 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADGym: Design Choices for Deep Anomaly Detection
Sep 27, 2023
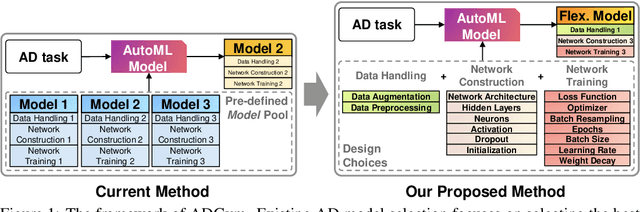


Deep learning (DL) techniques have recently been applied to anomaly detection (AD), yielding successful outcomes in areas such as finance, medical services, and cloud computing. However, much of the current research evaluates a deep AD algorithm holistically, failing to understand the contributions of individual design choices like loss functions and network architectures. Consequently, the importance of prerequisite steps, such as preprocessing, might be overshadowed by the spotlight on novel loss functions and architectures. In this paper, we address these oversights by posing two questions: (i) Which components (i.e., design choices) of deep AD methods are pivotal in detecting anomalies? (ii) How can we construct tailored AD algorithms for specific datasets by selecting the best design choices automatically, rather than relying on generic, pre-existing solutions? To this end, we introduce ADGym, the first platform designed for comprehensive evaluation and automatic selection of AD design elements in deep methods. Extensive experiments reveal that merely adopting existing leading methods is not ideal. Models crafted using ADGym markedly surpass current state-of-the-art techniques.
Weakly Supervised Anomaly Detection: A Survey
Feb 09, 2023
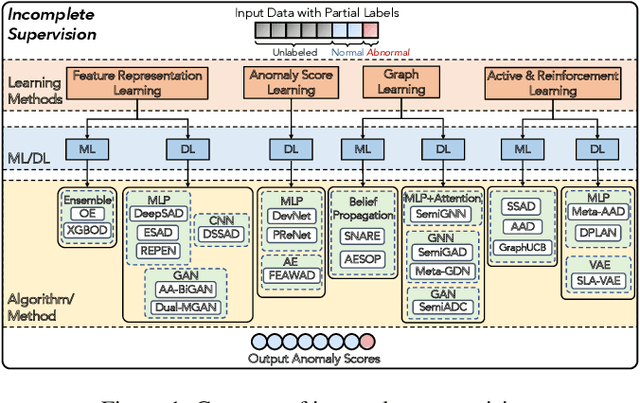
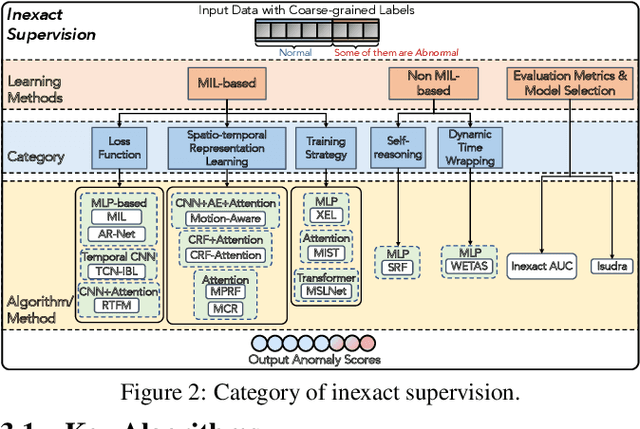
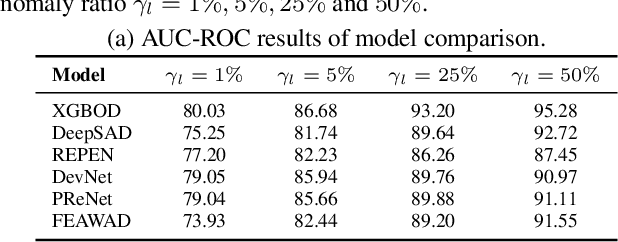
Anomaly detection (AD) is a crucial task in machine learning with various applications, such as detecting emerging diseases, identifying financial frauds, and detecting fake news. However, obtaining complete, accurate, and precise labels for AD tasks can be expensive and challenging due to the cost and difficulties in data annotation. To address this issue, researchers have developed AD methods that can work with incomplete, inexact, and inaccurate supervision, collectively summarized as weakly supervised anomaly detection (WSAD) methods. In this study, we present the first comprehensive survey of WSAD methods by categorizing them into the above three weak supervision settings across four data modalities (i.e., tabular, graph, time-series, and image/video data). For each setting, we provide formal definitions, key algorithms, and potential future directions. To support future research, we conduct experiments on a selected setting and release the source code, along with a collection of WSAD methods and data.
