 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable Self-Evolving Memory for Automatic Prompt Optimization
Mar 23, 2026Automatic prompt optimization is a promising approach for adapting large language models (LLMs) to downstream tasks, yet existing methods typically search for a specific prompt specialized to a fixed task. This paradigm limits generalization across heterogeneous queries and prevents models from accumulating reusable prompting knowledge over time. In this paper, we propose MemAPO, a memory-driven framework that reconceptualizes prompt optimization as generalizable and self-evolving experience accumulation. MemAPO maintains a dual-memory mechanism that distills successful reasoning trajectories into reusable strategy templates while organizing incorrect generations into structured error patterns that capture recurrent failure modes. Given a new prompt, the framework retrieves both relevant strategies and failure patterns to compose prompts that promote effective reasoning while discouraging known mistakes. Through iterative self-reflection and memory editing, MemAPO continuously updates its memory, enabling prompt optimization to improve over time rather than restarting from scratch for each task. Experiments on diverse benchmarks show that MemAPO consistently outperforms representative prompt optimization baselines while substantially reducing optimization cost.
AInsteinBench: Benchmarking Coding Agents on Scientific Repositories
Dec 24, 2025We introduce AInsteinBench, a large-scale benchmark for evaluating whether large language model (LLM) agents can operate as scientific computing development agents within real research software ecosystems. Unlike existing scientific reasoning benchmarks which focus on conceptual knowledge, or software engineering benchmarks that emphasize generic feature implementation and issue resolving, AInsteinBench evaluates models in end-to-end scientific development settings grounded in production-grade scientific repositories. The benchmark consists of tasks derived from maintainer-authored pull requests across six widely used scientific codebases, spanning quantum chemistry, quantum computing, molecular dynamics, numerical relativity, fluid dynamics, and cheminformatics. All benchmark tasks are carefully curated through multi-stage filtering and expert review to ensure scientific challenge, adequate test coverage, and well-calibrated difficulty. By leveraging evaluation in executable environments, scientifically meaningful failure modes, and test-driven verification, AInsteinBench measures a model's ability to move beyond surface-level code generation toward the core competencies required for computational scientific research.
LLM Swiss Round: Aggregating Multi-Benchmark Performance via Competitive Swiss-System Dynamics
Dec 24, 2025The rapid proliferation of Large Language Models (LLMs) and diverse specialized benchmarks necessitates a shift from fragmented, task-specific metrics to a holistic, competitive ranking system that effectively aggregates performance across multiple ability dimensions. Primarily using static scoring, current evaluation methods are fundamentally limited. They struggle to determine the proper mix ratio across diverse benchmarks, and critically, they fail to capture a model's dynamic competitive fitness or its vulnerability when confronted with sequential, high-stakes tasks. To address this, we introduce the novel Competitive Swiss-System Dynamics (CSD) framework. CSD simulates a multi-round, sequential contest where models are dynamically paired across a curated sequence of benchmarks based on their accumulated win-loss record. And Monte Carlo Simulation ($N=100,000$ iterations) is used to approximate the statistically robust Expected Win Score ($E[S_m]$), which eliminates the noise of random pairing and early-round luck. Furthermore, we implement a Failure Sensitivity Analysis by parameterizing the per-round elimination quantity ($T_k$), which allows us to profile models based on their risk appetite--distinguishing between robust generalists and aggressive specialists. We demonstrate that CSD provides a more nuanced and context-aware ranking than traditional aggregate scoring and static pairwise models, representing a vital step towards risk-informed, next-generation LLM evaluation.
