 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADBench: Anomaly Detection Benchmark
Paper and Code
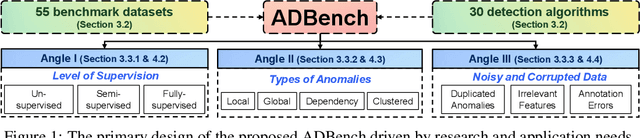

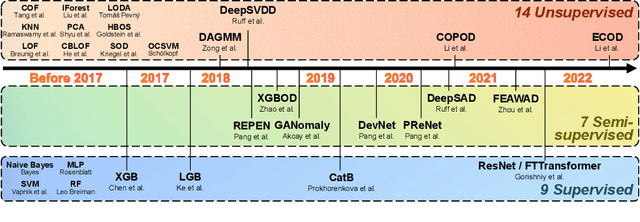
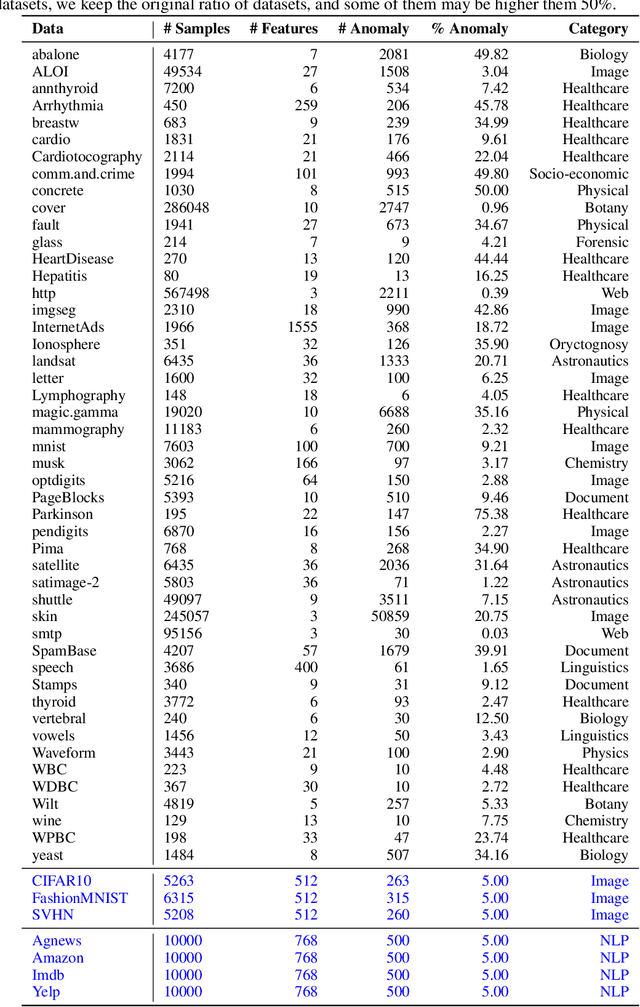
Given a long list of anomaly detection algorithms developed in the last few decades, how do they perform with regard to (i) varying levels of supervision, (ii) different types of anomalies, and (iii) noisy and corrupted data? In this work, we answer these key questions by conducting (to our best knowledge) the most comprehensive anomaly detection benchmark with 30 algorithms on 55 benchmark datasets, named ADBench. Our extensive experiments (93,654 in total) identify meaningful insights into the role of supervision and anomaly types, and unlock future directions for researchers in algorithm selection and design. With ADBench, researchers can easily conduct comprehensive and fair evaluations for newly proposed methods on the datasets (including our contributed ones from natural language and computer vision domains) against the existing baselines. To foster accessibility and reproducibility, we fully open-source ADBench and the corresponding results.