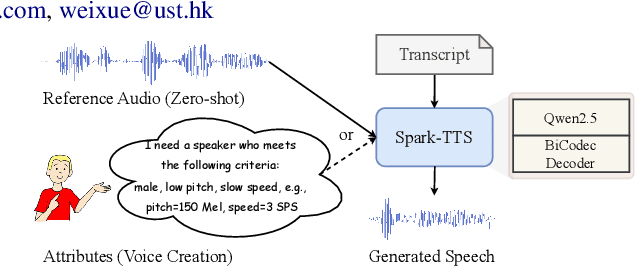
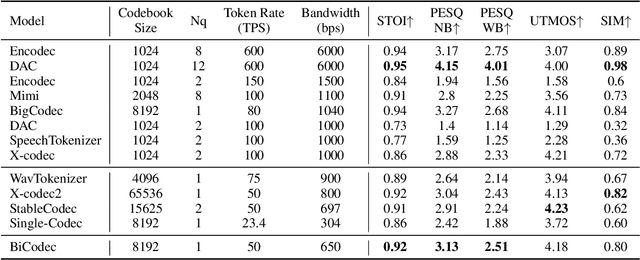
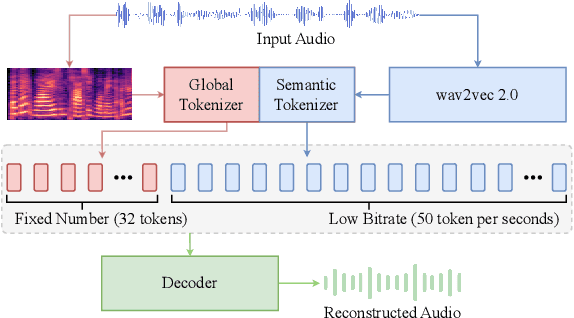
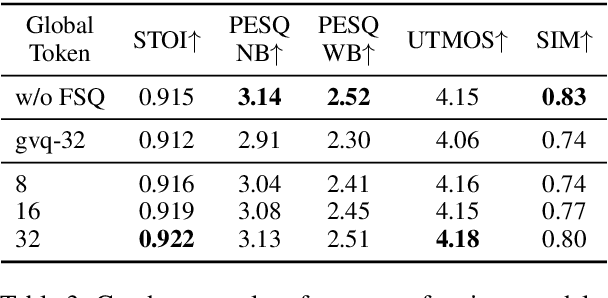
Recent advancements in large language models (LLMs) have driven significant progress in zero-shot text-to-speech (TTS) synthesis. However, existing foundation models rely on multi-stage processing or complex architectures for predicting multiple codebooks, limiting efficiency and integration flexibility. To overcome these challenges, we introduce Spark-TTS, a novel system powered by BiCodec, a single-stream speech codec that decomposes speech into two complementary token types: low-bitrate semantic tokens for linguistic content and fixed-length global tokens for speaker attributes. This disentangled representation, combined with the Qwen2.5 LLM and a chain-of-thought (CoT) generation approach, enables both coarse-grained control (e.g., gender, speaking style) and fine-grained adjustments (e.g., precise pitch values, speaking rate). To facilitate research in controllable TTS, we introduce VoxBox, a meticulously curated 100,000-hour dataset with comprehensive attribute annotations. Extensive experiments demonstrate that Spark-TTS not only achieves state-of-the-art zero-shot voice cloning but also generates highly customizable voices that surpass the limitations of reference-based synthesis. Source code, pre-trained models, and audio samples are available at https://github.com/SparkAudio/Spark-TTS.
