 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Distribution-free Adaptive Computation of Matrix Functions for Accelerating Neural Network Training
Jan 29, 2026Matrix functions such as square root, inverse roots, and orthogonalization play a central role in preconditioned gradient methods for neural network training. This has motivated the development of iterative algorithms that avoid explicit eigendecompositions and rely primarily on matrix multiplications, making them well suited for modern GPU accelerators. We present PRISM (Polynomial-fitting and Randomized Iterative Sketching for Matrix functions computation), a general framework for accelerating iterative algorithms for computing matrix functions. PRISM combines adaptive polynomial approximation with randomized sketching: at each iteration, it fits a polynomial surrogate to the current spectrum via a sketched least-squares problem, adapting to the instance at hand with minimal overhead. We apply PRISM to accelerate Newton-Schulz-like iterations for matrix square roots and orthogonalization, which are core primitives in machine learning. Unlike prior methods, PRISM requires no explicit spectral bounds or singular value estimates; and it adapts automatically to the evolving spectrum. Empirically, PRISM accelerates training when integrated into Shampoo and Muon optimizers.
LLM4Fluid: Large Language Models as Generalizable Neural Solvers for Fluid Dynamics
Jan 29, 2026Deep learning has emerged as a promising paradigm for spatio-temporal modeling of fluid dynamics. However, existing approaches often suffer from limited generalization to unseen flow conditions and typically require retraining when applied to new scenarios. In this paper, we present LLM4Fluid, a spatio-temporal prediction framework that leverages Large Language Models (LLMs) as generalizable neural solvers for fluid dynamics. The framework first compresses high-dimensional flow fields into a compact latent space via reduced-order modeling enhanced with a physics-informed disentanglement mechanism, effectively mitigating spatial feature entanglement while preserving essential flow structures. A pretrained LLM then serves as a temporal processor, autoregressively predicting the dynamics of physical sequences with time series prompts. To bridge the modality gap between prompts and physical sequences, which can otherwise degrade prediction accuracy, we propose a dedicated modality alignment strategy that resolves representational mismatch and stabilizes long-term prediction. Extensive experiments across diverse flow scenarios demonstrate that LLM4Fluid functions as a robust and generalizable neural solver without retraining, achieving state-of-the-art accuracy while exhibiting powerful zero-shot and in-context learning capabilities. Code and datasets are publicly available at https://github.com/qisongxiao/LLM4Fluid.
OneVoice: One Model, Triple Scenarios-Towards Unified Zero-shot Voice Conversion
Jan 26, 2026Recent progress of voice conversion~(VC) has achieved a new milestone in speaker cloning and linguistic preservation. But the field remains fragmented, relying on specialized models for linguistic-preserving, expressive, and singing scenarios. We propose OneVoice, a unified zero-shot framework capable of handling all three scenarios within a single model. OneVoice is built upon a continuous language model trained with VAE-free next-patch diffusion, ensuring high fidelity and efficient sequence modeling. Its core design for unification lies in a Mixture-of-Experts (MoE) designed to explicitly model shared conversion knowledge and scenario-specific expressivity. Expert selection is coordinated by a dual-path routing mechanism, including shared expert isolation and scenario-aware domain expert assignment with global-local cues. For precise conditioning, scenario-specific prosodic features are fused into each layer via a gated mechanism, allowing adaptive usage of prosody information. Furthermore, to enable the core idea and alleviate the imbalanced issue (abundant speech vs. scarce singing), we adopt a two-stage progressive training that includes foundational pre-training and scenario enhancement with LoRA-based domain experts. Experiments show that OneVoice matches or surpasses specialized models across all three scenarios, while verifying flexible control over scenarios and offering a fast decoding version as few as 2 steps. Code and model will be released soon.
