 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDriveVLA: Unifying Understanding, Perception, and Action Planning for Autonomous Driving
Apr 02, 2026Vision-Language-Action (VLA) models have recently emerged in autonomous driving, with the promise of leveraging rich world knowledge to improve the cognitive capabilities of driving systems. However, adapting such models for driving tasks currently faces a critical dilemma between spatial perception and semantic reasoning. Consequently, existing VLA systems are forced into suboptimal compromises: directly adopting 2D Vision-Language Models yields limited spatial perception, whereas enhancing them with 3D spatial representations often impairs the native reasoning capacity of VLMs. We argue that this dilemma largely stems from the coupled optimization of spatial perception and semantic reasoning within shared model parameters. To overcome this, we propose UniDriveVLA, a Unified Driving Vision-Language-Action model based on Mixture-of-Transformers that addresses the perception-reasoning conflict via expert decoupling. Specifically, it comprises three experts for driving understanding, scene perception, and action planning, which are coordinated through masked joint attention. In addition, we combine a sparse perception paradigm with a three-stage progressive training strategy to improve spatial perception while maintaining semantic reasoning capability. Extensive experiments show that UniDriveVLA achieves state-of-the-art performance in open-loop evaluation on nuScenes and closed-loop evaluation on Bench2Drive. Moreover, it demonstrates strong performance across a broad range of perception, prediction, and understanding tasks, including 3D detection, online mapping, motion forecasting, and driving-oriented VQA, highlighting its broad applicability as a unified model for autonomous driving. Code and model have been released at https://github.com/xiaomi-research/unidrivevla
DriveLaW:Unifying Planning and Video Generation in a Latent Driving World
Dec 31, 2025World models have become crucial for autonomous driving, as they learn how scenarios evolve over time to address the long-tail challenges of the real world. However, current approaches relegate world models to limited roles: they operate within ostensibly unified architectures that still keep world prediction and motion planning as decoupled processes. To bridge this gap, we propose DriveLaW, a novel paradigm that unifies video generation and motion planning. By directly injecting the latent representation from its video generator into the planner, DriveLaW ensures inherent consistency between high-fidelity future generation and reliable trajectory planning. Specifically, DriveLaW consists of two core components: DriveLaW-Video, our powerful world model that generates high-fidelity forecasting with expressive latent representations, and DriveLaW-Act, a diffusion planner that generates consistent and reliable trajectories from the latent of DriveLaW-Video, with both components optimized by a three-stage progressive training strategy. The power of our unified paradigm is demonstrated by new state-of-the-art results across both tasks. DriveLaW not only advances video prediction significantly, surpassing best-performing work by 33.3% in FID and 1.8% in FVD, but also achieves a new record on the NAVSIM planning benchmark.
Rethinking Driving World Model as Synthetic Data Generator for Perception Tasks