Taming the Tail in Class-Conditional GANs: Knowledge Sharing via Unconditional Training at Lower Resolutions
Feb 26, 2024
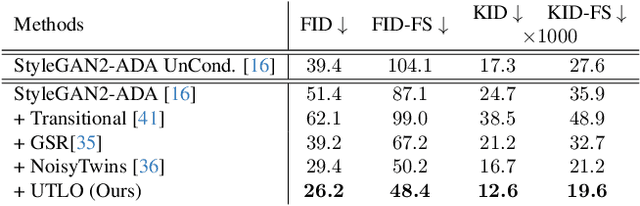
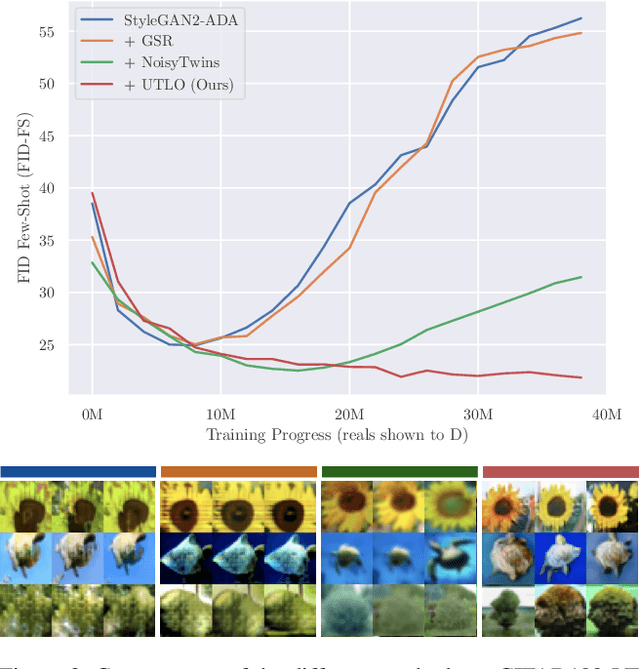

Despite the extensive research on training generative adversarial networks (GANs) with limited training data, learning to generate images from long-tailed training distributions remains fairly unexplored. In the presence of imbalanced multi-class training data, GANs tend to favor classes with more samples, leading to the generation of low-quality and less diverse samples in tail classes. In this study, we aim to improve the training of class-conditional GANs with long-tailed data. We propose a straightforward yet effective method for knowledge sharing, allowing tail classes to borrow from the rich information from classes with more abundant training data. More concretely, we propose modifications to existing class-conditional GAN architectures to ensure that the lower-resolution layers of the generator are trained entirely unconditionally while reserving class-conditional generation for the higher-resolution layers. Experiments on several long-tail benchmarks and GAN architectures demonstrate a significant improvement over existing methods in both the diversity and fidelity of the generated images. The code is available at https://github.com/khorrams/utlo.
Examining the Difference Among Transformers and CNNs with Explanation Methods
Dec 15, 2022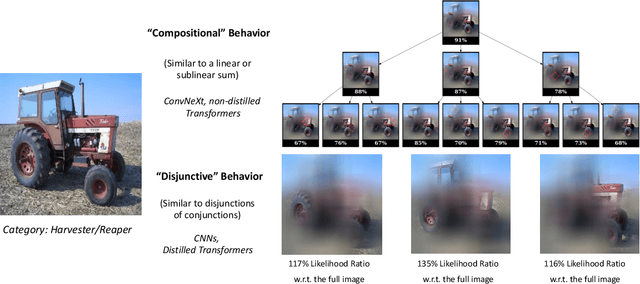
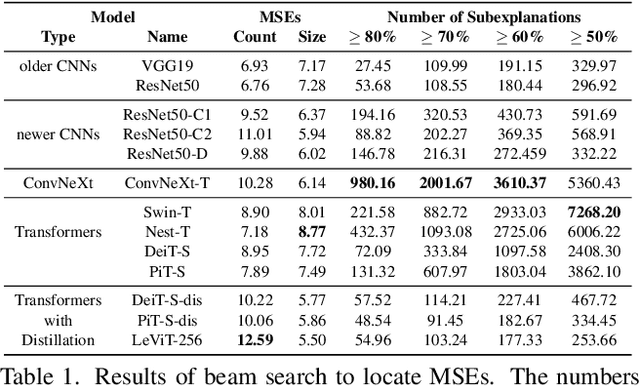

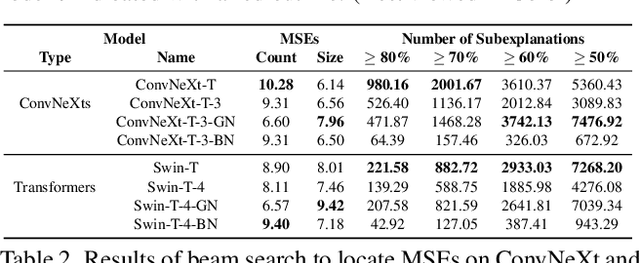
We propose a methodology that systematically applies deep explanation algorithms on a dataset-wide basis, to compare different types of visual recognition backbones, such as convolutional networks (CNNs), global attention networks, and local attention networks. Examination of both qualitative visualizations and quantitative statistics across the dataset helps us to gain intuitions that are not just anecdotal, but are supported by the statistics computed on the entire dataset. Specifically, we propose two methods. The first one, sub-explanation counting, systematically searches for minimally-sufficient explanations of all images and count the amount of sub-explanations for each network. The second one, called cross-testing, computes salient regions using one network and then evaluates the performance by only showing these regions as an image to other networks. Through a combination of qualitative insights and quantitative statistics, we illustrate that 1) there are significant differences between the salient features of CNNs and attention models; 2) the occlusion-robustness in local attention models and global attention models may come from different decision-making mechanisms.
