 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Decoder-Only Automatic Speech Recognition with Discrete Speech Units: A Pilot Study
Jun 27, 2024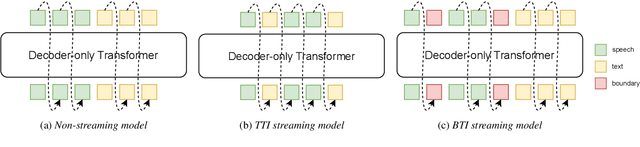
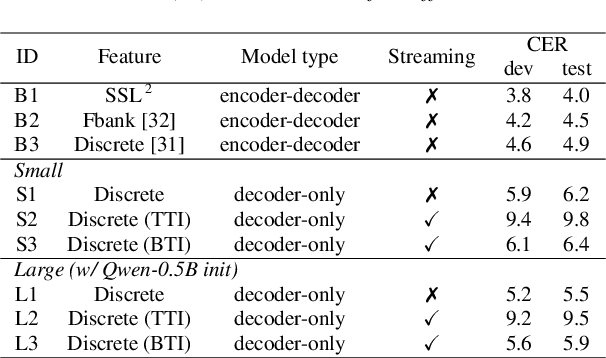
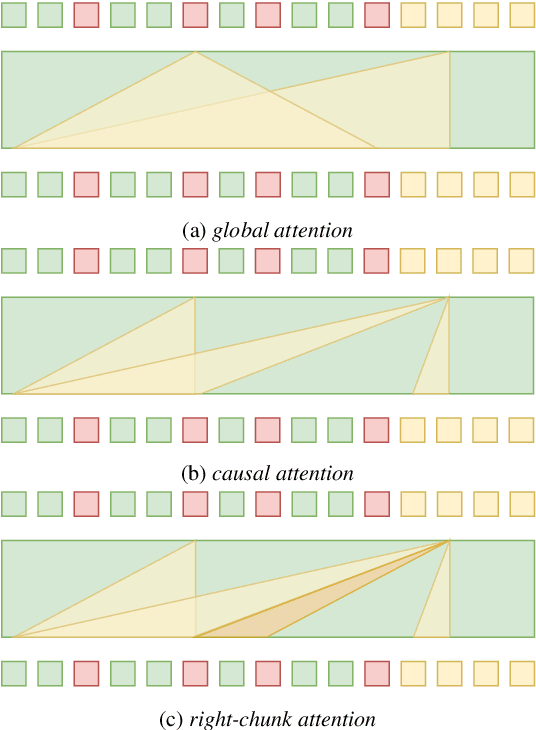

Unified speech-text models like SpeechGPT, VioLA, and AudioPaLM have shown impressive performance across various speech-related tasks, especially in Automatic Speech Recognition (ASR). These models typically adopt a unified method to model discrete speech and text tokens, followed by training a decoder-only transformer. However, they are all designed for non-streaming ASR tasks, where the entire speech utterance is needed during decoding. Hence, we introduce a decoder-only model exclusively designed for streaming recognition, incorporating a dedicated boundary token to facilitate streaming recognition and employing causal attention masking during the training phase. Furthermore, we introduce right-chunk attention and various data augmentation techniques to improve the model's contextual modeling abilities. While achieving streaming speech recognition, experiments on the AISHELL-1 and -2 datasets demonstrate the competitive performance of our streaming approach with non-streaming decoder-only counterparts.
BA-MoE: Boundary-Aware Mixture-of-Experts Adapter for Code-Switching Speech Recognition
Oct 08, 2023Mixture-of-experts based models, which use language experts to extract language-specific representations effectively, have been well applied in code-switching automatic speech recognition. However, there is still substantial space to improve as similar pronunciation across languages may result in ineffective multi-language modeling and inaccurate language boundary estimation. To eliminate these drawbacks, we propose a cross-layer language adapter and a boundary-aware training method, namely Boundary-Aware Mixture-of-Experts (BA-MoE). Specifically, we introduce language-specific adapters to separate language-specific representations and a unified gating layer to fuse representations within each encoder layer. Second, we compute language adaptation loss of the mean output of each language-specific adapter to improve the adapter module's language-specific representation learning. Besides, we utilize a boundary-aware predictor to learn boundary representations for dealing with language boundary confusion. Our approach achieves significant performance improvement, reducing the mixture error rate by 16.55\% compared to the baseline on the ASRU 2019 Mandarin-English code-switching challenge dataset.
SALT: Distinguishable Speaker Anonymization Through Latent Space Transformation
Oct 08, 2023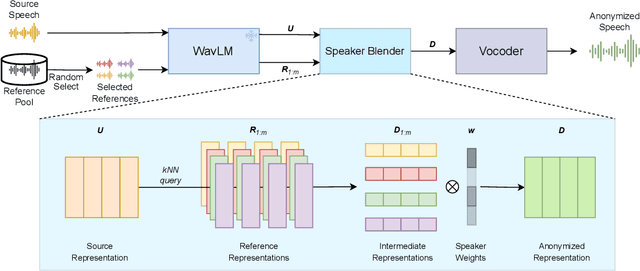


