 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Design Engineering: An Empirical Study of What Makes Good Downstream Fine-Tuning Samples for LLMs
Apr 19, 2024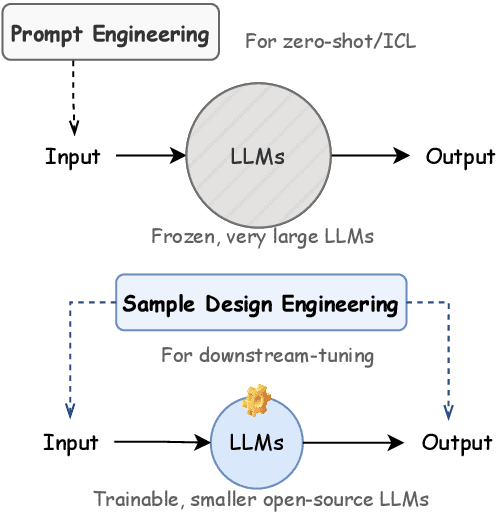
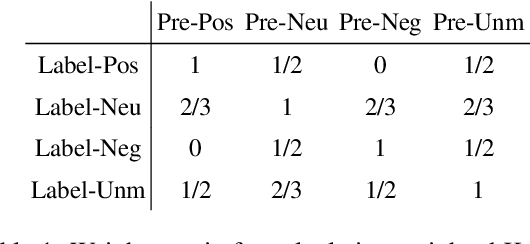
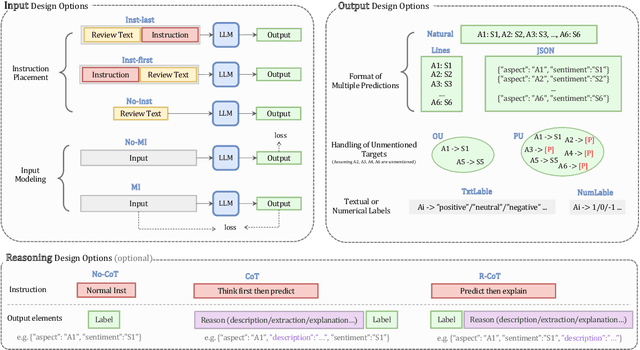
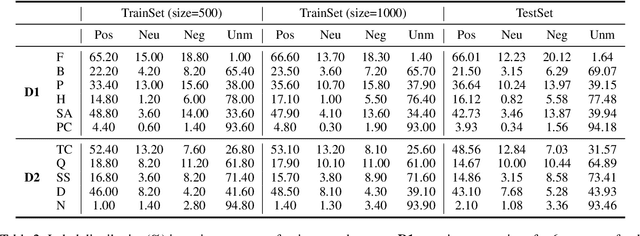
In the burgeoning field of Large Language Models (LLMs) like ChatGPT and LLaMA, Prompt Engineering (PE) is renowned for boosting zero-shot or in-context learning (ICL) through prompt modifications. Yet, the realm of the sample design for downstream fine-tuning, crucial for task-specific LLM adaptation, is largely unexplored. This paper introduces Sample Design Engineering (SDE), a methodical approach to enhancing LLMs' post-tuning performance by refining input, output, and reasoning designs. We conduct a series of in-domain (ID) and out-of-domain (OOD) experiments to assess the impact of various design options on LLMs' downstream performance, revealing several intriguing patterns that hold consistently across different LLMs. Based on these insights, we propose an integrated SDE strategy, combining the most effective options, and validate its consistent superiority over heuristic sample designs in complex downstream tasks like multi-aspect sentiment analysis, event extraction, and nested entity recognition. Additionally, analyses of LLMs' inherent prompt/output perplexity, zero-shot, and ICL abilities illustrate that good PE strategies may not always translate to good SDE strategies. Code available at https://github.com/beyondguo/LLM-Tuning.