A novel deep learning-based method for monochromatic image synthesis from spectral CT using photon-counting detectors
Jul 20, 2020
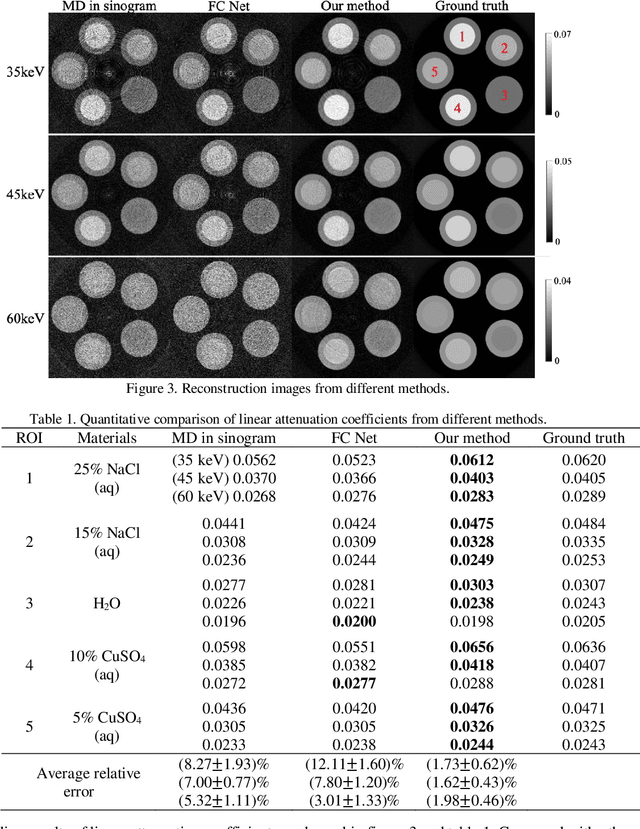

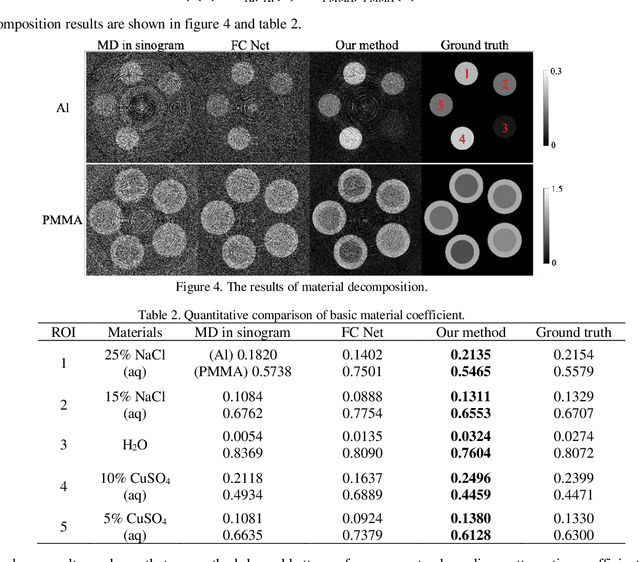
With the growing technology of photon-counting detectors (PCD), spectral CT is a widely concerned topic which has the potential of material differentiation. However, due to some non-ideal factors such as cross talk and pulse pile-up of the detectors, direct reconstruction from detected spectrum without any corrections will get a wrong result. Conventional methods try to model these factors using calibration and make corrections accordingly, but depend on the preciseness of the model. To solve this problem, in this paper, we proposed a novel deep learning-based monochromatic image synthesis method working in sinogram domain. Different from previous deep learning-based methods aimed at this problem, we designed a novel network architecture according to the physical model of cross talk, and it can solve this problem better in an ingenious way. Our method was tested on a cone-beam CT (CBCT) system equipped with a PCD. After using FDK algorithm on the corrected projection, we got quite more accurate results with less noise, which showed the feasibility of monochromatic image synthesis by our method.