Cross-speaker Emotion Transfer Based On Prosody Compensation for End-to-End Speech Synthesis
Jul 04, 2022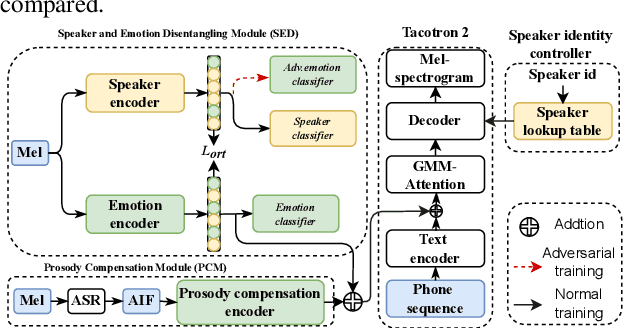
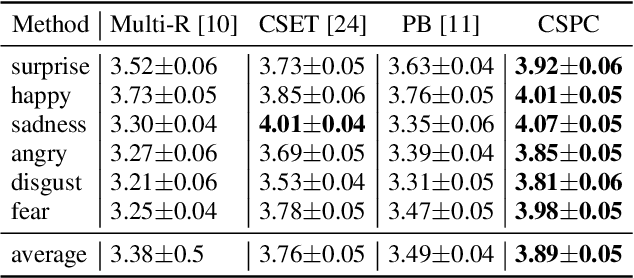
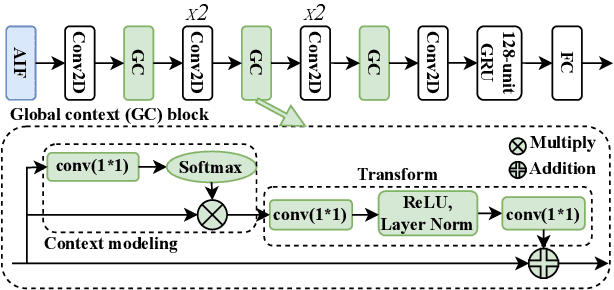
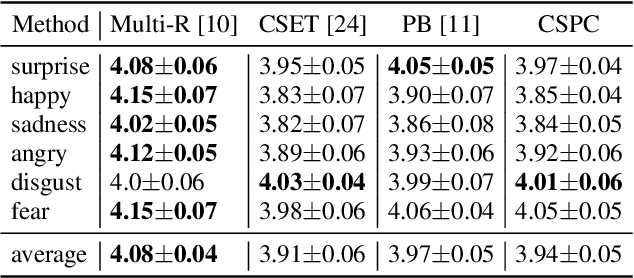
Cross-speaker emotion transfer speech synthesis aims to synthesize emotional speech for a target speaker by transferring the emotion from reference speech recorded by another (source) speaker. In this task, extracting speaker-independent emotion embedding from reference speech plays an important role. However, the emotional information conveyed by such emotion embedding tends to be weakened in the process to squeeze out the source speaker's timbre information. In response to this problem, a prosody compensation module (PCM) is proposed in this paper to compensate for the emotional information loss. Specifically, the PCM tries to obtain speaker-independent emotional information from the intermediate feature of a pre-trained ASR model. To this end, a prosody compensation encoder with global context (GC) blocks is introduced to obtain global emotional information from the ASR model's intermediate feature. Experiments demonstrate that the proposed PCM can effectively compensate the emotion embedding for the emotional information loss, and meanwhile maintain the timbre of the target speaker. Comparisons with state-of-the-art models show that our proposed method presents obvious superiority on the cross-speaker emotion transfer task.