Enhancing Molecular Property Prediction via Mixture of Collaborative Experts
Dec 06, 2023



Molecular Property Prediction (MPP) task involves predicting biochemical properties based on molecular features, such as molecular graph structures, contributing to the discovery of lead compounds in drug development. To address data scarcity and imbalance in MPP, some studies have adopted Graph Neural Networks (GNN) as an encoder to extract commonalities from molecular graphs. However, these approaches often use a separate predictor for each task, neglecting the shared characteristics among predictors corresponding to different tasks. In response to this limitation, we introduce the GNN-MoCE architecture. It employs the Mixture of Collaborative Experts (MoCE) as predictors, exploiting task commonalities while confronting the homogeneity issue in the expert pool and the decision dominance dilemma within the expert group. To enhance expert diversity for collaboration among all experts, the Expert-Specific Projection method is proposed to assign a unique projection perspective to each expert. To balance decision-making influence for collaboration within the expert group, the Expert-Specific Loss is presented to integrate individual expert loss into the weighted decision loss of the group for more equitable training. Benefiting from the enhancements of MoCE in expert creation, dynamic expert group formation, and experts' collaboration, our model demonstrates superior performance over traditional methods on 24 MPP datasets, especially in tasks with limited data or high imbalance.
ADGym: Design Choices for Deep Anomaly Detection
Sep 27, 2023
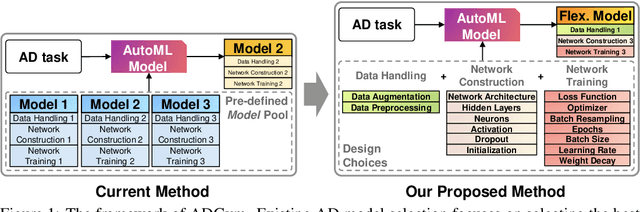


Deep learning (DL) techniques have recently been applied to anomaly detection (AD), yielding successful outcomes in areas such as finance, medical services, and cloud computing. However, much of the current research evaluates a deep AD algorithm holistically, failing to understand the contributions of individual design choices like loss functions and network architectures. Consequently, the importance of prerequisite steps, such as preprocessing, might be overshadowed by the spotlight on novel loss functions and architectures. In this paper, we address these oversights by posing two questions: (i) Which components (i.e., design choices) of deep AD methods are pivotal in detecting anomalies? (ii) How can we construct tailored AD algorithms for specific datasets by selecting the best design choices automatically, rather than relying on generic, pre-existing solutions? To this end, we introduce ADGym, the first platform designed for comprehensive evaluation and automatic selection of AD design elements in deep methods. Extensive experiments reveal that merely adopting existing leading methods is not ideal. Models crafted using ADGym markedly surpass current state-of-the-art techniques.
Anomaly Detection with Score Distribution Discrimination
Jun 26, 2023Recent studies give more attention to the anomaly detection (AD) methods that can leverage a handful of labeled anomalies along with abundant unlabeled data. These existing anomaly-informed AD methods rely on manually predefined score target(s), e.g., prior constant or margin hyperparameter(s), to realize discrimination in anomaly scores between normal and abnormal data. However, such methods would be vulnerable to the existence of anomaly contamination in the unlabeled data, and also lack adaptation to different data scenarios. In this paper, we propose to optimize the anomaly scoring function from the view of score distribution, thus better retaining the diversity and more fine-grained information of input data, especially when the unlabeled data contains anomaly noises in more practical AD scenarios. We design a novel loss function called Overlap loss that minimizes the overlap area between the score distributions of normal and abnormal samples, which no longer depends on prior anomaly score targets and thus acquires adaptability to various datasets. Overlap loss consists of Score Distribution Estimator and Overlap Area Calculation, which are introduced to overcome challenges when estimating arbitrary score distributions, and to ensure the boundness of training loss. As a general loss component, Overlap loss can be effectively integrated into multiple network architectures for constructing AD models. Extensive experimental results indicate that Overlap loss based AD models significantly outperform their state-of-the-art counterparts, and achieve better performance on different types of anomalies.
