 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-based Anti-UAV Detection and Tracking
May 22, 2022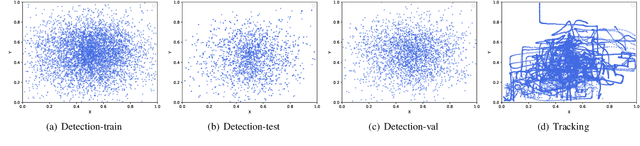


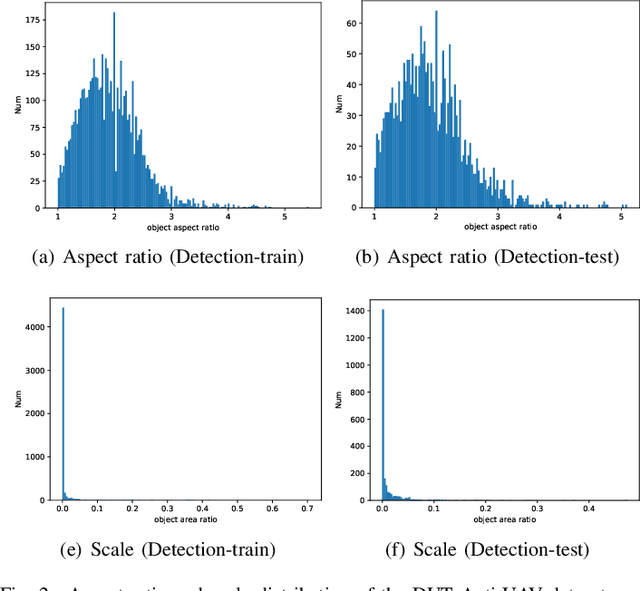
Unmanned aerial vehicles (UAV) have been widely used in various fields, and their invasion of security and privacy has aroused social concern. Several detection and tracking systems for UAVs have been introduced in recent years, but most of them are based on radio frequency, radar, and other media. We assume that the field of computer vision is mature enough to detect and track invading UAVs. Thus we propose a visible light mode dataset called Dalian University of Technology Anti-UAV dataset, DUT Anti-UAV for short. It contains a detection dataset with a total of 10,000 images and a tracking dataset with 20 videos that include short-term and long-term sequences. All frames and images are manually annotated precisely. We use this dataset to train several existing detection algorithms and evaluate the algorithms' performance. Several tracking methods are also tested on our tracking dataset. Furthermore, we propose a clear and simple tracking algorithm combined with detection that inherits the detector's high precision. Extensive experiments show that the tracking performance is improved considerably after fusing detection, thus providing a new attempt at UAV tracking using our dataset.The datasets and results are publicly available at: https://github.com/wangdongdut/DUT-Anti-UAV
Syntactic-GCN Bert based Chinese Event Extraction
Dec 18, 2021
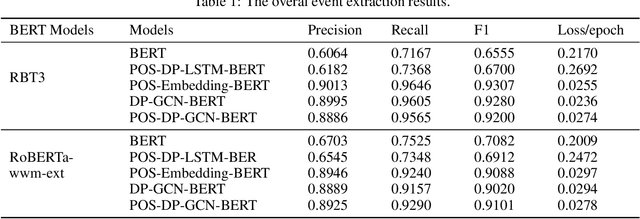

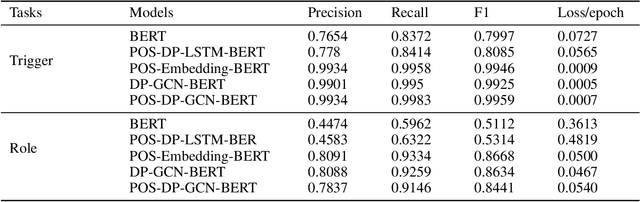
With the rapid development of information technology, online platforms (e.g., news portals and social media) generate enormous web information every moment. Therefore, it is crucial to extract structured representations of events from social streams. Generally, existing event extraction research utilizes pattern matching, machine learning, or deep learning methods to perform event extraction tasks. However, the performance of Chinese event extraction is not as good as English due to the unique characteristics of the Chinese language. In this paper, we propose an integrated framework to perform Chinese event extraction. The proposed approach is a multiple channel input neural framework that integrates semantic features and syntactic features. The semantic features are captured by BERT architecture. The Part of Speech (POS) features and Dependency Parsing (DP) features are captured by profiling embeddings and Graph Convolutional Network (GCN), respectively. We also evaluate our model on a real-world dataset. Experimental results show that the proposed method outperforms the benchmark approaches significantly.