Oct 22, 2025Recent advancements in driving world models enable controllable generation of high-quality RGB videos or multimodal videos. Existing methods primarily focus on metrics related to generation quality and controllability. However, they often overlook the evaluation of downstream perception tasks, which are $\mathbf{really\ crucial}$ for the performance of autonomous driving. Existing methods usually leverage a training strategy that first pretrains on synthetic data and finetunes on real data, resulting in twice the epochs compared to the baseline (real data only). When we double the epochs in the baseline, the benefit of synthetic data becomes negligible. To thoroughly demonstrate the benefit of synthetic data, we introduce Dream4Drive, a novel synthetic data generation framework designed for enhancing the downstream perception tasks. Dream4Drive first decomposes the input video into several 3D-aware guidance maps and subsequently renders the 3D assets onto these guidance maps. Finally, the driving world model is fine-tuned to produce the edited, multi-view photorealistic videos, which can be used to train the downstream perception models. Dream4Drive enables unprecedented flexibility in generating multi-view corner cases at scale, significantly boosting corner case perception in autonomous driving. To facilitate future research, we also contribute a large-scale 3D asset dataset named DriveObj3D, covering the typical categories in driving scenarios and enabling diverse 3D-aware video editing. We conduct comprehensive experiments to show that Dream4Drive can effectively boost the performance of downstream perception models under various training epochs. Project: $\href{https://wm-research.github.io/Dream4Drive/}{this\ https\ URL}$
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
Jun 09, 2025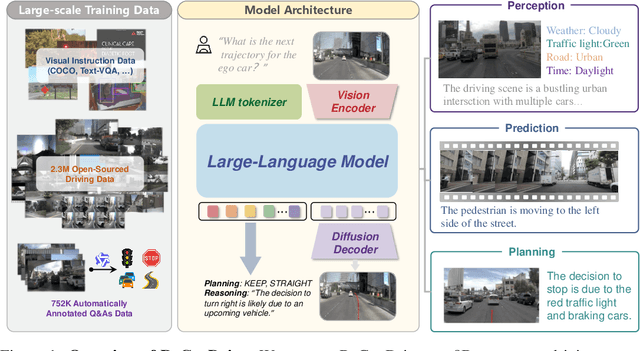
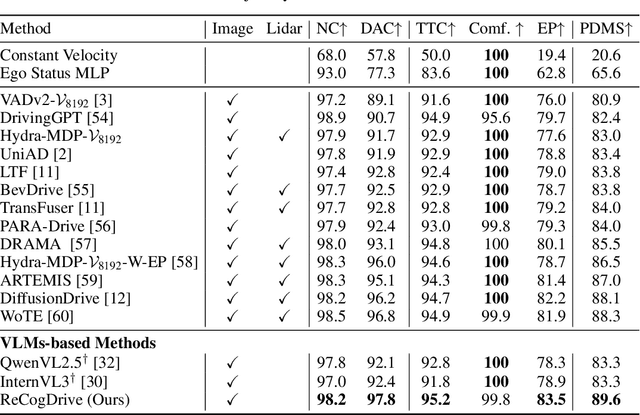
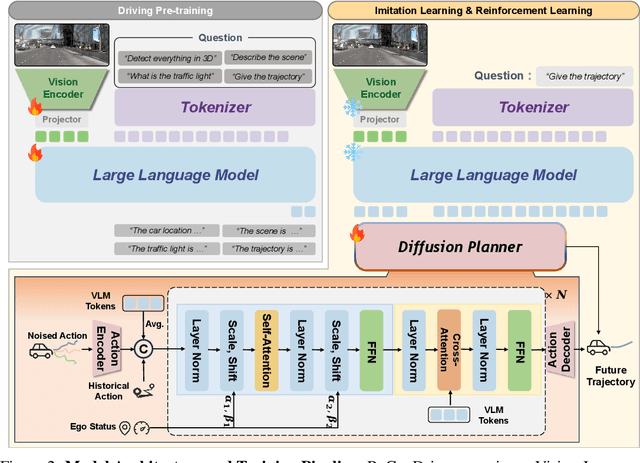
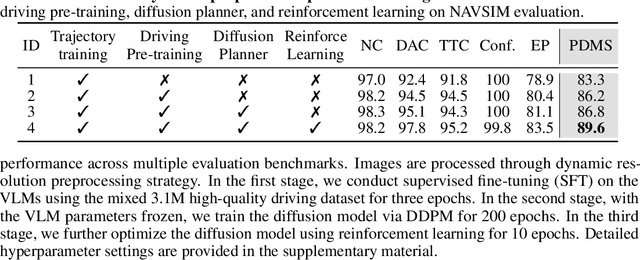
Although end-to-end autonomous driving has made remarkable progress, its performance degrades significantly in rare and long-tail scenarios. Recent approaches attempt to address this challenge by leveraging the rich world knowledge of Vision-Language Models (VLMs), but these methods suffer from several limitations: (1) a significant domain gap between the pre-training data of VLMs and real-world driving data, (2) a dimensionality mismatch between the discrete language space and the continuous action space, and (3) imitation learning tends to capture the average behavior present in the dataset, which may be suboptimal even dangerous. In this paper, we propose ReCogDrive, an autonomous driving system that integrates VLMs with diffusion planner, which adopts a three-stage paradigm for training. In the first stage, we use a large-scale driving question-answering datasets to train the VLMs, mitigating the domain discrepancy between generic content and real-world driving scenarios. In the second stage, we employ a diffusion-based planner to perform imitation learning, mapping representations from the latent language space to continuous driving actions. Finally, we fine-tune the diffusion planner using reinforcement learning with NAVSIM non-reactive simulator, enabling the model to generate safer, more human-like driving trajectories. We evaluate our approach on the planning-oriented NAVSIM benchmark, achieving a PDMS of 89.6 and setting a new state-of-the-art that surpasses the previous vision-only SOTA by 5.6 PDMS.