Weakly Supervised Anomaly Detection: A Survey
Feb 09, 2023Anomaly detection (AD) is a crucial task in machine learning with various applications, such as detecting emerging diseases, identifying financial frauds, and detecting fake news. However, obtaining complete, accurate, and precise labels for AD tasks can be expensive and challenging due to the cost and difficulties in data annotation. To address this issue, researchers have developed AD methods that can work with incomplete, inexact, and inaccurate supervision, collectively summarized as weakly supervised anomaly detection (WSAD) methods. In this study, we present the first comprehensive survey of WSAD methods by categorizing them into the above three weak supervision settings across four data modalities (i.e., tabular, graph, time-series, and image/video data). For each setting, we provide formal definitions, key algorithms, and potential future directions. To support future research, we conduct experiments on a selected setting and release the source code, along with a collection of WSAD methods and data.
GENIUS: Sketch-based Language Model Pre-training via Extreme and Selective Masking for Text Generation and Augmentation
Nov 18, 2022



We introduce GENIUS: a conditional text generation model using sketches as input, which can fill in the missing contexts for a given sketch (key information consisting of textual spans, phrases, or words, concatenated by mask tokens). GENIUS is pre-trained on a large-scale textual corpus with a novel reconstruction from sketch objective using an extreme and selective masking strategy, enabling it to generate diverse and high-quality texts given sketches. Comparison with other competitive conditional language models (CLMs) reveals the superiority of GENIUS's text generation quality. We further show that GENIUS can be used as a strong and ready-to-use data augmentation tool for various natural language processing (NLP) tasks. Most existing textual data augmentation methods are either too conservative, by making small changes to the original text, or too aggressive, by creating entirely new samples. With GENIUS, we propose GeniusAug, which first extracts the target-aware sketches from the original training set and then generates new samples based on the sketches. Empirical experiments on 6 text classification datasets show that GeniusAug significantly improves the models' performance in both in-distribution (ID) and out-of-distribution (OOD) settings. We also demonstrate the effectiveness of GeniusAug on named entity recognition (NER) and machine reading comprehension (MRC) tasks. (Code and models are publicly available at https://github.com/microsoft/SCGLab and https://github.com/beyondguo/genius)
IDEA: Interactive DoublE Attentions from Label Embedding for Text Classification
Sep 23, 2022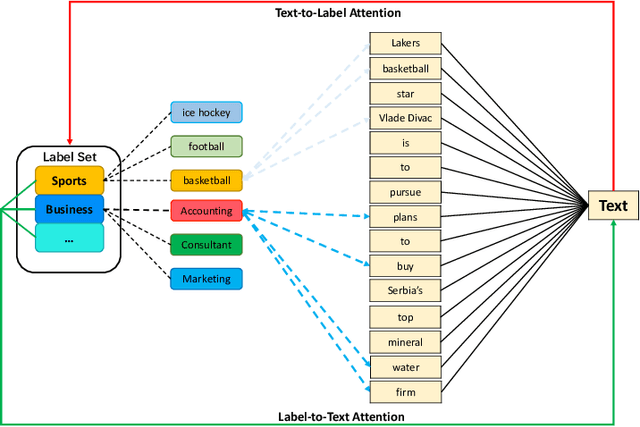
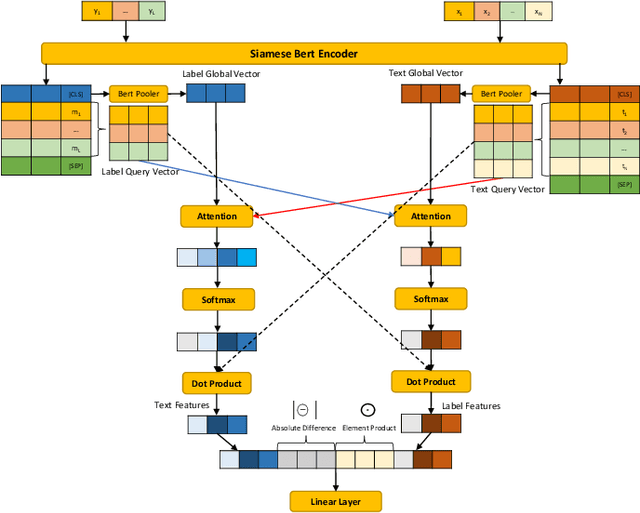
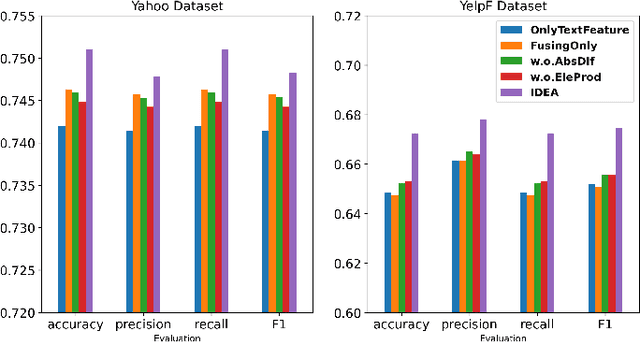
Current text classification methods typically encode the text merely into embedding before a naive or complicated classifier, which ignores the suggestive information contained in the label text. As a matter of fact, humans classify documents primarily based on the semantic meaning of the subcategories. We propose a novel model structure via siamese BERT and interactive double attentions named IDEA ( Interactive DoublE Attentions) to capture the information exchange of text and label names. Interactive double attentions enable the model to exploit the inter-class and intra-class information from coarse to fine, which involves distinguishing among all labels and matching the semantical subclasses of ground truth labels. Our proposed method outperforms the state-of-the-art methods using label texts significantly with more stable results.