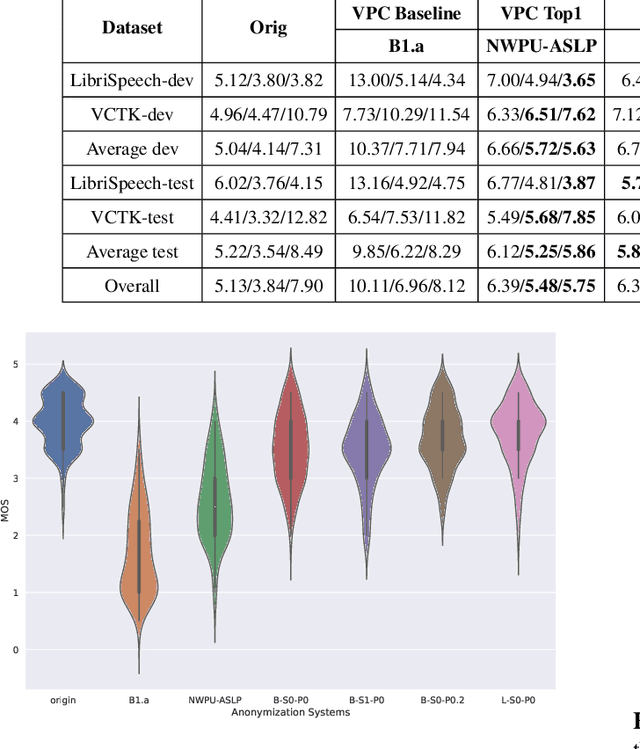
Speaker anonymization aims to conceal a speaker's identity without degrading speech quality and intelligibility. Most speaker anonymization systems disentangle the speaker representation from the original speech and achieve anonymization by averaging or modifying the speaker representation. However, the anonymized speech is subject to reduction in pseudo speaker distinctiveness, speech quality and intelligibility for out-of-distribution speaker. To solve this issue, we propose SALT, a Speaker Anonymization system based on Latent space Transformation. Specifically, we extract latent features by a self-supervised feature extractor and randomly sample multiple speakers and their weights, and then interpolate the latent vectors to achieve speaker anonymization. Meanwhile, we explore the extrapolation method to further extend the diversity of pseudo speakers. Experiments on Voice Privacy Challenge dataset show our system achieves a state-of-the-art distinctiveness metric while preserving speech quality and intelligibility. Our code and demo is availible at https://github.com/BakerBunker/SALT .
SSHR: Leveraging Self-supervised Hierarchical Representations for Multilingual Automatic Speech Recognition
Sep 29, 2023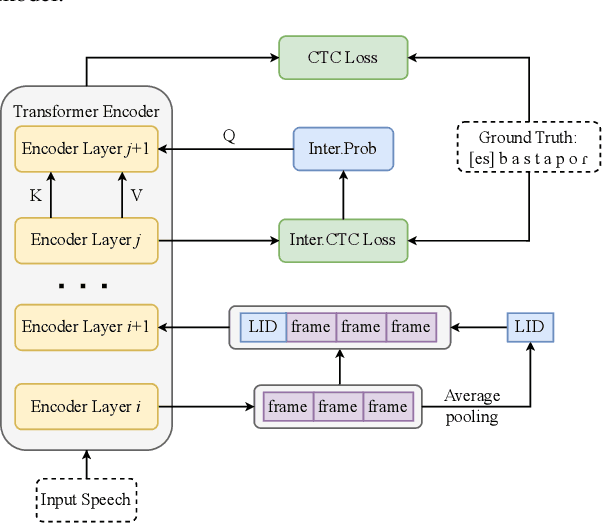
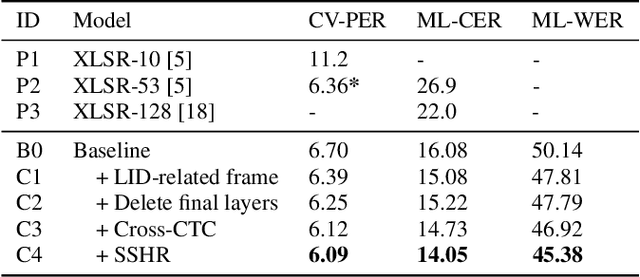

