 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREMM:Rotation-Equivariant Framework for End-to-End Multimodal Image Matching
Paper and Code
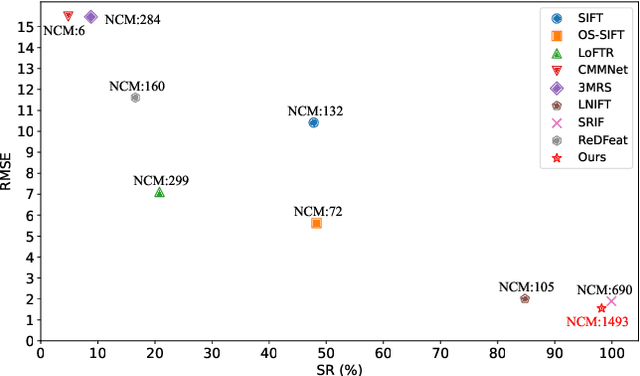



We present REMM, a rotation-equivariant framework for end-to-end multimodal image matching, which fully encodes rotational differences of descriptors in the whole matching pipeline. Previous learning-based methods mainly focus on extracting modal-invariant descriptors, while consistently ignoring the rotational invariance. In this paper, we demonstrate that our REMM is very useful for multimodal image matching, including multimodal feature learning module and cyclic shift module. We first learn modal-invariant features through the multimodal feature learning module. Then, we design the cyclic shift module to rotationally encode the descriptors, greatly improving the performance of rotation-equivariant matching, which makes them robust to any angle. To validate our method, we establish a comprehensive rotation and scale-matching benchmark for evaluating the anti-rotation performance of multimodal images, which contains a combination of multi-angle and multi-scale transformations from four publicly available datasets. Extensive experiments show that our method outperforms existing methods in benchmarking and generalizes well to independent datasets. Additionally, we conducted an in-depth analysis of the key components of the REMM to validate the improvements brought about by the cyclic shift module. Code and dataset at https://github.com/HanNieWHU/REMM.