 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeanCache: From Instantaneous to Average Velocity for Accelerating Flow Matching Inference
Jan 27, 2026We present MeanCache, a training-free caching framework for efficient Flow Matching inference. Existing caching methods reduce redundant computation but typically rely on instantaneous velocity information (e.g., feature caching), which often leads to severe trajectory deviations and error accumulation under high acceleration ratios. MeanCache introduces an average-velocity perspective: by leveraging cached Jacobian--vector products (JVP) to construct interval average velocities from instantaneous velocities, it effectively mitigates local error accumulation. To further improve cache timing and JVP reuse stability, we develop a trajectory-stability scheduling strategy as a practical tool, employing a Peak-Suppressed Shortest Path under budget constraints to determine the schedule. Experiments on FLUX.1, Qwen-Image, and HunyuanVideo demonstrate that MeanCache achieves 4.12X and 4.56X and 3.59X acceleration, respectively, while consistently outperforming state-of-the-art caching baselines in generation quality. We believe this simple yet effective approach provides a new perspective for Flow Matching inference and will inspire further exploration of stability-driven acceleration in commercial-scale generative models.
HiMo-CLIP: Modeling Semantic Hierarchy and Monotonicity in Vision-Language Alignment
Nov 10, 2025Contrastive vision-language models like CLIP have achieved impressive results in image-text retrieval by aligning image and text representations in a shared embedding space. However, these models often treat text as flat sequences, limiting their ability to handle complex, compositional, and long-form descriptions. In particular, they fail to capture two essential properties of language: semantic hierarchy, which reflects the multi-level compositional structure of text, and semantic monotonicity, where richer descriptions should result in stronger alignment with visual content.To address these limitations, we propose HiMo-CLIP, a representation-level framework that enhances CLIP-style models without modifying the encoder architecture. HiMo-CLIP introduces two key components: a hierarchical decomposition (HiDe) module that extracts latent semantic components from long-form text via in-batch PCA, enabling flexible, batch-aware alignment across different semantic granularities, and a monotonicity-aware contrastive loss (MoLo) that jointly aligns global and component-level representations, encouraging the model to internalize semantic ordering and alignment strength as a function of textual completeness.These components work in concert to produce structured, cognitively-aligned cross-modal representations. Experiments on multiple image-text retrieval benchmarks show that HiMo-CLIP consistently outperforms strong baselines, particularly under long or compositional descriptions. The code is available at https://github.com/UnicomAI/HiMo-CLIP.
* Accepted by AAAI 2026 as an Oral Presentation (13 pages, 7 figures, 7 tables)
An Efficient End-to-End 3D Model Reconstruction based on Neural Architecture Search
Mar 01, 2022
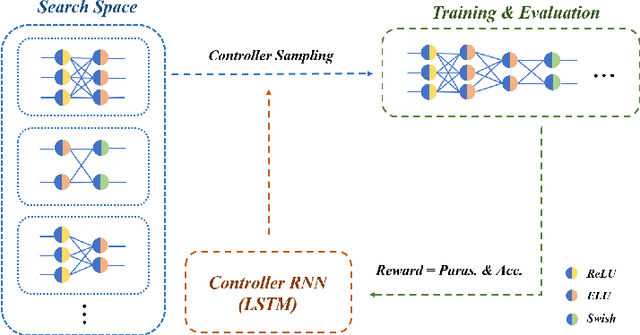
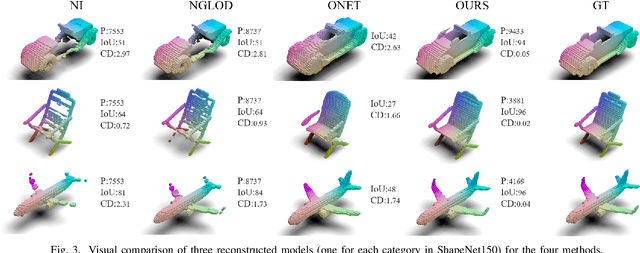
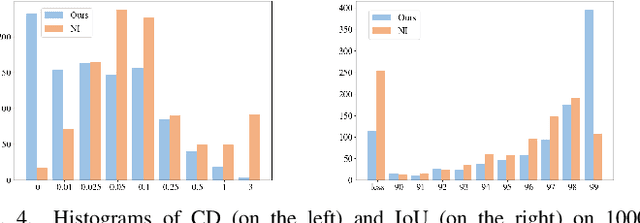
Using neural networks to represent 3D objects has become popular. However, many previous works employ neural networks with fixed architecture and size to represent different 3D objects, which lead to excessive network parameters for simple objects and limited reconstruction accuracy for complex objects. For each 3D model, it is desirable to have an end-to-end neural network with as few parameters as possible to achieve high-fidelity reconstruction. In this paper, we propose an efficient model reconstruction method utilizing neural architecture search (NAS) and binary classification. Taking the number of layers, the number of nodes in each layer, and the activation function of each layer as the search space, a specific network architecture can be obtained based on reinforcement learning technology. Furthermore, to get rid of the traditional surface reconstruction algorithms (e.g., marching cube) used after network inference, we complete the end-to-end network by classifying binary voxels. Compared to other signed distance field (SDF) prediction or binary classification networks, our method achieves significantly higher reconstruction accuracy using fewer network parameters.
Label Confusion Learning to Enhance Text Classification Models
Dec 09, 2020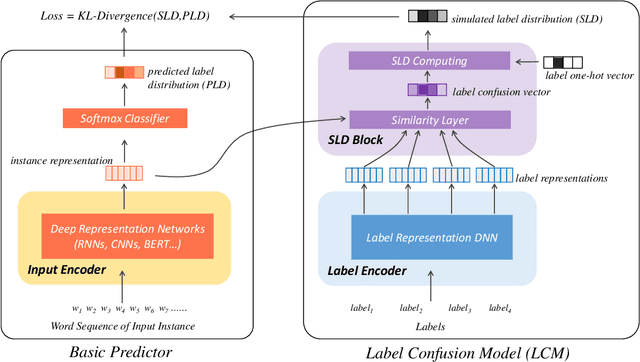

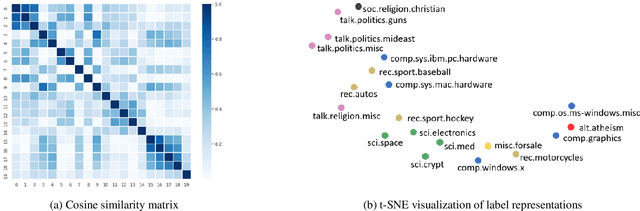
Representing a true label as a one-hot vector is a common practice in training text classification models. However, the one-hot representation may not adequately reflect the relation between the instances and labels, as labels are often not completely independent and instances may relate to multiple labels in practice. The inadequate one-hot representations tend to train the model to be over-confident, which may result in arbitrary prediction and model overfitting, especially for confused datasets (datasets with very similar labels) or noisy datasets (datasets with labeling errors). While training models with label smoothing (LS) can ease this problem in some degree, it still fails to capture the realistic relation among labels. In this paper, we propose a novel Label Confusion Model (LCM) as an enhancement component to current popular text classification models. LCM can learn label confusion to capture semantic overlap among labels by calculating the similarity between instances and labels during training and generate a better label distribution to replace the original one-hot label vector, thus improving the final classification performance. Extensive experiments on five text classification benchmark datasets reveal the effectiveness of LCM for several widely used deep learning classification models. Further experiments also verify that LCM is especially helpful for confused or noisy datasets and superior to the label smoothing method.