 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Design Engineering: An Empirical Study of What Makes Good Downstream Fine-Tuning Samples for LLMs
Apr 19, 2024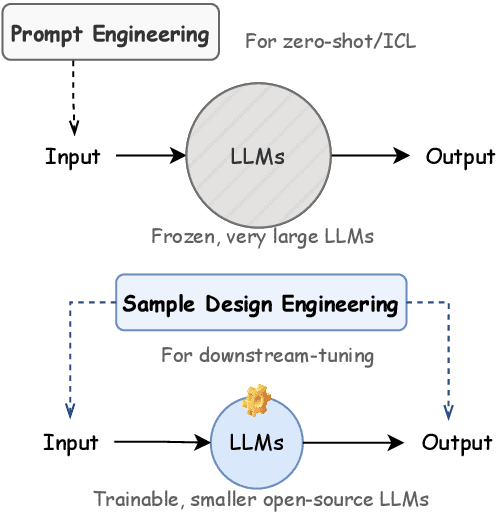
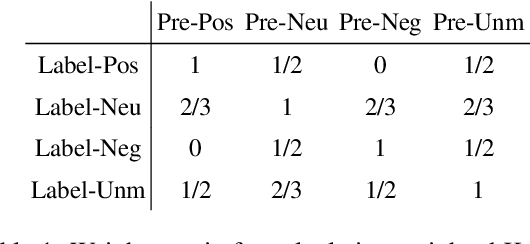
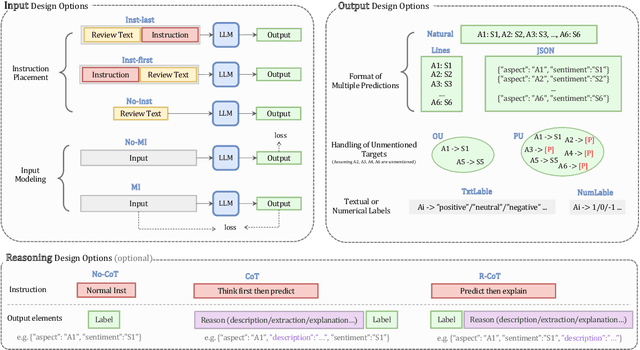
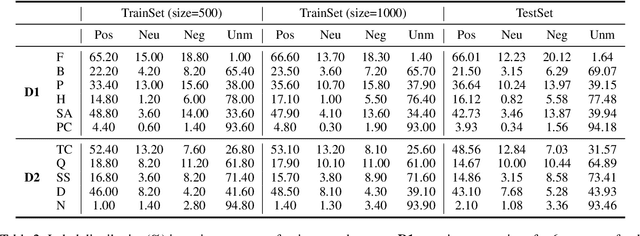
In the burgeoning field of Large Language Models (LLMs) like ChatGPT and LLaMA, Prompt Engineering (PE) is renowned for boosting zero-shot or in-context learning (ICL) through prompt modifications. Yet, the realm of the sample design for downstream fine-tuning, crucial for task-specific LLM adaptation, is largely unexplored. This paper introduces Sample Design Engineering (SDE), a methodical approach to enhancing LLMs' post-tuning performance by refining input, output, and reasoning designs. We conduct a series of in-domain (ID) and out-of-domain (OOD) experiments to assess the impact of various design options on LLMs' downstream performance, revealing several intriguing patterns that hold consistently across different LLMs. Based on these insights, we propose an integrated SDE strategy, combining the most effective options, and validate its consistent superiority over heuristic sample designs in complex downstream tasks like multi-aspect sentiment analysis, event extraction, and nested entity recognition. Additionally, analyses of LLMs' inherent prompt/output perplexity, zero-shot, and ICL abilities illustrate that good PE strategies may not always translate to good SDE strategies. Code available at https://github.com/beyondguo/LLM-Tuning.
How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection
Jan 18, 2023The introduction of ChatGPT has garnered widespread attention in both academic and industrial communities. ChatGPT is able to respond effectively to a wide range of human questions, providing fluent and comprehensive answers that significantly surpass previous public chatbots in terms of security and usefulness. On one hand, people are curious about how ChatGPT is able to achieve such strength and how far it is from human experts. On the other hand, people are starting to worry about the potential negative impacts that large language models (LLMs) like ChatGPT could have on society, such as fake news, plagiarism, and social security issues. In this work, we collected tens of thousands of comparison responses from both human experts and ChatGPT, with questions ranging from open-domain, financial, medical, legal, and psychological areas. We call the collected dataset the Human ChatGPT Comparison Corpus (HC3). Based on the HC3 dataset, we study the characteristics of ChatGPT's responses, the differences and gaps from human experts, and future directions for LLMs. We conducted comprehensive human evaluations and linguistic analyses of ChatGPT-generated content compared with that of humans, where many interesting results are revealed. After that, we conduct extensive experiments on how to effectively detect whether a certain text is generated by ChatGPT or humans. We build three different detection systems, explore several key factors that influence their effectiveness, and evaluate them in different scenarios. The dataset, code, and models are all publicly available at https://github.com/Hello-SimpleAI/chatgpt-comparison-detection.
