 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyntactic-GCN Bert based Chinese Event Extraction
Dec 18, 2021
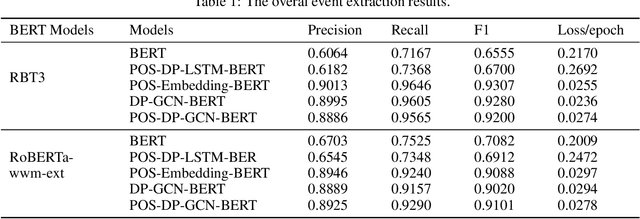

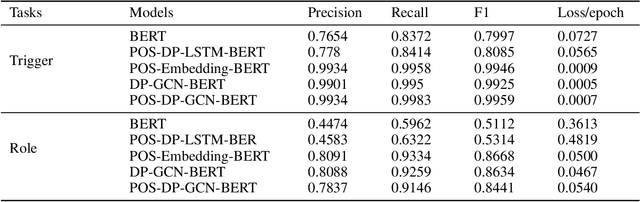
With the rapid development of information technology, online platforms (e.g., news portals and social media) generate enormous web information every moment. Therefore, it is crucial to extract structured representations of events from social streams. Generally, existing event extraction research utilizes pattern matching, machine learning, or deep learning methods to perform event extraction tasks. However, the performance of Chinese event extraction is not as good as English due to the unique characteristics of the Chinese language. In this paper, we propose an integrated framework to perform Chinese event extraction. The proposed approach is a multiple channel input neural framework that integrates semantic features and syntactic features. The semantic features are captured by BERT architecture. The Part of Speech (POS) features and Dependency Parsing (DP) features are captured by profiling embeddings and Graph Convolutional Network (GCN), respectively. We also evaluate our model on a real-world dataset. Experimental results show that the proposed method outperforms the benchmark approaches significantly.
Forecasting Crude Oil Price Using Event Extraction
Nov 14, 2021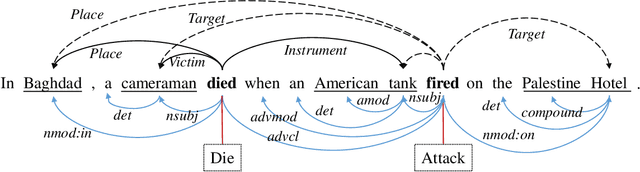
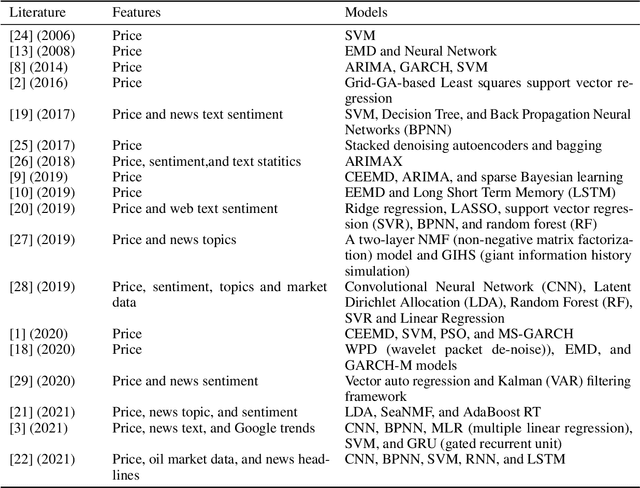
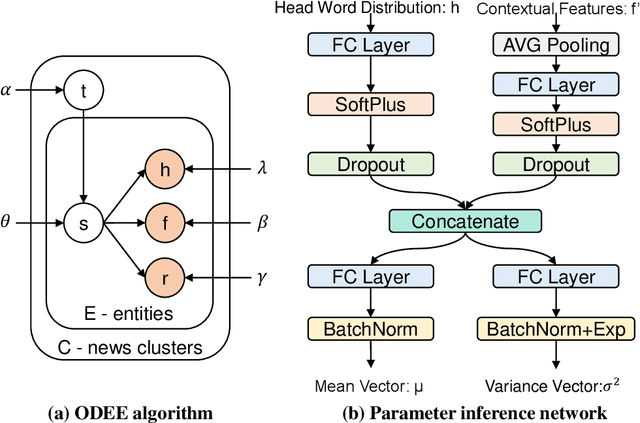

