 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDEA: Interactive DoublE Attentions from Label Embedding for Text Classification
Paper and Code
Sep 23, 2022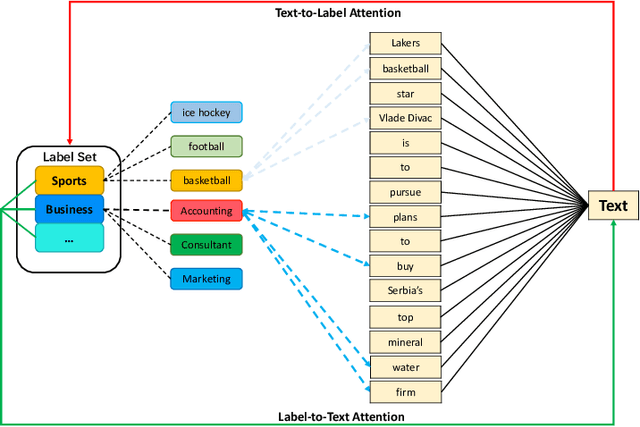
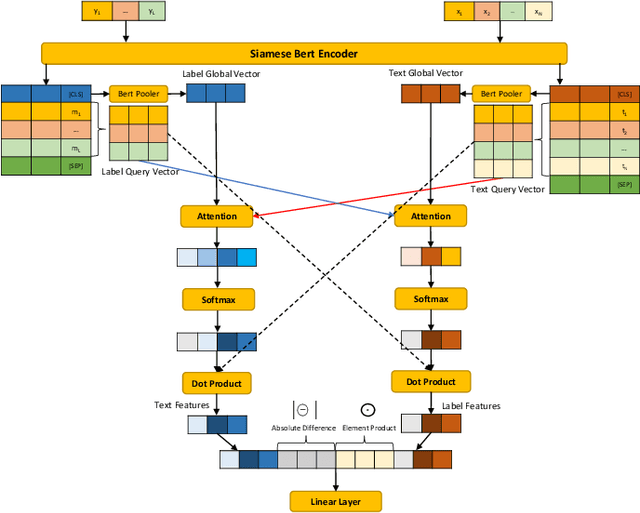
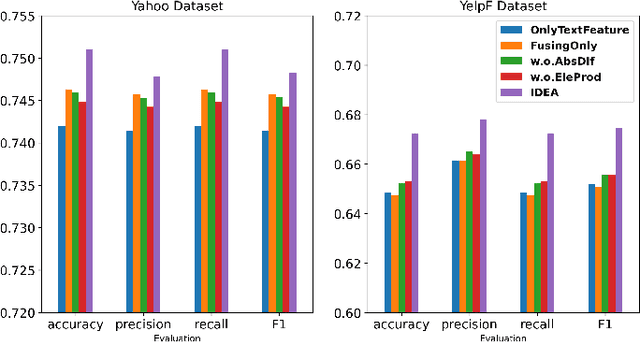
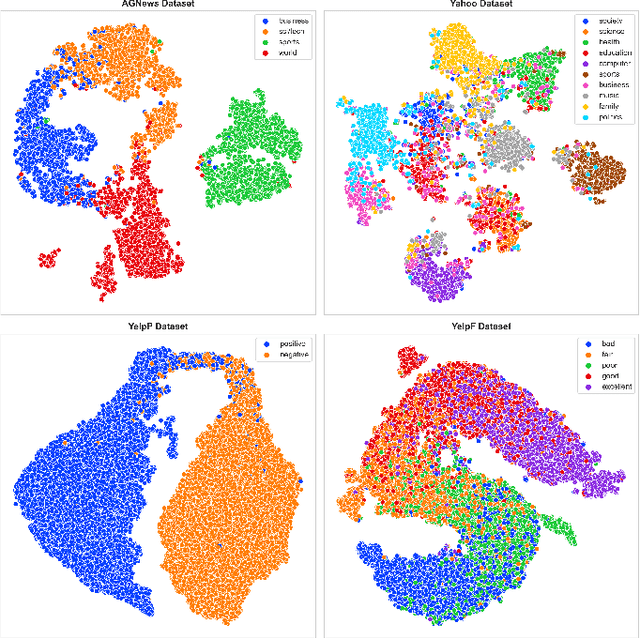
Current text classification methods typically encode the text merely into embedding before a naive or complicated classifier, which ignores the suggestive information contained in the label text. As a matter of fact, humans classify documents primarily based on the semantic meaning of the subcategories. We propose a novel model structure via siamese BERT and interactive double attentions named IDEA ( Interactive DoublE Attentions) to capture the information exchange of text and label names. Interactive double attentions enable the model to exploit the inter-class and intra-class information from coarse to fine, which involves distinguishing among all labels and matching the semantical subclasses of ground truth labels. Our proposed method outperforms the state-of-the-art methods using label texts significantly with more stable results.