NL2Repo-Bench: Towards Long-Horizon Repository Generation Evaluation of Coding Agents
Dec 14, 2025Recent advances in coding agents suggest rapid progress toward autonomous software development, yet existing benchmarks fail to rigorously evaluate the long-horizon capabilities required to build complete software systems. Most prior evaluations focus on localized code generation, scaffolded completion, or short-term repair tasks, leaving open the question of whether agents can sustain coherent reasoning, planning, and execution over the extended horizons demanded by real-world repository construction. To address this gap, we present NL2Repo Bench, a benchmark explicitly designed to evaluate the long-horizon repository generation ability of coding agents. Given only a single natural-language requirements document and an empty workspace, agents must autonomously design the architecture, manage dependencies, implement multi-module logic, and produce a fully installable Python library. Our experiments across state-of-the-art open- and closed-source models reveal that long-horizon repository generation remains largely unsolved: even the strongest agents achieve below 40% average test pass rates and rarely complete an entire repository correctly. Detailed analysis uncovers fundamental long-horizon failure modes, including premature termination, loss of global coherence, fragile cross-file dependencies, and inadequate planning over hundreds of interaction steps. NL2Repo Bench establishes a rigorous, verifiable testbed for measuring sustained agentic competence and highlights long-horizon reasoning as a central bottleneck for the next generation of autonomous coding agents.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
PromptMID: Modal Invariant Descriptors Based on Diffusion and Vision Foundation Models for Optical-SAR Image Matching
Feb 25, 2025The ideal goal of image matching is to achieve stable and efficient performance in unseen domains. However, many existing learning-based optical-SAR image matching methods, despite their effectiveness in specific scenarios, exhibit limited generalization and struggle to adapt to practical applications. Repeatedly training or fine-tuning matching models to address domain differences is not only not elegant enough but also introduces additional computational overhead and data production costs. In recent years, general foundation models have shown great potential for enhancing generalization. However, the disparity in visual domains between natural and remote sensing images poses challenges for their direct application. Therefore, effectively leveraging foundation models to improve the generalization of optical-SAR image matching remains challenge. To address the above challenges, we propose PromptMID, a novel approach that constructs modality-invariant descriptors using text prompts based on land use classification as priors information for optical and SAR image matching. PromptMID extracts multi-scale modality-invariant features by leveraging pre-trained diffusion models and visual foundation models (VFMs), while specially designed feature aggregation modules effectively fuse features across different granularities. Extensive experiments on optical-SAR image datasets from four diverse regions demonstrate that PromptMID outperforms state-of-the-art matching methods, achieving superior results in both seen and unseen domains and exhibiting strong cross-domain generalization capabilities. The source code will be made publicly available https://github.com/HanNieWHU/PromptMID.
CAMEL: Cross-Attention Enhanced Mixture-of-Experts and Language Bias for Code-Switching Speech Recognition
Dec 17, 2024



Code-switching automatic speech recognition (ASR) aims to transcribe speech that contains two or more languages accurately. To better capture language-specific speech representations and address language confusion in code-switching ASR, the mixture-of-experts (MoE) architecture and an additional language diarization (LD) decoder are commonly employed. However, most researches remain stagnant in simple operations like weighted summation or concatenation to fuse language-specific speech representations, leaving significant opportunities to explore the enhancement of integrating language bias information. In this paper, we introduce CAMEL, a cross-attention-based MoE and language bias approach for code-switching ASR. Specifically, after each MoE layer, we fuse language-specific speech representations with cross-attention, leveraging its strong contextual modeling abilities. Additionally, we design a source attention-based mechanism to incorporate the language information from the LD decoder output into text embeddings. Experimental results demonstrate that our approach achieves state-of-the-art performance on the SEAME, ASRU200, and ASRU700+LibriSpeech460 Mandarin-English code-switching ASR datasets.
XCB: an effective contextual biasing approach to bias cross-lingual phrases in speech recognition
Aug 20, 2024


Contextualized ASR models have been demonstrated to effectively improve the recognition accuracy of uncommon phrases when a predefined phrase list is available. However, these models often struggle with bilingual settings, which are prevalent in code-switching speech recognition. In this study, we make the initial attempt to address this challenge by introducing a Cross-lingual Contextual Biasing(XCB) module. Specifically, we augment a pre-trained ASR model for the dominant language by integrating an auxiliary language biasing module and a supplementary language-specific loss, aimed at enhancing the recognition of phrases in the secondary language. Experimental results conducted on our in-house code-switching dataset have validated the efficacy of our approach, demonstrating significant improvements in the recognition of biasing phrases in the secondary language, even without any additional inference overhead. Additionally, our proposed system exhibits both efficiency and generalization when is applied by the unseen ASRU-2019 test set.
MMGER: Multi-modal and Multi-granularity Generative Error Correction with LLM for Joint Accent and Speech Recognition
May 06, 2024



Despite notable advancements in automatic speech recognition (ASR), performance tends to degrade when faced with adverse conditions. Generative error correction (GER) leverages the exceptional text comprehension capabilities of large language models (LLM), delivering impressive performance in ASR error correction, where N-best hypotheses provide valuable information for transcription prediction. However, GER encounters challenges such as fixed N-best hypotheses, insufficient utilization of acoustic information, and limited specificity to multi-accent scenarios. In this paper, we explore the application of GER in multi-accent scenarios. Accents represent deviations from standard pronunciation norms, and the multi-task learning framework for simultaneous ASR and accent recognition (AR) has effectively addressed the multi-accent scenarios, making it a prominent solution. In this work, we propose a unified ASR-AR GER model, named MMGER, leveraging multi-modal correction, and multi-granularity correction. Multi-task ASR-AR learning is employed to provide dynamic 1-best hypotheses and accent embeddings. Multi-modal correction accomplishes fine-grained frame-level correction by force-aligning the acoustic features of speech with the corresponding character-level 1-best hypothesis sequence. Multi-granularity correction supplements the global linguistic information by incorporating regular 1-best hypotheses atop fine-grained multi-modal correction to achieve coarse-grained utterance-level correction. MMGER effectively mitigates the limitations of GER and tailors LLM-based ASR error correction for the multi-accent scenarios. Experiments conducted on the multi-accent Mandarin KeSpeech dataset demonstrate the efficacy of MMGER, achieving a 26.72% relative improvement in AR accuracy and a 27.55% relative reduction in ASR character error rate, compared to a well-established standard baseline.
