 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Design Engineering: An Empirical Study of What Makes Good Downstream Fine-Tuning Samples for LLMs
Apr 19, 2024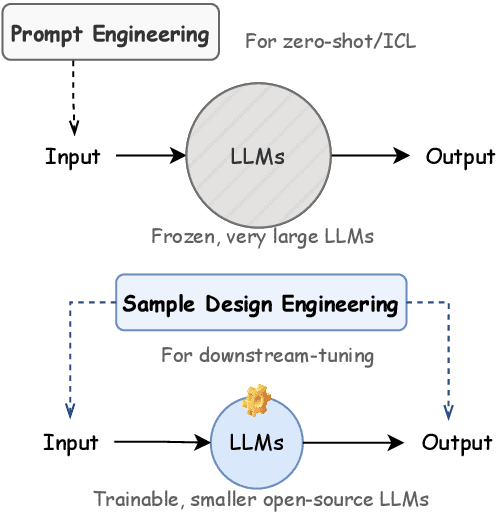
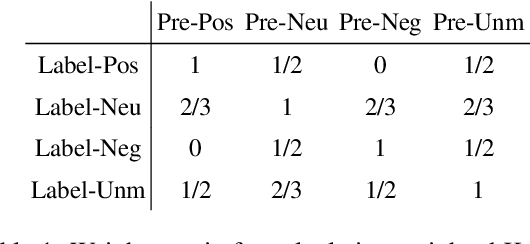
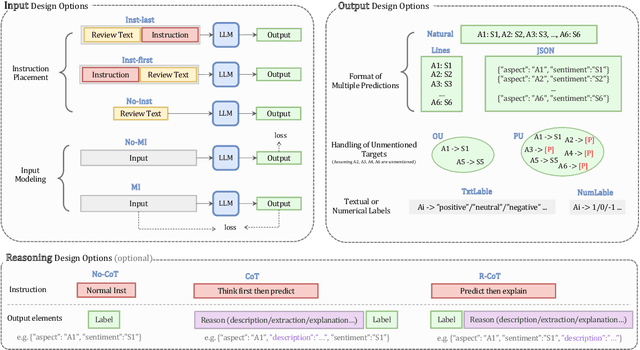
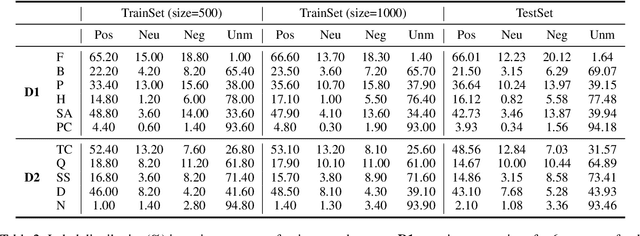
In the burgeoning field of Large Language Models (LLMs) like ChatGPT and LLaMA, Prompt Engineering (PE) is renowned for boosting zero-shot or in-context learning (ICL) through prompt modifications. Yet, the realm of the sample design for downstream fine-tuning, crucial for task-specific LLM adaptation, is largely unexplored. This paper introduces Sample Design Engineering (SDE), a methodical approach to enhancing LLMs' post-tuning performance by refining input, output, and reasoning designs. We conduct a series of in-domain (ID) and out-of-domain (OOD) experiments to assess the impact of various design options on LLMs' downstream performance, revealing several intriguing patterns that hold consistently across different LLMs. Based on these insights, we propose an integrated SDE strategy, combining the most effective options, and validate its consistent superiority over heuristic sample designs in complex downstream tasks like multi-aspect sentiment analysis, event extraction, and nested entity recognition. Additionally, analyses of LLMs' inherent prompt/output perplexity, zero-shot, and ICL abilities illustrate that good PE strategies may not always translate to good SDE strategies. Code available at https://github.com/beyondguo/LLM-Tuning.