 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADGym: Design Choices for Deep Anomaly Detection
Sep 27, 2023
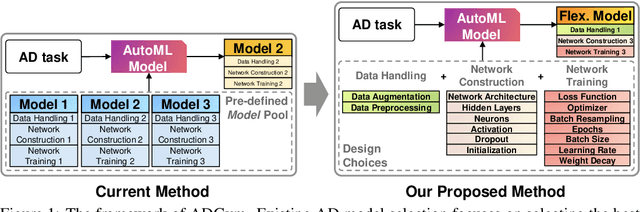


Deep learning (DL) techniques have recently been applied to anomaly detection (AD), yielding successful outcomes in areas such as finance, medical services, and cloud computing. However, much of the current research evaluates a deep AD algorithm holistically, failing to understand the contributions of individual design choices like loss functions and network architectures. Consequently, the importance of prerequisite steps, such as preprocessing, might be overshadowed by the spotlight on novel loss functions and architectures. In this paper, we address these oversights by posing two questions: (i) Which components (i.e., design choices) of deep AD methods are pivotal in detecting anomalies? (ii) How can we construct tailored AD algorithms for specific datasets by selecting the best design choices automatically, rather than relying on generic, pre-existing solutions? To this end, we introduce ADGym, the first platform designed for comprehensive evaluation and automatic selection of AD design elements in deep methods. Extensive experiments reveal that merely adopting existing leading methods is not ideal. Models crafted using ADGym markedly surpass current state-of-the-art techniques.
Weakly Supervised Anomaly Detection: A Survey
Feb 09, 2023Anomaly detection (AD) is a crucial task in machine learning with various applications, such as detecting emerging diseases, identifying financial frauds, and detecting fake news. However, obtaining complete, accurate, and precise labels for AD tasks can be expensive and challenging due to the cost and difficulties in data annotation. To address this issue, researchers have developed AD methods that can work with incomplete, inexact, and inaccurate supervision, collectively summarized as weakly supervised anomaly detection (WSAD) methods. In this study, we present the first comprehensive survey of WSAD methods by categorizing them into the above three weak supervision settings across four data modalities (i.e., tabular, graph, time-series, and image/video data). For each setting, we provide formal definitions, key algorithms, and potential future directions. To support future research, we conduct experiments on a selected setting and release the source code, along with a collection of WSAD methods and data.