GENIUS: Sketch-based Language Model Pre-training via Extreme and Selective Masking for Text Generation and Augmentation
Nov 18, 2022



We introduce GENIUS: a conditional text generation model using sketches as input, which can fill in the missing contexts for a given sketch (key information consisting of textual spans, phrases, or words, concatenated by mask tokens). GENIUS is pre-trained on a large-scale textual corpus with a novel reconstruction from sketch objective using an extreme and selective masking strategy, enabling it to generate diverse and high-quality texts given sketches. Comparison with other competitive conditional language models (CLMs) reveals the superiority of GENIUS's text generation quality. We further show that GENIUS can be used as a strong and ready-to-use data augmentation tool for various natural language processing (NLP) tasks. Most existing textual data augmentation methods are either too conservative, by making small changes to the original text, or too aggressive, by creating entirely new samples. With GENIUS, we propose GeniusAug, which first extracts the target-aware sketches from the original training set and then generates new samples based on the sketches. Empirical experiments on 6 text classification datasets show that GeniusAug significantly improves the models' performance in both in-distribution (ID) and out-of-distribution (OOD) settings. We also demonstrate the effectiveness of GeniusAug on named entity recognition (NER) and machine reading comprehension (MRC) tasks. (Code and models are publicly available at https://github.com/microsoft/SCGLab and https://github.com/beyondguo/genius)
Selective Text Augmentation with Word Roles for Low-Resource Text Classification
Sep 04, 2022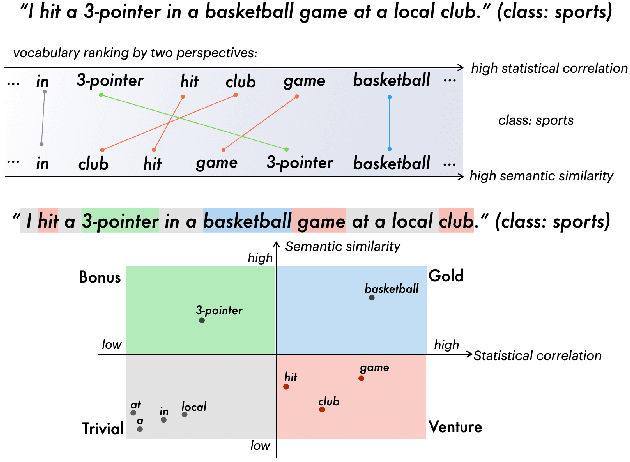

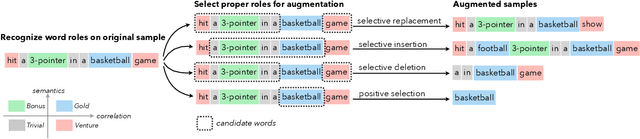
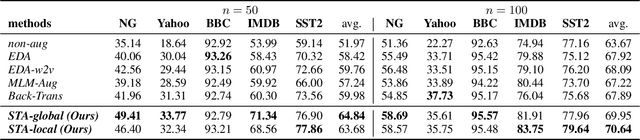
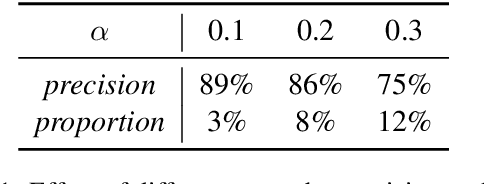
Data augmentation techniques are widely used in text classification tasks to improve the performance of classifiers, especially in low-resource scenarios. Most previous methods conduct text augmentation without considering the different functionalities of the words in the text, which may generate unsatisfactory samples. Different words may play different roles in text classification, which inspires us to strategically select the proper roles for text augmentation. In this work, we first identify the relationships between the words in a text and the text category from the perspectives of statistical correlation and semantic similarity and then utilize them to divide the words into four roles -- Gold, Venture, Bonus, and Trivial words, which have different functionalities for text classification. Based on these word roles, we present a new augmentation technique called STA (Selective Text Augmentation) where different text-editing operations are selectively applied to words with specific roles. STA can generate diverse and relatively clean samples, while preserving the original core semantics, and is also quite simple to implement. Extensive experiments on 5 benchmark low-resource text classification datasets illustrate that augmented samples produced by STA successfully boost the performance of classification models which significantly outperforms previous non-selective methods, including two large language model-based techniques. Cross-dataset experiments further indicate that STA can help the classifiers generalize better to other datasets than previous methods.