The End of Manual Decoding: Towards Truly End-to-End Language Models
Oct 30, 2025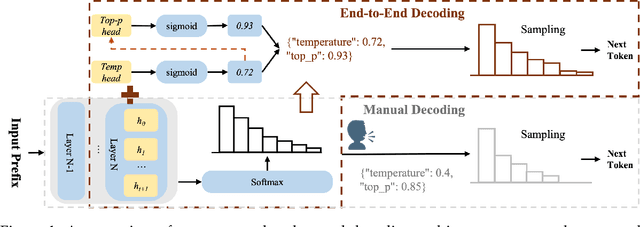
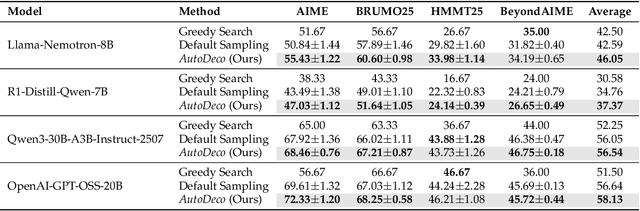
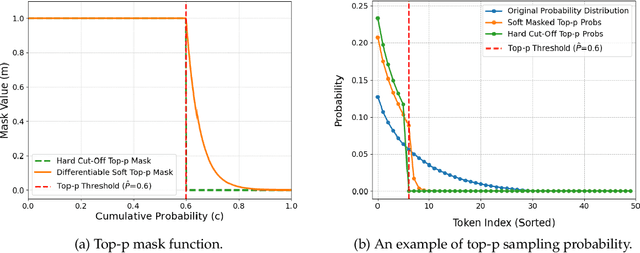
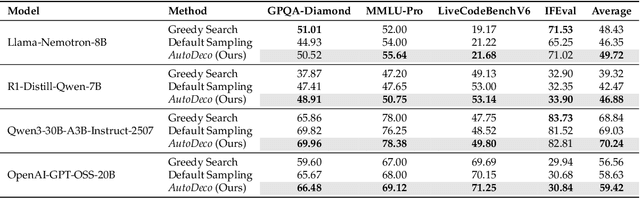
The "end-to-end" label for LLMs is a misnomer. In practice, they depend on a non-differentiable decoding process that requires laborious, hand-tuning of hyperparameters like temperature and top-p. This paper introduces AutoDeco, a novel architecture that enables truly "end-to-end" generation by learning to control its own decoding strategy. We augment the standard transformer with lightweight heads that, at each step, dynamically predict context-specific temperature and top-p values alongside the next-token logits. This approach transforms decoding into a parametric, token-level process, allowing the model to self-regulate its sampling strategy within a single forward pass. Through extensive experiments on eight benchmarks, we demonstrate that AutoDeco not only significantly outperforms default decoding strategies but also achieves performance comparable to an oracle-tuned baseline derived from "hacking the test set"-a practical upper bound for any static method. Crucially, we uncover an emergent capability for instruction-based decoding control: the model learns to interpret natural language commands (e.g., "generate with low randomness") and adjusts its predicted temperature and top-p on a token-by-token basis, opening a new paradigm for steerable and interactive LLM decoding.
RLSR: Reinforcement Learning with Supervised Reward Outperforms SFT in Instruction Following
Oct 16, 2025



After the pretraining stage of LLMs, techniques such as SFT, RLHF, RLVR, and RFT are applied to enhance instruction-following ability, mitigate undesired responses, improve reasoning capability and enable efficient domain adaptation with minimal data. SFT relies on the next-token prediction objective to strengthen instruction following in a base model using a large corpus of human-labeled responses. In contrast, RFT employs a RL-based approach to adapt fine-tuned reasoning models to specific domains with limited supervision. Inspired by RFT, we propose replacing SFT with RLSR to leverage the extensive SFT dataset in an RL framework, thereby improving the base model's instruction-following ability. In RLSR, the base model generates multiple responses for each prompt, and reward scores are computed as the cosine similarity in the semantic embedding space between the generated and human-labeled responses. RLSR can be utilized in multiple ways. It can directly replace SFT, achieving superior performance on instruction-following benchmarks-for example, RLSR (SB) on Qwen-7B (INFINITY) achieved an AlpacaEval win rate of 26.34%, surpassing SFT's 21.01%. Furthermore, combining SFT and RLSR further enhances downstream task performance; Qwen-7B (INFINITY) achieved a win rate of 30.73% when trained with SFT + RLSR.
