 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPEN: Object-wise Position Embedding for Multi-view 3D Object Detection
Jul 15, 2024



Accurate depth information is crucial for enhancing the performance of multi-view 3D object detection. Despite the success of some existing multi-view 3D detectors utilizing pixel-wise depth supervision, they overlook two significant phenomena: 1) the depth supervision obtained from LiDAR points is usually distributed on the surface of the object, which is not so friendly to existing DETR-based 3D detectors due to the lack of the depth of 3D object center; 2) for distant objects, fine-grained depth estimation of the whole object is more challenging. Therefore, we argue that the object-wise depth (or 3D center of the object) is essential for accurate detection. In this paper, we propose a new multi-view 3D object detector named OPEN, whose main idea is to effectively inject object-wise depth information into the network through our proposed object-wise position embedding. Specifically, we first employ an object-wise depth encoder, which takes the pixel-wise depth map as a prior, to accurately estimate the object-wise depth. Then, we utilize the proposed object-wise position embedding to encode the object-wise depth information into the transformer decoder, thereby producing 3D object-aware features for final detection. Extensive experiments verify the effectiveness of our proposed method. Furthermore, OPEN achieves a new state-of-the-art performance with 64.4% NDS and 56.7% mAP on the nuScenes test benchmark.
BEVWorld: A Multimodal World Model for Autonomous Driving via Unified BEV Latent Space
Jul 08, 2024



World models are receiving increasing attention in autonomous driving for their ability to predict potential future scenarios. In this paper, we present BEVWorld, a novel approach that tokenizes multimodal sensor inputs into a unified and compact Bird's Eye View (BEV) latent space for environment modeling. The world model consists of two parts: the multi-modal tokenizer and the latent BEV sequence diffusion model. The multi-modal tokenizer first encodes multi-modality information and the decoder is able to reconstruct the latent BEV tokens into LiDAR and image observations by ray-casting rendering in a self-supervised manner. Then the latent BEV sequence diffusion model predicts future scenarios given action tokens as conditions. Experiments demonstrate the effectiveness of BEVWorld in autonomous driving tasks, showcasing its capability in generating future scenes and benefiting downstream tasks such as perception and motion prediction. Code will be available at https://github.com/zympsyche/BevWorld.
Exploiting Low-level Representations for Ultra-Fast Road Segmentation
Feb 06, 2024



Achieving real-time and accuracy on embedded platforms has always been the pursuit of road segmentation methods. To this end, they have proposed many lightweight networks. However, they ignore the fact that roads are "stuff" (background or environmental elements) rather than "things" (specific identifiable objects), which inspires us to explore the feasibility of representing roads with low-level instead of high-level features. Surprisingly, we find that the primary stage of mainstream network models is sufficient to represent most pixels of the road for segmentation. Motivated by this, we propose a Low-level Feature Dominated Road Segmentation network (LFD-RoadSeg). Specifically, LFD-RoadSeg employs a bilateral structure. The spatial detail branch is firstly designed to extract low-level feature representation for the road by the first stage of ResNet-18. To suppress texture-less regions mistaken as the road in the low-level feature, the context semantic branch is then designed to extract the context feature in a fast manner. To this end, in the second branch, we asymmetrically downsample the input image and design an aggregation module to achieve comparable receptive fields to the third stage of ResNet-18 but with less time consumption. Finally, to segment the road from the low-level feature, a selective fusion module is proposed to calculate pixel-wise attention between the low-level representation and context feature, and suppress the non-road low-level response by this attention. On KITTI-Road, LFD-RoadSeg achieves a maximum F1-measure (MaxF) of 95.21% and an average precision of 93.71%, while reaching 238 FPS on a single TITAN Xp and 54 FPS on a Jetson TX2, all with a compact model size of just 936k parameters. The source code is available at https://github.com/zhouhuan-hust/LFD-RoadSeg.
CAPE: Camera View Position Embedding for Multi-View 3D Object Detection
Mar 17, 2023In this paper, we address the problem of detecting 3D objects from multi-view images. Current query-based methods rely on global 3D position embeddings (PE) to learn the geometric correspondence between images and 3D space. We claim that directly interacting 2D image features with global 3D PE could increase the difficulty of learning view transformation due to the variation of camera extrinsics. Thus we propose a novel method based on CAmera view Position Embedding, called CAPE. We form the 3D position embeddings under the local camera-view coordinate system instead of the global coordinate system, such that 3D position embedding is free of encoding camera extrinsic parameters. Furthermore, we extend our CAPE to temporal modeling by exploiting the object queries of previous frames and encoding the ego-motion for boosting 3D object detection. CAPE achieves state-of-the-art performance (61.0% NDS and 52.5% mAP) among all LiDAR-free methods on nuScenes dataset. Codes and models are available on \href{https://github.com/PaddlePaddle/Paddle3D}{Paddle3D} and \href{https://github.com/kaixinbear/CAPE}{PyTorch Implementation}.
GitNet: Geometric Prior-based Transformation for Birds-Eye-View Segmentation
Apr 16, 2022