Genesis: Multimodal Driving Scene Generation with Spatio-Temporal and Cross-Modal Consistency
Jun 09, 2025We present Genesis, a unified framework for joint generation of multi-view driving videos and LiDAR sequences with spatio-temporal and cross-modal consistency. Genesis employs a two-stage architecture that integrates a DiT-based video diffusion model with 3D-VAE encoding, and a BEV-aware LiDAR generator with NeRF-based rendering and adaptive sampling. Both modalities are directly coupled through a shared latent space, enabling coherent evolution across visual and geometric domains. To guide the generation with structured semantics, we introduce DataCrafter, a captioning module built on vision-language models that provides scene-level and instance-level supervision. Extensive experiments on the nuScenes benchmark demonstrate that Genesis achieves state-of-the-art performance across video and LiDAR metrics (FVD 16.95, FID 4.24, Chamfer 0.611), and benefits downstream tasks including segmentation and 3D detection, validating the semantic fidelity and practical utility of the generated data.
CoGen: 3D Consistent Video Generation via Adaptive Conditioning for Autonomous Driving
Mar 28, 2025Recent progress in driving video generation has shown significant potential for enhancing self-driving systems by providing scalable and controllable training data. Although pretrained state-of-the-art generation models, guided by 2D layout conditions (e.g., HD maps and bounding boxes), can produce photorealistic driving videos, achieving controllable multi-view videos with high 3D consistency remains a major challenge. To tackle this, we introduce a novel spatial adaptive generation framework, CoGen, which leverages advances in 3D generation to improve performance in two key aspects: (i) To ensure 3D consistency, we first generate high-quality, controllable 3D conditions that capture the geometry of driving scenes. By replacing coarse 2D conditions with these fine-grained 3D representations, our approach significantly enhances the spatial consistency of the generated videos. (ii) Additionally, we introduce a consistency adapter module to strengthen the robustness of the model to multi-condition control. The results demonstrate that this method excels in preserving geometric fidelity and visual realism, offering a reliable video generation solution for autonomous driving.
BEVWorld: A Multimodal World Model for Autonomous Driving via Unified BEV Latent Space
Jul 08, 2024



World models are receiving increasing attention in autonomous driving for their ability to predict potential future scenarios. In this paper, we present BEVWorld, a novel approach that tokenizes multimodal sensor inputs into a unified and compact Bird's Eye View (BEV) latent space for environment modeling. The world model consists of two parts: the multi-modal tokenizer and the latent BEV sequence diffusion model. The multi-modal tokenizer first encodes multi-modality information and the decoder is able to reconstruct the latent BEV tokens into LiDAR and image observations by ray-casting rendering in a self-supervised manner. Then the latent BEV sequence diffusion model predicts future scenarios given action tokens as conditions. Experiments demonstrate the effectiveness of BEVWorld in autonomous driving tasks, showcasing its capability in generating future scenes and benefiting downstream tasks such as perception and motion prediction. Code will be available at https://github.com/zympsyche/BevWorld.
