 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Look Bottom-Up for Monocular 3D Object Detection
Jan 27, 2024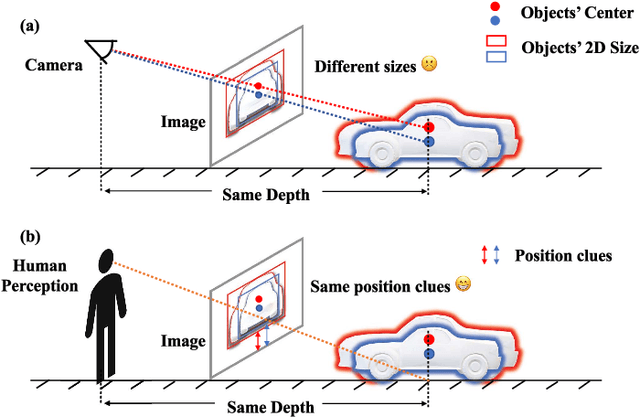
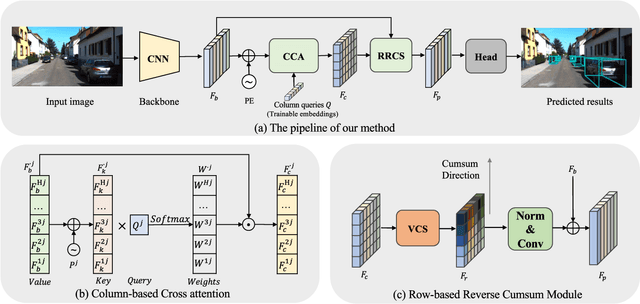
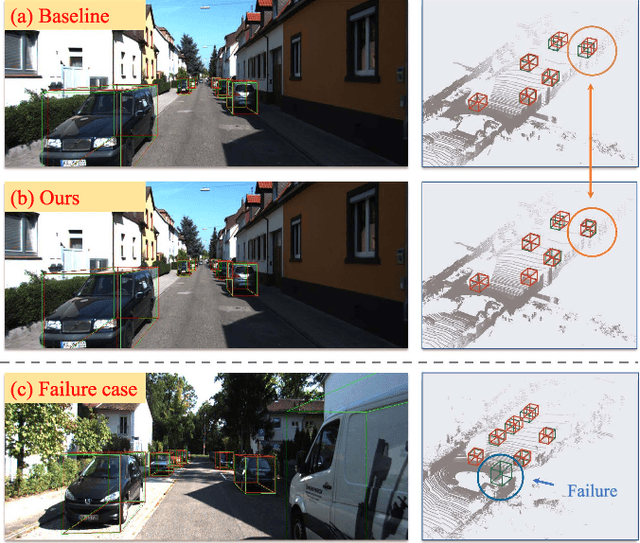
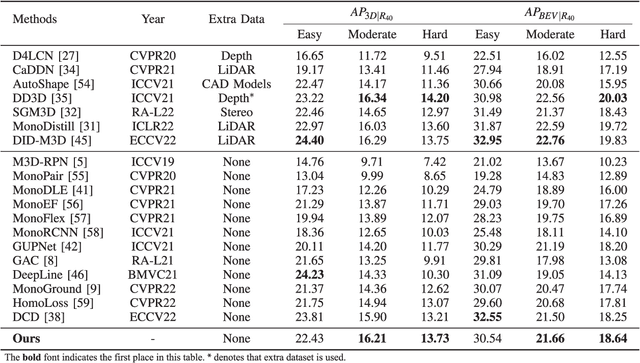
Monocular 3D Object Detection is an essential task for autonomous driving. Meanwhile, accurate 3D object detection from pure images is very challenging due to the loss of depth information. Most existing image-based methods infer objects' location in 3D space based on their 2D sizes on the image plane, which usually ignores the intrinsic position clues from images, leading to unsatisfactory performances. Motivated by the fact that humans could leverage the bottom-up positional clues to locate objects in 3D space from a single image, in this paper, we explore the position modeling from the image feature column and propose a new method named You Only Look Bottum-Up (YOLOBU). Specifically, our YOLOBU leverages Column-based Cross Attention to determine how much a pixel contributes to pixels above it. Next, the Row-based Reverse Cumulative Sum (RRCS) is introduced to build the connections of pixels in the bottom-up direction. Our YOLOBU fully explores the position clues for monocular 3D detection via building the relationship of pixels from the bottom-up way. Extensive experiments on the KITTI dataset demonstrate the effectiveness and superiority of our method.
Diffusion-based 3D Object Detection with Random Boxes
Sep 05, 2023



3D object detection is an essential task for achieving autonomous driving. Existing anchor-based detection methods rely on empirical heuristics setting of anchors, which makes the algorithms lack elegance. In recent years, we have witnessed the rise of several generative models, among which diffusion models show great potential for learning the transformation of two distributions. Our proposed Diff3Det migrates the diffusion model to proposal generation for 3D object detection by considering the detection boxes as generative targets. During training, the object boxes diffuse from the ground truth boxes to the Gaussian distribution, and the decoder learns to reverse this noise process. In the inference stage, the model progressively refines a set of random boxes to the prediction results. We provide detailed experiments on the KITTI benchmark and achieve promising performance compared to classical anchor-based 3D detection methods.