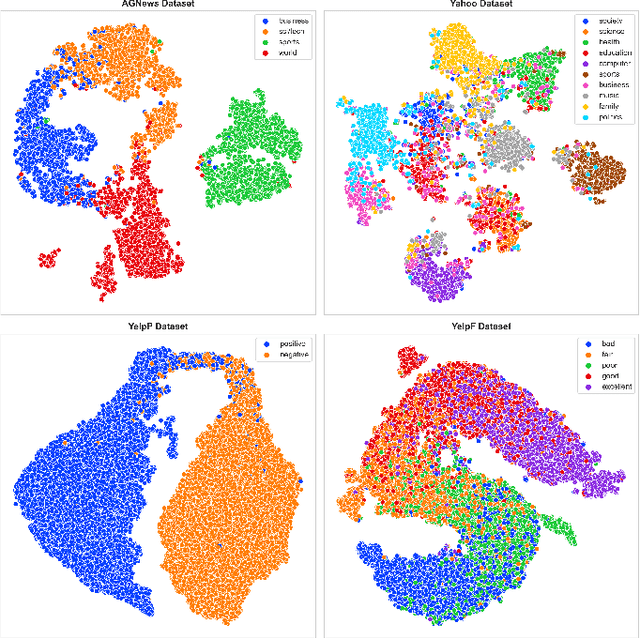
Selective Text Augmentation with Word Roles for Low-Resource Text Classification
Sep 04, 2022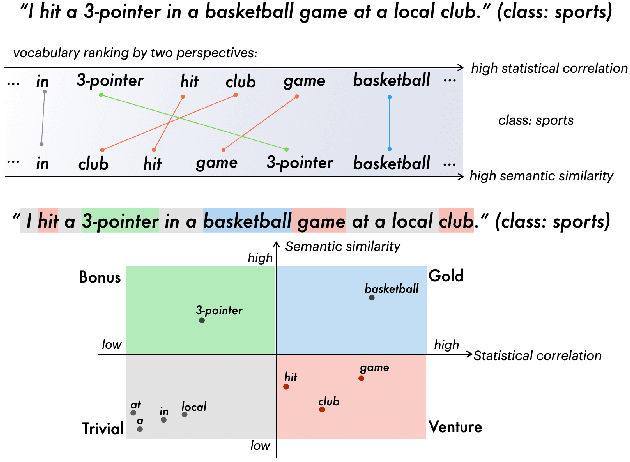

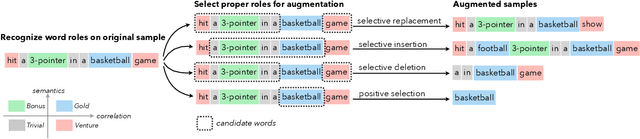
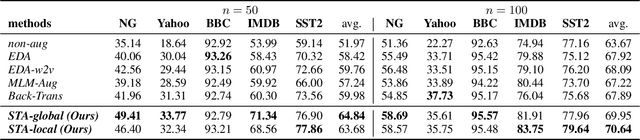
Data augmentation techniques are widely used in text classification tasks to improve the performance of classifiers, especially in low-resource scenarios. Most previous methods conduct text augmentation without considering the different functionalities of the words in the text, which may generate unsatisfactory samples. Different words may play different roles in text classification, which inspires us to strategically select the proper roles for text augmentation. In this work, we first identify the relationships between the words in a text and the text category from the perspectives of statistical correlation and semantic similarity and then utilize them to divide the words into four roles -- Gold, Venture, Bonus, and Trivial words, which have different functionalities for text classification. Based on these word roles, we present a new augmentation technique called STA (Selective Text Augmentation) where different text-editing operations are selectively applied to words with specific roles. STA can generate diverse and relatively clean samples, while preserving the original core semantics, and is also quite simple to implement. Extensive experiments on 5 benchmark low-resource text classification datasets illustrate that augmented samples produced by STA successfully boost the performance of classification models which significantly outperforms previous non-selective methods, including two large language model-based techniques. Cross-dataset experiments further indicate that STA can help the classifiers generalize better to other datasets than previous methods.