Enhancing Lip Reading with Multi-Scale Video and Multi-Encoder
Apr 08, 2024
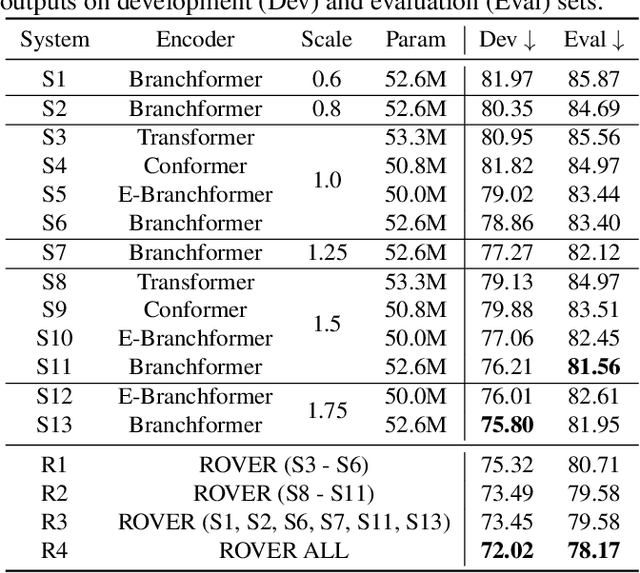
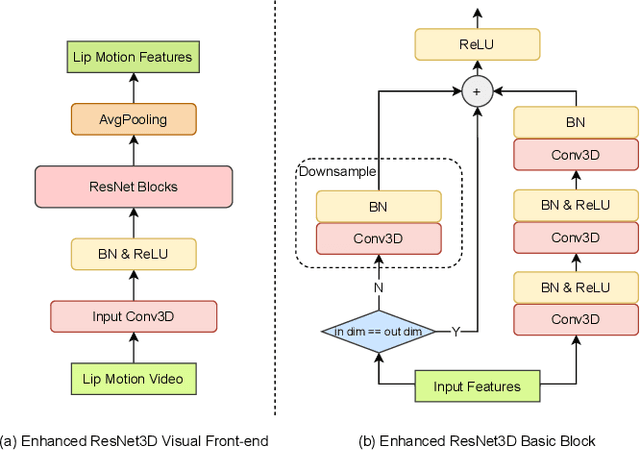
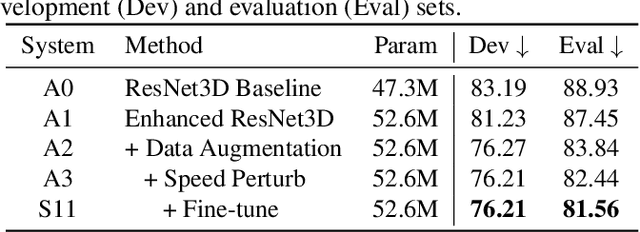
Automatic lip-reading (ALR) aims to automatically transcribe spoken content from a speaker's silent lip motion captured in video. Current mainstream lip-reading approaches only use a single visual encoder to model input videos of a single scale. In this paper, we propose to enhance lipreading by incorporating multi-scale video data and multi-encoder. Specifically, we first propose a novel multi-scale lip extraction algorithm based on the size of the speaker's face and an enhanced ResNet3D visual front-end (VFE) to extract lip features at different scales. For the multi-encoder, in addition to the mainstream Transformer and Conformer, we also incorporate the recently proposed Branchformer and EBranchformer as visual encoders. In the experiments, we explore the influence of different video data scales and encoders on ALR system performance and fuse the texts transcribed by all ALR systems using recognizer output voting error reduction (ROVER). Finally, our proposed approach placed second in the ICME 2024 ChatCLR Challenge Task 2, with a 21.52% reduction in character error rate (CER) compared to the official baseline on the evaluation set.