What Have Been Learned & What Should Be Learned? An Empirical Study of How to Selectively Augment Text for Classification
Sep 01, 2021
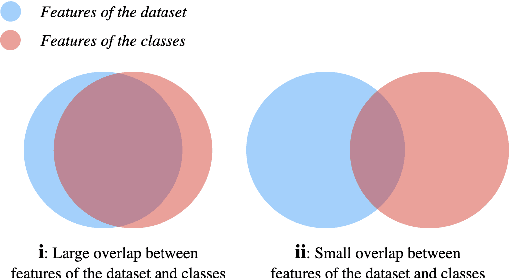
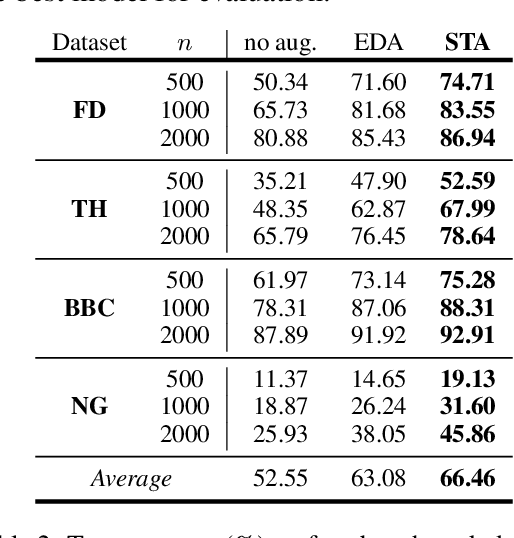
Text augmentation techniques are widely used in text classification problems to improve the performance of classifiers, especially in low-resource scenarios. Whilst lots of creative text augmentation methods have been designed, they augment the text in a non-selective manner, which means the less important or noisy words have the same chances to be augmented as the informative words, and thereby limits the performance of augmentation. In this work, we systematically summarize three kinds of role keywords, which have different functions for text classification, and design effective methods to extract them from the text. Based on these extracted role keywords, we propose STA (Selective Text Augmentation) to selectively augment the text, where the informative, class-indicating words are emphasized but the irrelevant or noisy words are diminished. Extensive experiments on four English and Chinese text classification benchmark datasets demonstrate that STA can substantially outperform the non-selective text augmentation methods.
Label Confusion Learning to Enhance Text Classification Models
Dec 09, 2020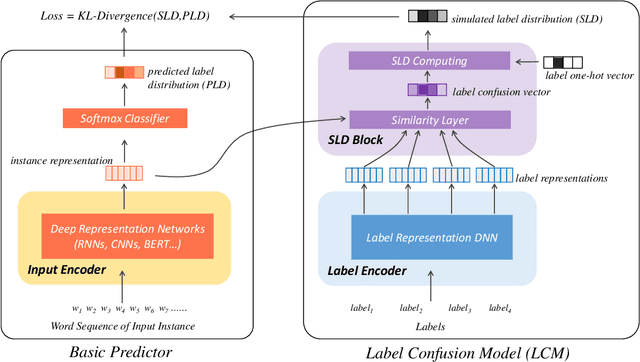

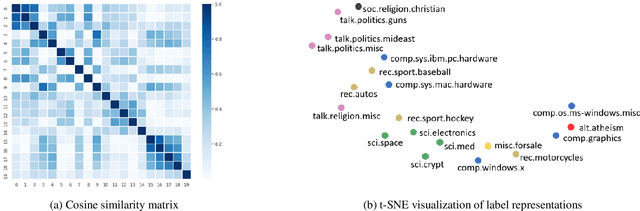
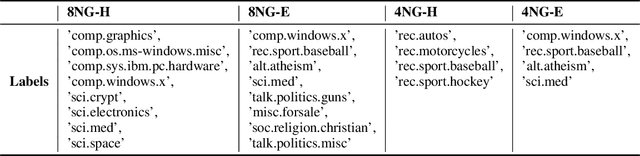
Representing a true label as a one-hot vector is a common practice in training text classification models. However, the one-hot representation may not adequately reflect the relation between the instances and labels, as labels are often not completely independent and instances may relate to multiple labels in practice. The inadequate one-hot representations tend to train the model to be over-confident, which may result in arbitrary prediction and model overfitting, especially for confused datasets (datasets with very similar labels) or noisy datasets (datasets with labeling errors). While training models with label smoothing (LS) can ease this problem in some degree, it still fails to capture the realistic relation among labels. In this paper, we propose a novel Label Confusion Model (LCM) as an enhancement component to current popular text classification models. LCM can learn label confusion to capture semantic overlap among labels by calculating the similarity between instances and labels during training and generate a better label distribution to replace the original one-hot label vector, thus improving the final classification performance. Extensive experiments on five text classification benchmark datasets reveal the effectiveness of LCM for several widely used deep learning classification models. Further experiments also verify that LCM is especially helpful for confused or noisy datasets and superior to the label smoothing method.