You Only Look Bottom-Up for Monocular 3D Object Detection
Jan 27, 2024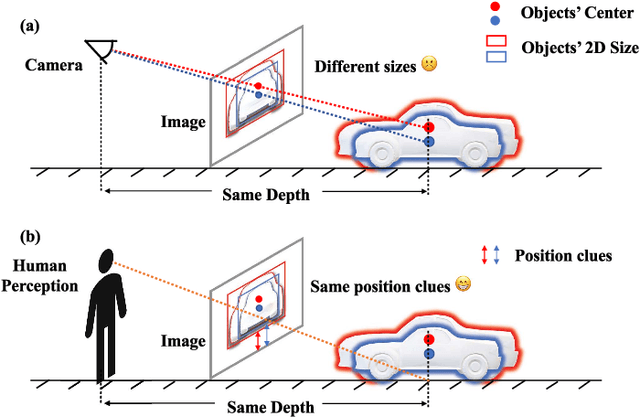
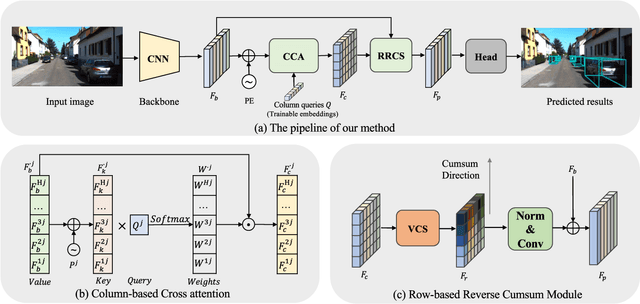
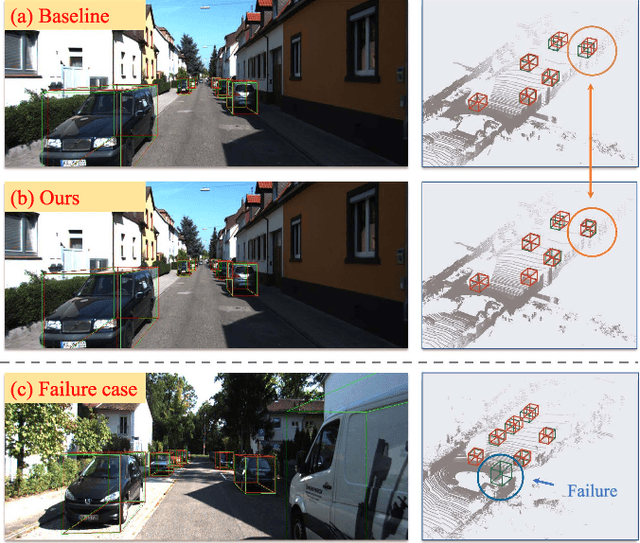
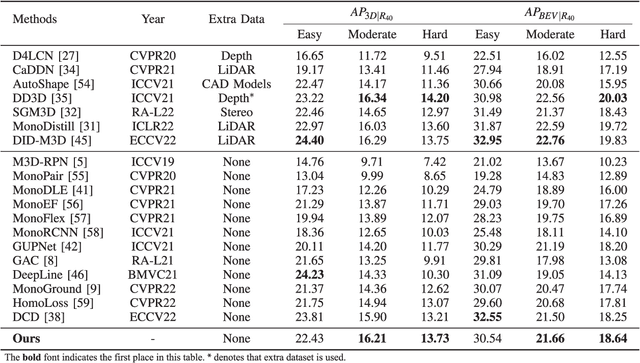
Monocular 3D Object Detection is an essential task for autonomous driving. Meanwhile, accurate 3D object detection from pure images is very challenging due to the loss of depth information. Most existing image-based methods infer objects' location in 3D space based on their 2D sizes on the image plane, which usually ignores the intrinsic position clues from images, leading to unsatisfactory performances. Motivated by the fact that humans could leverage the bottom-up positional clues to locate objects in 3D space from a single image, in this paper, we explore the position modeling from the image feature column and propose a new method named You Only Look Bottum-Up (YOLOBU). Specifically, our YOLOBU leverages Column-based Cross Attention to determine how much a pixel contributes to pixels above it. Next, the Row-based Reverse Cumulative Sum (RRCS) is introduced to build the connections of pixels in the bottom-up direction. Our YOLOBU fully explores the position clues for monocular 3D detection via building the relationship of pixels from the bottom-up way. Extensive experiments on the KITTI dataset demonstrate the effectiveness and superiority of our method.
CAPE: Camera View Position Embedding for Multi-View 3D Object Detection
Mar 17, 2023In this paper, we address the problem of detecting 3D objects from multi-view images. Current query-based methods rely on global 3D position embeddings (PE) to learn the geometric correspondence between images and 3D space. We claim that directly interacting 2D image features with global 3D PE could increase the difficulty of learning view transformation due to the variation of camera extrinsics. Thus we propose a novel method based on CAmera view Position Embedding, called CAPE. We form the 3D position embeddings under the local camera-view coordinate system instead of the global coordinate system, such that 3D position embedding is free of encoding camera extrinsic parameters. Furthermore, we extend our CAPE to temporal modeling by exploiting the object queries of previous frames and encoding the ego-motion for boosting 3D object detection. CAPE achieves state-of-the-art performance (61.0% NDS and 52.5% mAP) among all LiDAR-free methods on nuScenes dataset. Codes and models are available on \href{https://github.com/PaddlePaddle/Paddle3D}{Paddle3D} and \href{https://github.com/kaixinbear/CAPE}{PyTorch Implementation}.