ADBench: Anomaly Detection Benchmark
Jun 19, 2022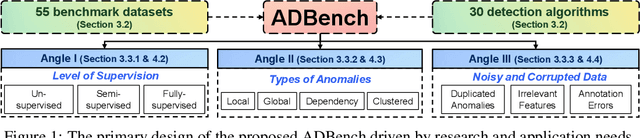

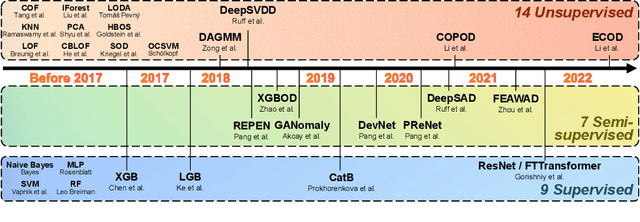
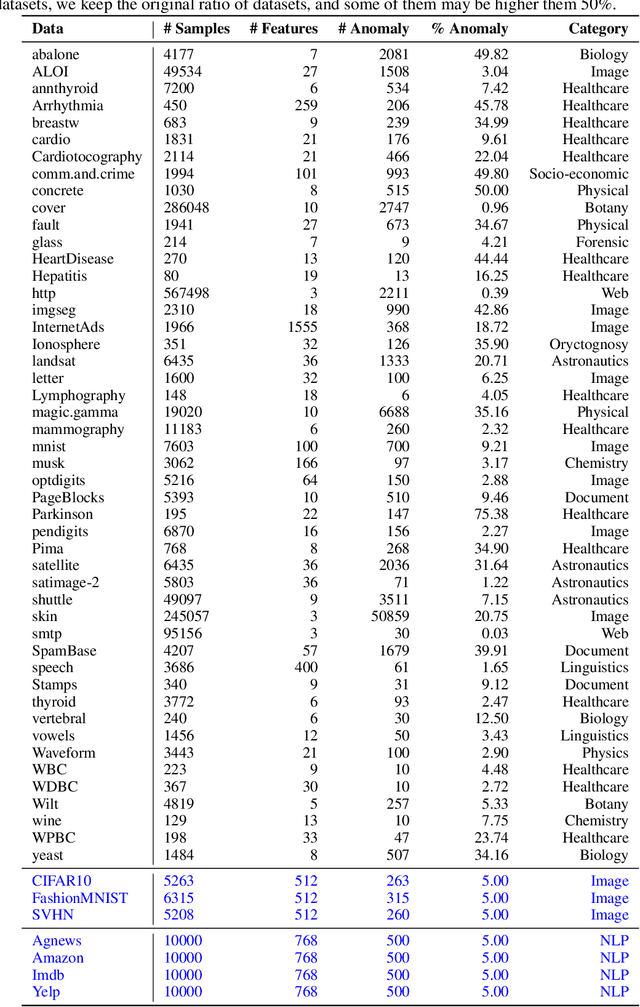
Given a long list of anomaly detection algorithms developed in the last few decades, how do they perform with regard to (i) varying levels of supervision, (ii) different types of anomalies, and (iii) noisy and corrupted data? In this work, we answer these key questions by conducting (to our best knowledge) the most comprehensive anomaly detection benchmark with 30 algorithms on 55 benchmark datasets, named ADBench. Our extensive experiments (93,654 in total) identify meaningful insights into the role of supervision and anomaly types, and unlock future directions for researchers in algorithm selection and design. With ADBench, researchers can easily conduct comprehensive and fair evaluations for newly proposed methods on the datasets (including our contributed ones from natural language and computer vision domains) against the existing baselines. To foster accessibility and reproducibility, we fully open-source ADBench and the corresponding results.