Multi-Physics: A Comprehensive Benchmark for Multimodal LLMs Reasoning on Chinese Multi-Subject Physics Problems
Sep 19, 2025



While multimodal LLMs (MLLMs) demonstrate remarkable reasoning progress, their application in specialized scientific domains like physics reveals significant gaps in current evaluation benchmarks. Specifically, existing benchmarks often lack fine-grained subject coverage, neglect the step-by-step reasoning process, and are predominantly English-centric, failing to systematically evaluate the role of visual information. Therefore, we introduce \textbf {Multi-Physics} for Chinese physics reasoning, a comprehensive benchmark that includes 5 difficulty levels, featuring 1,412 image-associated, multiple-choice questions spanning 11 high-school physics subjects. We employ a dual evaluation framework to evaluate 20 different MLLMs, analyzing both final answer accuracy and the step-by-step integrity of their chain-of-thought. Furthermore, we systematically study the impact of difficulty level and visual information by comparing the model performance before and after changing the input mode. Our work provides not only a fine-grained resource for the community but also offers a robust methodology for dissecting the multimodal reasoning process of state-of-the-art MLLMs, and our dataset and code have been open-sourced: https://github.com/luozhongze/Multi-Physics.
UGM2N: An Unsupervised and Generalizable Mesh Movement Network via M-Uniform Loss
Aug 12, 2025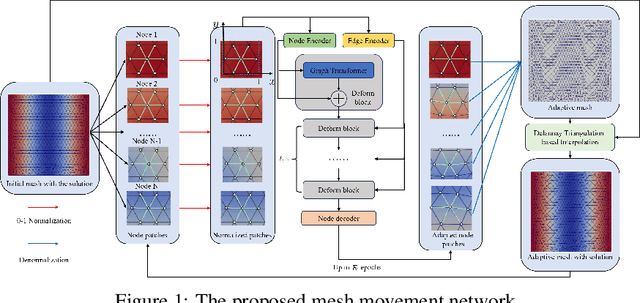
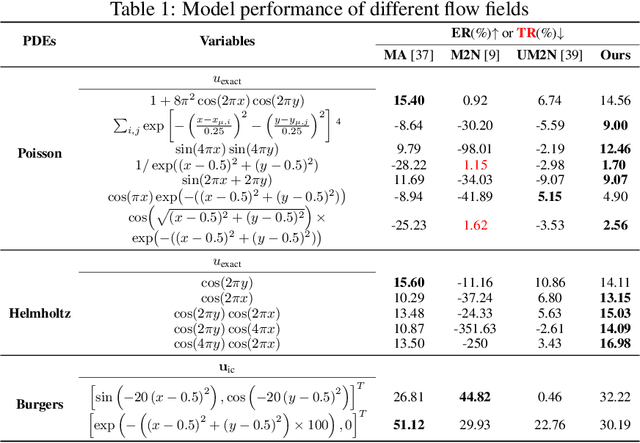

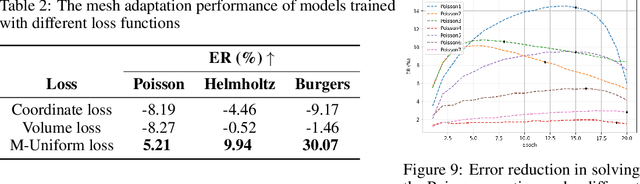
Partial differential equations (PDEs) form the mathematical foundation for modeling physical systems in science and engineering, where numerical solutions demand rigorous accuracy-efficiency tradeoffs. Mesh movement techniques address this challenge by dynamically relocating mesh nodes to rapidly-varying regions, enhancing both simulation accuracy and computational efficiency. However, traditional approaches suffer from high computational complexity and geometric inflexibility, limiting their applicability, and existing supervised learning-based approaches face challenges in zero-shot generalization across diverse PDEs and mesh topologies.In this paper, we present an Unsupervised and Generalizable Mesh Movement Network (UGM2N). We first introduce unsupervised mesh adaptation through localized geometric feature learning, eliminating the dependency on pre-adapted meshes. We then develop a physics-constrained loss function, M-Uniform loss, that enforces mesh equidistribution at the nodal level.Experimental results demonstrate that the proposed network exhibits equation-agnostic generalization and geometric independence in efficient mesh adaptation. It demonstrates consistent superiority over existing methods, including robust performance across diverse PDEs and mesh geometries, scalability to multi-scale resolutions and guaranteed error reduction without mesh tangling.
