 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptMID: Modal Invariant Descriptors Based on Diffusion and Vision Foundation Models for Optical-SAR Image Matching
Feb 25, 2025The ideal goal of image matching is to achieve stable and efficient performance in unseen domains. However, many existing learning-based optical-SAR image matching methods, despite their effectiveness in specific scenarios, exhibit limited generalization and struggle to adapt to practical applications. Repeatedly training or fine-tuning matching models to address domain differences is not only not elegant enough but also introduces additional computational overhead and data production costs. In recent years, general foundation models have shown great potential for enhancing generalization. However, the disparity in visual domains between natural and remote sensing images poses challenges for their direct application. Therefore, effectively leveraging foundation models to improve the generalization of optical-SAR image matching remains challenge. To address the above challenges, we propose PromptMID, a novel approach that constructs modality-invariant descriptors using text prompts based on land use classification as priors information for optical and SAR image matching. PromptMID extracts multi-scale modality-invariant features by leveraging pre-trained diffusion models and visual foundation models (VFMs), while specially designed feature aggregation modules effectively fuse features across different granularities. Extensive experiments on optical-SAR image datasets from four diverse regions demonstrate that PromptMID outperforms state-of-the-art matching methods, achieving superior results in both seen and unseen domains and exhibiting strong cross-domain generalization capabilities. The source code will be made publicly available https://github.com/HanNieWHU/PromptMID.
REMM:Rotation-Equivariant Framework for End-to-End Multimodal Image Matching
Jul 16, 2024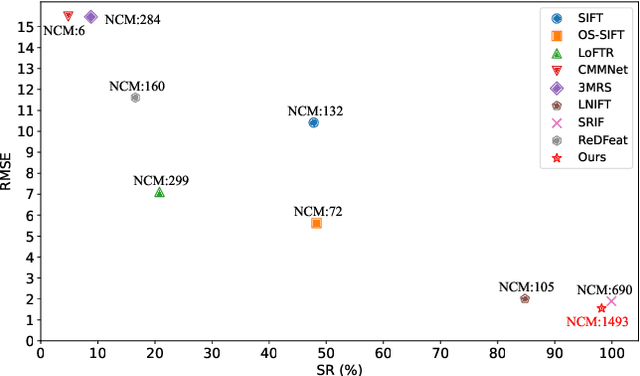



We present REMM, a rotation-equivariant framework for end-to-end multimodal image matching, which fully encodes rotational differences of descriptors in the whole matching pipeline. Previous learning-based methods mainly focus on extracting modal-invariant descriptors, while consistently ignoring the rotational invariance. In this paper, we demonstrate that our REMM is very useful for multimodal image matching, including multimodal feature learning module and cyclic shift module. We first learn modal-invariant features through the multimodal feature learning module. Then, we design the cyclic shift module to rotationally encode the descriptors, greatly improving the performance of rotation-equivariant matching, which makes them robust to any angle. To validate our method, we establish a comprehensive rotation and scale-matching benchmark for evaluating the anti-rotation performance of multimodal images, which contains a combination of multi-angle and multi-scale transformations from four publicly available datasets. Extensive experiments show that our method outperforms existing methods in benchmarking and generalizes well to independent datasets. Additionally, we conducted an in-depth analysis of the key components of the REMM to validate the improvements brought about by the cyclic shift module. Code and dataset at https://github.com/HanNieWHU/REMM.