Research on crude oil price forecasting has attracted tremendous attention from scholars and policymakers due to its significant effect on the global economy. Besides supply and demand, crude oil prices are largely influenced by various factors, such as economic development, financial markets, conflicts, wars, and political events. Most previous research treats crude oil price forecasting as a time series or econometric variable prediction problem. Although recently there have been researches considering the effects of real-time news events, most of these works mainly use raw news headlines or topic models to extract text features without profoundly exploring the event information. In this study, a novel crude oil price forecasting framework, AGESL, is proposed to deal with this problem. In our approach, an open domain event extraction algorithm is utilized to extract underlying related events, and a text sentiment analysis algorithm is used to extract sentiment from massive news. Then a deep neural network integrating the news event features, sentimental features, and historical price features is built to predict future crude oil prices. Empirical experiments are performed on West Texas Intermediate (WTI) crude oil price data, and the results show that our approach obtains superior performance compared with several benchmark methods.
* 14 pages, 5 figures, 5 tables
Neural News Recommendation with Event Extraction
Nov 09, 2021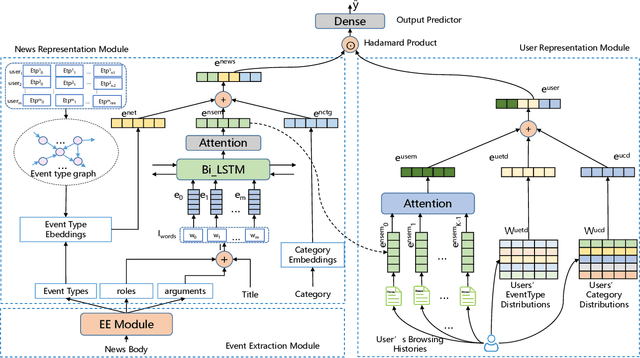

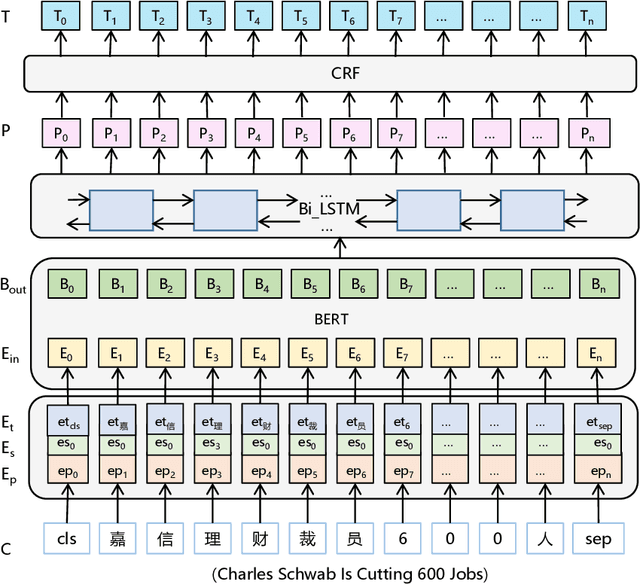
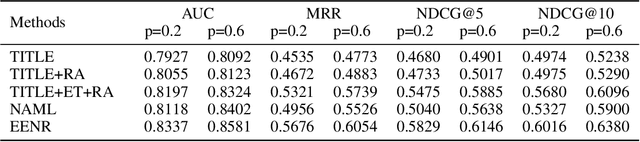
A key challenge of online news recommendation is to help users find articles they are interested in. Traditional news recommendation methods usually use single news information, which is insufficient to encode news and user representation. Recent research uses multiple channel news information, e.g., title, category, and body, to enhance news and user representation. However, these methods only use various attention mechanisms to fuse multi-view embeddings without considering deep digging higher-level information contained in the context. These methods encode news content on the word level and jointly train the attention parameters in the recommendation network, leading to more corpora being required to train the model. We propose an Event Extraction-based News Recommendation (EENR) framework to overcome these shortcomings, utilizing event extraction to abstract higher-level information. EENR also uses a two-stage strategy to reduce parameters in subsequent parts of the recommendation network. We train the Event Extraction module by external corpora in the first stage and apply the trained model to the news recommendation dataset to predict event-level information, including event types, roles, and arguments, in the second stage. Then we fuse multiple channel information, including event information, news title, and category, to encode news and users. Extensive experiments on a real-world dataset show that our EENR method can effectively improve the performance of news recommendations. Finally, we also explore the reasonability of utilizing higher abstract level information to substitute news body content.
American Hate Crime Trends Prediction with Event Extraction
Nov 09, 2021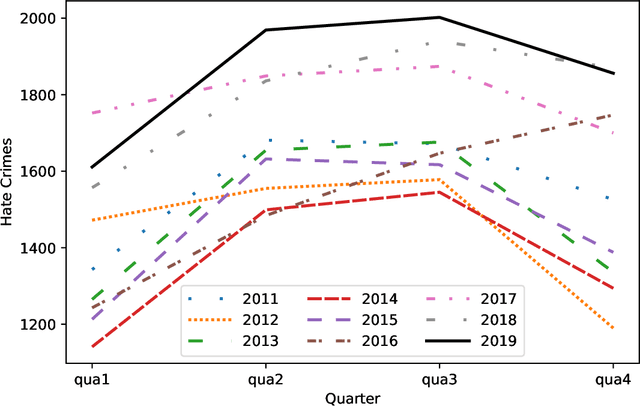
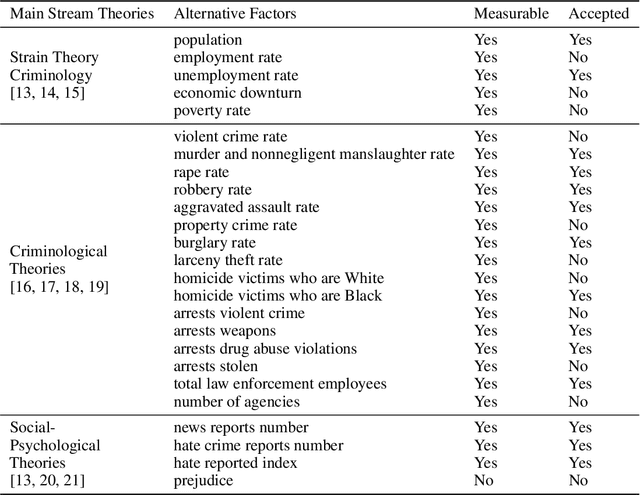
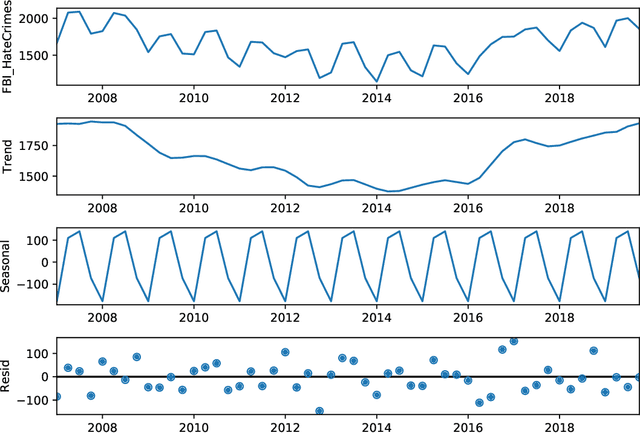