Birds-eye-view (BEV) semantic segmentation is critical for autonomous driving for its powerful spatial representation ability. It is challenging to estimate the BEV semantic maps from monocular images due to the spatial gap, since it is implicitly required to realize both the perspective-to-BEV transformation and segmentation. We present a novel two-stage Geometry Prior-based Transformation framework named GitNet, consisting of (i) the geometry-guided pre-alignment and (ii) ray-based transformer. In the first stage, we decouple the BEV segmentation into the perspective image segmentation and geometric prior-based mapping, with explicit supervision by projecting the BEV semantic labels onto the image plane to learn visibility-aware features and learnable geometry to translate into BEV space. Second, the pre-aligned coarse BEV features are further deformed by ray-based transformers to take visibility knowledge into account. GitNet achieves the leading performance on the challenging nuScenes and Argoverse Datasets. The code will be publicly available.
Anomaly Discovery in Semantic Segmentation via Distillation Comparison Networks
Dec 18, 2021
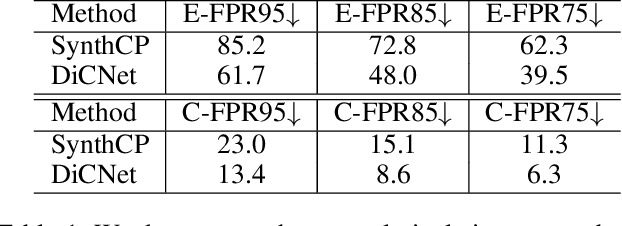
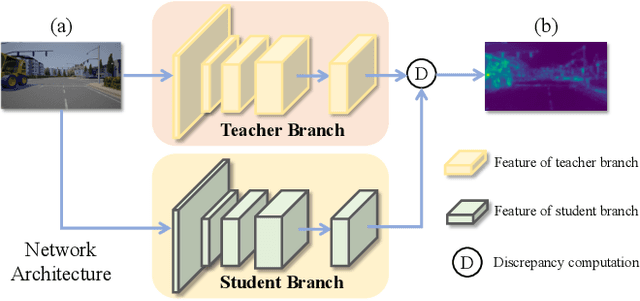

This paper aims to address the problem of anomaly discovery in semantic segmentation. Our key observation is that semantic classification plays a critical role in existing approaches, while the incorrectly classified pixels are easily regarded as anomalies. Such a phenomenon frequently appears and is rarely discussed, which significantly reduces the performance of anomaly discovery. To this end, we propose a novel Distillation Comparison Network (DiCNet). It comprises of a teacher branch which is a semantic segmentation network that removed the semantic classification head, and a student branch that is distilled from the teacher branch through a distribution distillation. We show that the distillation guarantees the semantic features of the two branches hold consistency in the known classes, while reflect inconsistency in the unknown class. Therefore, we leverage the semantic feature discrepancy between the two branches to discover the anomalies. DiCNet abandons the semantic classification head in the inference process, and hence significantly alleviates the issue caused by incorrect semantic classification. Extensive experimental results on StreetHazards dataset and BDD-Anomaly dataset are conducted to verify the superior performance of DiCNet. In particular, DiCNet obtains a 6.3% improvement in AUPR and a 5.2% improvement in FPR95 on StreetHazards dataset, achieves a 4.2% improvement in AUPR and a 6.8% improvement in FPR95 on BDD-Anomaly dataset. Codes are available at https://github.com/zhouhuan-hust/DiCNet.