Neural News Recommendation with Event Extraction
Nov 09, 2021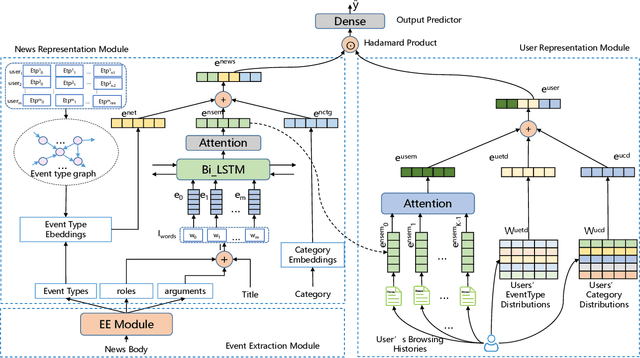

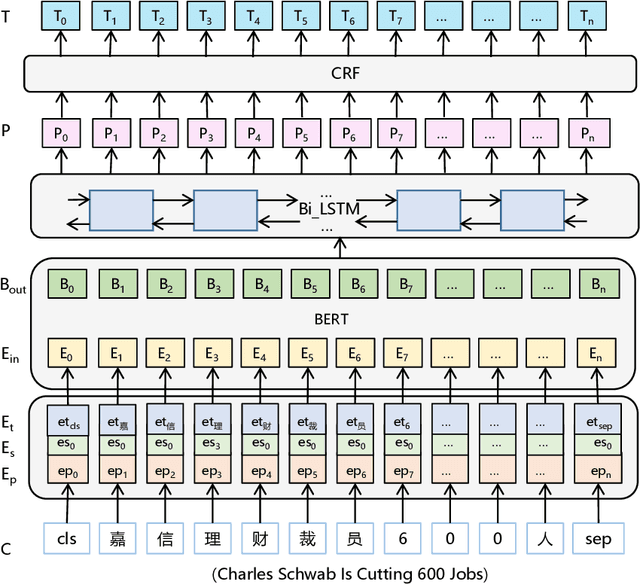
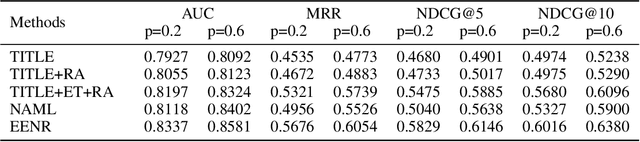
A key challenge of online news recommendation is to help users find articles they are interested in. Traditional news recommendation methods usually use single news information, which is insufficient to encode news and user representation. Recent research uses multiple channel news information, e.g., title, category, and body, to enhance news and user representation. However, these methods only use various attention mechanisms to fuse multi-view embeddings without considering deep digging higher-level information contained in the context. These methods encode news content on the word level and jointly train the attention parameters in the recommendation network, leading to more corpora being required to train the model. We propose an Event Extraction-based News Recommendation (EENR) framework to overcome these shortcomings, utilizing event extraction to abstract higher-level information. EENR also uses a two-stage strategy to reduce parameters in subsequent parts of the recommendation network. We train the Event Extraction module by external corpora in the first stage and apply the trained model to the news recommendation dataset to predict event-level information, including event types, roles, and arguments, in the second stage. Then we fuse multiple channel information, including event information, news title, and category, to encode news and users. Extensive experiments on a real-world dataset show that our EENR method can effectively improve the performance of news recommendations. Finally, we also explore the reasonability of utilizing higher abstract level information to substitute news body content.