 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Decoder-Only Automatic Speech Recognition with Discrete Speech Units: A Pilot Study
Paper and Code
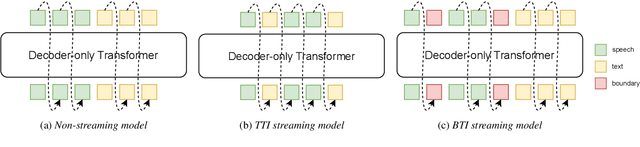
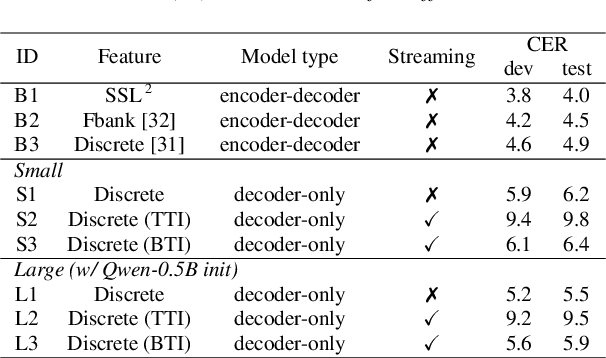
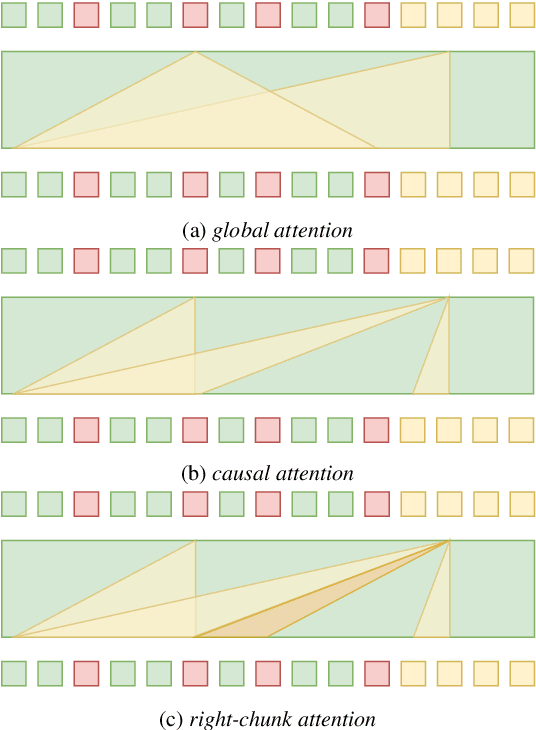

Unified speech-text models like SpeechGPT, VioLA, and AudioPaLM have shown impressive performance across various speech-related tasks, especially in Automatic Speech Recognition (ASR). These models typically adopt a unified method to model discrete speech and text tokens, followed by training a decoder-only transformer. However, they are all designed for non-streaming ASR tasks, where the entire speech utterance is needed during decoding. Hence, we introduce a decoder-only model exclusively designed for streaming recognition, incorporating a dedicated boundary token to facilitate streaming recognition and employing causal attention masking during the training phase. Furthermore, we introduce right-chunk attention and various data augmentation techniques to improve the model's contextual modeling abilities. While achieving streaming speech recognition, experiments on the AISHELL-1 and -2 datasets demonstrate the competitive performance of our streaming approach with non-streaming decoder-only counterparts.