ADBench: Anomaly Detection Benchmark
Jun 19, 2022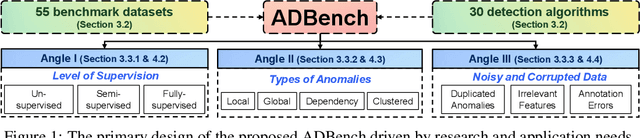

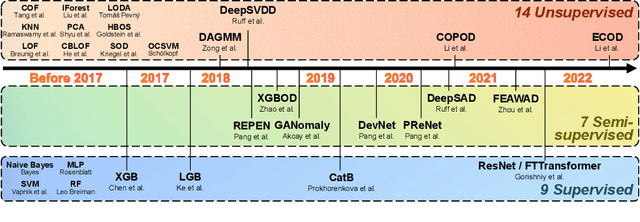
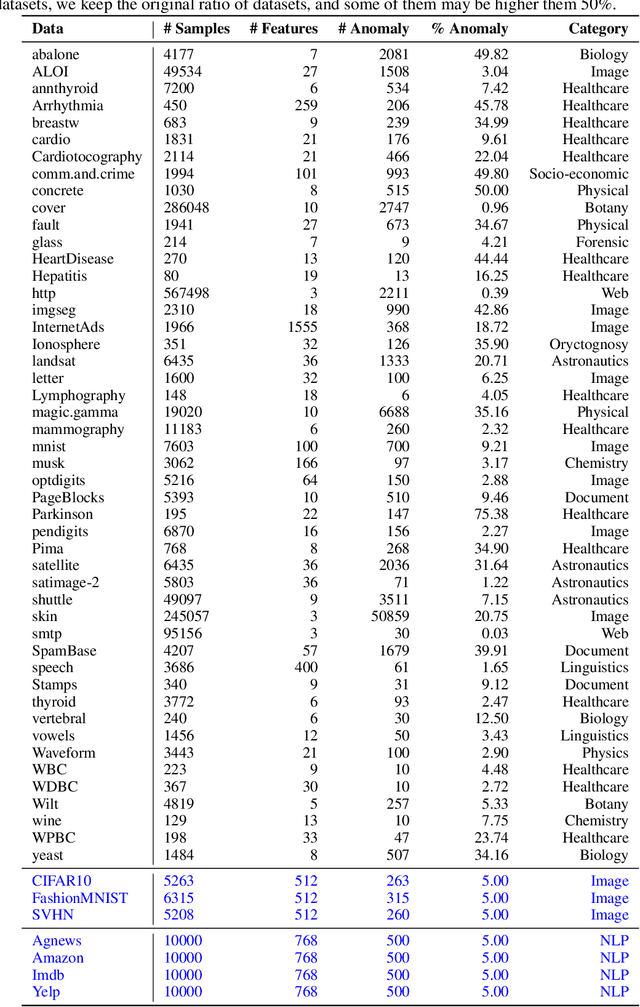
Given a long list of anomaly detection algorithms developed in the last few decades, how do they perform with regard to (i) varying levels of supervision, (ii) different types of anomalies, and (iii) noisy and corrupted data? In this work, we answer these key questions by conducting (to our best knowledge) the most comprehensive anomaly detection benchmark with 30 algorithms on 55 benchmark datasets, named ADBench. Our extensive experiments (93,654 in total) identify meaningful insights into the role of supervision and anomaly types, and unlock future directions for researchers in algorithm selection and design. With ADBench, researchers can easily conduct comprehensive and fair evaluations for newly proposed methods on the datasets (including our contributed ones from natural language and computer vision domains) against the existing baselines. To foster accessibility and reproducibility, we fully open-source ADBench and the corresponding results.