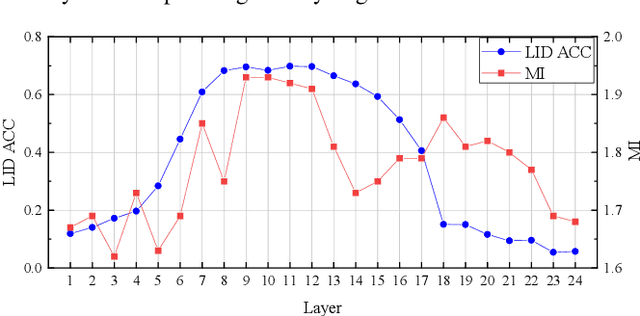
Multilingual automatic speech recognition (ASR) systems have garnered attention for their potential to extend language coverage globally. While self-supervised learning (SSL) has demonstrated its effectiveness in multilingual ASR, it is worth noting that the various layers' representations of SSL potentially contain distinct information that has not been fully leveraged. In this study, we propose a novel method that leverages self-supervised hierarchical representations (SSHR) to fine-tune multilingual ASR. We first analyze the different layers of the SSL model for language-related and content-related information, uncovering layers that show a stronger correlation. Then, we extract a language-related frame from correlated middle layers and guide specific content extraction through self-attention mechanisms. Additionally, we steer the model toward acquiring more content-related information in the final layers using our proposed Cross-CTC. We evaluate SSHR on two multilingual datasets, Common Voice and ML-SUPERB, and the experimental results demonstrate that our method achieves state-of-the-art performance to the best of our knowledge.
The NPU-MSXF Speech-to-Speech Translation System for IWSLT 2023 Speech-to-Speech Translation Task
Jul 10, 2023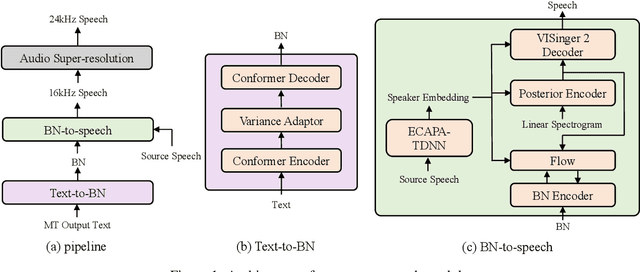


This paper describes the NPU-MSXF system for the IWSLT 2023 speech-to-speech translation (S2ST) task which aims to translate from English speech of multi-source to Chinese speech. The system is built in a cascaded manner consisting of automatic speech recognition (ASR), machine translation (MT), and text-to-speech (TTS). We make tremendous efforts to handle the challenging multi-source input. Specifically, to improve the robustness to multi-source speech input, we adopt various data augmentation strategies and a ROVER-based score fusion on multiple ASR model outputs. To better handle the noisy ASR transcripts, we introduce a three-stage fine-tuning strategy to improve translation accuracy. Finally, we build a TTS model with high naturalness and sound quality, which leverages a two-stage framework, using network bottleneck features as a robust intermediate representation for speaker timbre and linguistic content disentanglement. Based on the two-stage framework, pre-trained speaker embedding is leveraged as a condition to transfer the speaker timbre in the source English speech to the translated Chinese speech. Experimental results show that our system has high translation accuracy, speech naturalness, sound quality, and speaker similarity. Moreover, it shows good robustness to multi-source data.
TranUSR: Phoneme-to-word Transcoder Based Unified Speech Representation Learning for Cross-lingual Speech Recognition
May 23, 2023



UniSpeech has achieved superior performance in cross-lingual automatic speech recognition (ASR) by explicitly aligning latent representations to phoneme units using multi-task self-supervised learning. While the learned representations transfer well from high-resource to low-resource languages, predicting words directly from these phonetic representations in downstream ASR is challenging. In this paper, we propose TranUSR, a two-stage model comprising a pre-trained UniData2vec and a phoneme-to-word Transcoder. Different from UniSpeech, UniData2vec replaces the quantized discrete representations with continuous and contextual representations from a teacher model for phonetically-aware pre-training. Then, Transcoder learns to translate phonemes to words with the aid of extra texts, enabling direct word generation. Experiments on Common Voice show that UniData2vec reduces PER by 5.3\% compared to UniSpeech, while Transcoder yields a 14.4\% WER reduction compared to grapheme fine-tuning.
The NPU-ASLP System for Audio-Visual Speech Recognition in MISP 2022 Challenge
Mar 11, 2023


This paper describes our NPU-ASLP system for the Audio-Visual Diarization and Recognition (AVDR) task in the Multi-modal Information based Speech Processing (MISP) 2022 Challenge. Specifically, the weighted prediction error (WPE) and guided source separation (GSS) techniques are used to reduce reverberation and generate clean signals for each single speaker first. Then, we explore the effectiveness of Branchformer and E-Branchformer based ASR systems. To better make use of the visual modality, a cross-attention based multi-modal fusion module is proposed, which explicitly learns the contextual relationship between different modalities. Experiments show that our system achieves a concatenated minimum-permutation character error rate (cpCER) of 28.13\% and 31.21\% on the Dev and Eval set, and obtains second place in the challenge.
The NPU-ASLP System for The ISCSLP 2022 Magichub Code-Swiching ASR Challenge
Oct 26, 2022This paper describes our NPU-ASLP system submitted to the ISCSLP 2022 Magichub Code-Switching ASR Challenge. In this challenge, we first explore several popular end-to-end ASR architectures and training strategies, including bi-encoder, language-aware encoder (LAE) and mixture of experts (MoE). To improve our system's language modeling ability, we further attempt the internal language model as well as the long context language model. Given the limited training data in the challenge, we further investigate the effects of data augmentation, including speed perturbation, pitch shifting, speech codec, SpecAugment and synthetic data from text-to-speech (TTS). Finally, we explore ROVER-based score fusion to make full use of complementary hypotheses from different models. Our submitted system achieves 16.87% on mix error rate (MER) on the test set and comes to the 2nd place in the challenge ranking.