A cascaded dual-domain deep learning reconstruction method for sparsely spaced multidetector helical CT
Oct 23, 2019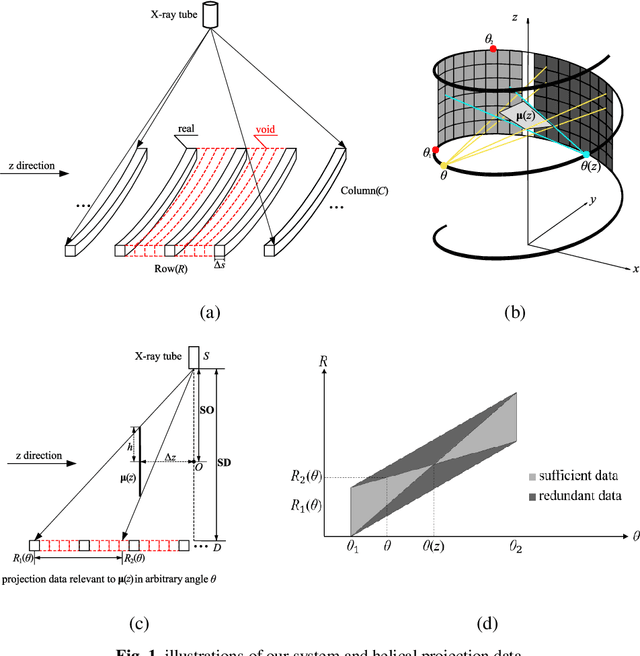

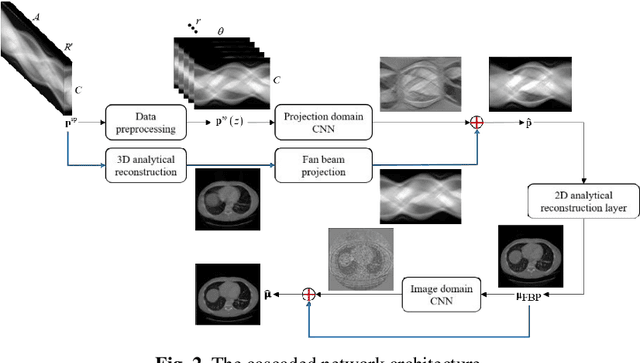
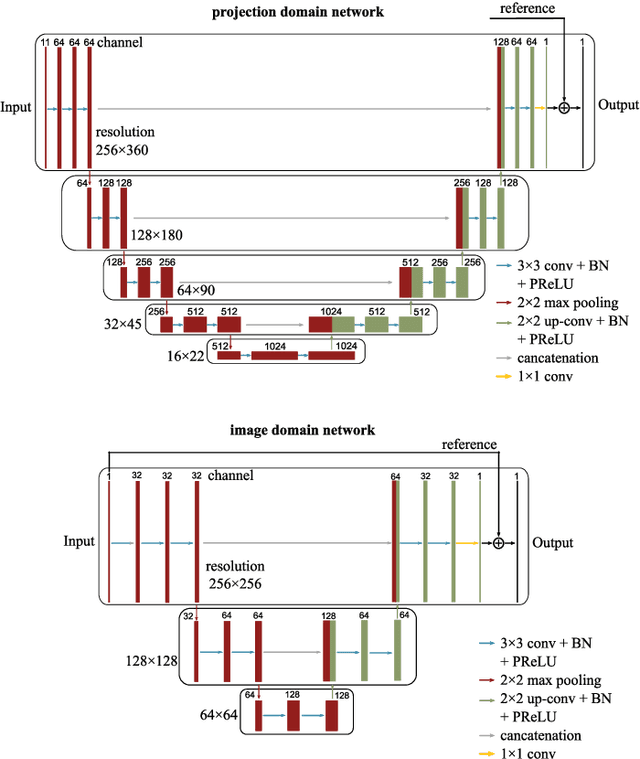
Helical CT has been widely used in clinical diagnosis. Sparsely spaced multidetector in z direction can increase the coverage of the detector provided limited detector rows. It can speed up volumetric CT scan, lower the radiation dose and reduce motion artifacts. However, it leads to insufficient data for reconstruction. That means reconstructions from general analytical methods will have severe artifacts. Iterative reconstruction methods might be able to deal with this situation but with the cost of huge computational load. In this work, we propose a cascaded dual-domain deep learning method that completes both data transformation in projection domain and error reduction in image domain. First, a convolutional neural network (CNN) in projection domain is constructed to estimate missing helical projection data and converting helical projection data to 2D fan-beam projection data. This step is to suppress helical artifacts and reduce the following computational cost. Then, an analytical linear operator is followed to transfer the data from projection domain to image domain. Finally, an image domain CNN is added to improve image quality further. These three steps work as an entirety and can be trained end to end. The overall network is trained using a simulated lung CT dataset with Poisson noise from 25 patients. We evaluate the trained network on another three patients and obtain very encouraging results with both visual examination and quantitative comparison. The resulting RRMSE is 6.56% and the SSIM is 99.60%. In addition, we test the trained network on the lung CT dataset with different noise level and a new dental CT dataset to demonstrate the generalization and robustness of our method.