Social media platforms may provide potential space for discourses that contain hate speech, and even worse, can act as a propagation mechanism for hate crimes. The FBI's Uniform Crime Reporting (UCR) Program collects hate crime data and releases statistic report yearly. These statistics provide information in determining national hate crime trends. The statistics can also provide valuable holistic and strategic insight for law enforcement agencies or justify lawmakers for specific legislation. However, the reports are mostly released next year and lag behind many immediate needs. Recent research mainly focuses on hate speech detection in social media text or empirical studies on the impact of a confirmed crime. This paper proposes a framework that first utilizes text mining techniques to extract hate crime events from New York Times news, then uses the results to facilitate predicting American national-level and state-level hate crime trends. Experimental results show that our method can significantly enhance the prediction performance compared with time series or regression methods without event-related factors. Our framework broadens the methods of national-level and state-level hate crime trends prediction.
An overview of event extraction and its applications
Nov 05, 2021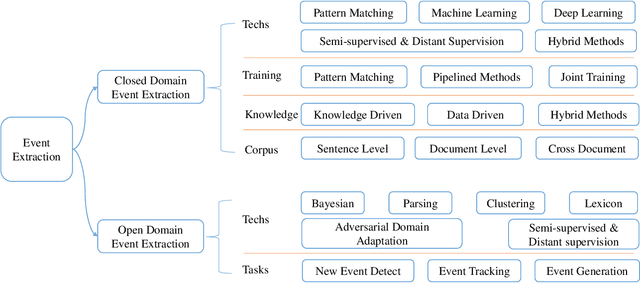
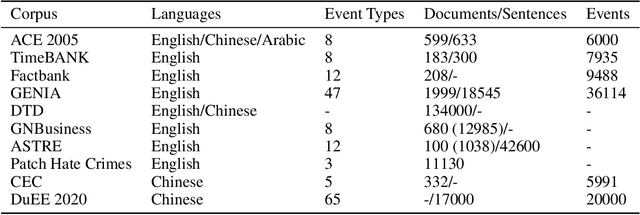

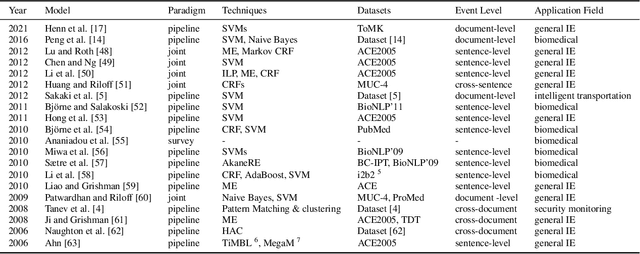
With the rapid development of information technology, online platforms have produced enormous text resources. As a particular form of Information Extraction (IE), Event Extraction (EE) has gained increasing popularity due to its ability to automatically extract events from human language. However, there are limited literature surveys on event extraction. Existing review works either spend much effort describing the details of various approaches or focus on a particular field. This study provides a comprehensive overview of the state-of-the-art event extraction methods and their applications from text, including closed-domain and open-domain event extraction. A trait of this survey is that it provides an overview in moderate complexity, avoiding involving too many details of particular approaches. This study focuses on discussing the common characters, application fields, advantages, and disadvantages of representative works, ignoring the specificities of individual approaches. Finally, we summarize the common issues, current solutions, and future research directions. We hope this work could help researchers and practitioners obtain a quick overview of recent event extraction.