 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUFT: Unifying Fine-Tuning of SFT and RLHF/DPO/UNA through a Generalized Implicit Reward Function
Oct 28, 2024
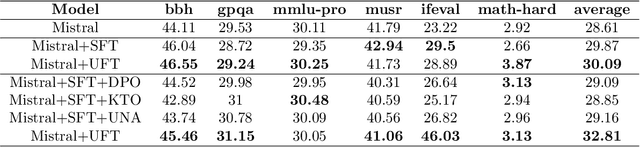
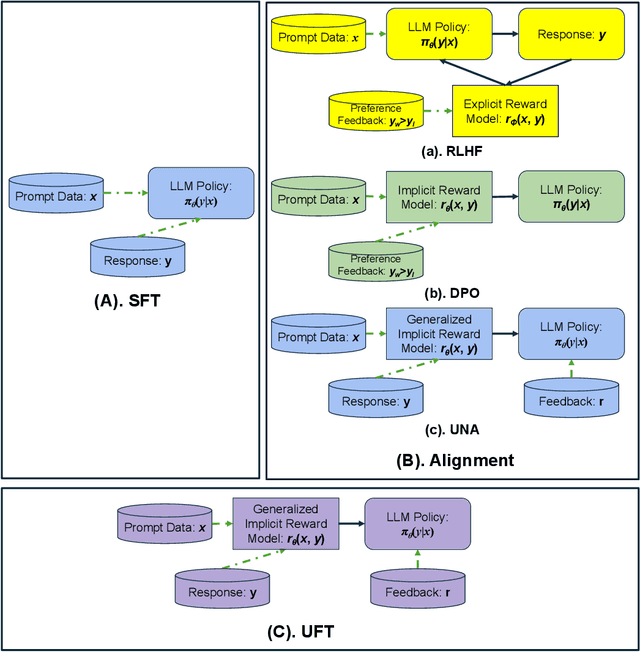

By pretraining on trillions of tokens, an LLM gains the capability of text generation. However, to enhance its utility and reduce potential harm, SFT and alignment are applied sequentially to the pretrained model. Due to the differing nature and objective functions of SFT and alignment, catastrophic forgetting has become a significant issue. To address this, we introduce Unified Fine-Tuning (UFT), which integrates SFT and alignment into a single training stage using the same objective and loss functions through an implicit reward function. Our experimental results demonstrate that UFT outperforms SFT on instruction-tuning data alone. Moreover, when combining instruction-tuning data with alignment data, UFT effectively prevents catastrophic forgetting across these two stages and shows a clear advantage over sequentially applying SFT and alignment. This is evident in the significant improvements observed in the \textbf{ifeval} task for instruction-following and the \textbf{truthful-qa} task for factuality. The proposed general fine-tuning framework UFT establishes an effective and efficient pretraining-UFT paradigm for LLM training.