Generalization Bound of Gradient Flow through Training Trajectory and Data-dependent Kernel
Jun 12, 2025Gradient-based optimization methods have shown remarkable empirical success, yet their theoretical generalization properties remain only partially understood. In this paper, we establish a generalization bound for gradient flow that aligns with the classical Rademacher complexity bounds for kernel methods-specifically those based on the RKHS norm and kernel trace-through a data-dependent kernel called the loss path kernel (LPK). Unlike static kernels such as NTK, the LPK captures the entire training trajectory, adapting to both data and optimization dynamics, leading to tighter and more informative generalization guarantees. Moreover, the bound highlights how the norm of the training loss gradients along the optimization trajectory influences the final generalization performance. The key technical ingredients in our proof combine stability analysis of gradient flow with uniform convergence via Rademacher complexity. Our bound recovers existing kernel regression bounds for overparameterized neural networks and shows the feature learning capability of neural networks compared to kernel methods. Numerical experiments on real-world datasets validate that our bounds correlate well with the true generalization gap.
Federated Unlearning with Gradient Descent and Conflict Mitigation
Dec 28, 2024



Federated Learning (FL) has received much attention in recent years. However, although clients are not required to share their data in FL, the global model itself can implicitly remember clients' local data. Therefore, it's necessary to effectively remove the target client's data from the FL global model to ease the risk of privacy leakage and implement ``the right to be forgotten". Federated Unlearning (FU) has been considered a promising way to remove data without full retraining. But the model utility easily suffers significant reduction during unlearning due to the gradient conflicts. Furthermore, when conducting the post-training to recover the model utility, the model is prone to move back and revert what has already been unlearned. To address these issues, we propose Federated Unlearning with Orthogonal Steepest Descent (FedOSD). We first design an unlearning Cross-Entropy loss to overcome the convergence issue of the gradient ascent. A steepest descent direction for unlearning is then calculated in the condition of being non-conflicting with other clients' gradients and closest to the target client's gradient. This benefits to efficiently unlearn and mitigate the model utility reduction. After unlearning, we recover the model utility by maintaining the achievement of unlearning. Finally, extensive experiments in several FL scenarios verify that FedOSD outperforms the SOTA FU algorithms in terms of unlearning and model utility.
Optimal Exact Recovery in Semi-Supervised Learning: A Study of Spectral Methods and Graph Convolutional Networks
Dec 18, 2024



We delve into the challenge of semi-supervised node classification on the Contextual Stochastic Block Model (CSBM) dataset. Here, nodes from the two-cluster Stochastic Block Model (SBM) are coupled with feature vectors, which are derived from a Gaussian Mixture Model (GMM) that corresponds to their respective node labels. With only a subset of the CSBM node labels accessible for training, our primary objective becomes the accurate classification of the remaining nodes. Venturing into the transductive learning landscape, we, for the first time, pinpoint the information-theoretical threshold for the exact recovery of all test nodes in CSBM. Concurrently, we design an optimal spectral estimator inspired by Principal Component Analysis (PCA) with the training labels and essential data from both the adjacency matrix and feature vectors. We also evaluate the efficacy of graph ridge regression and Graph Convolutional Networks (GCN) on this synthetic dataset. Our findings underscore that graph ridge regression and GCN possess the ability to achieve the information threshold of exact recovery in a manner akin to the optimal estimator when using the optimal weighted self-loops. This highlights the potential role of feature learning in augmenting the proficiency of GCN, especially in the realm of semi-supervised learning.