 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVS-Net: Point Sampling with Adaptive Voxel Size for 3D Point Cloud Analysis
Feb 27, 2024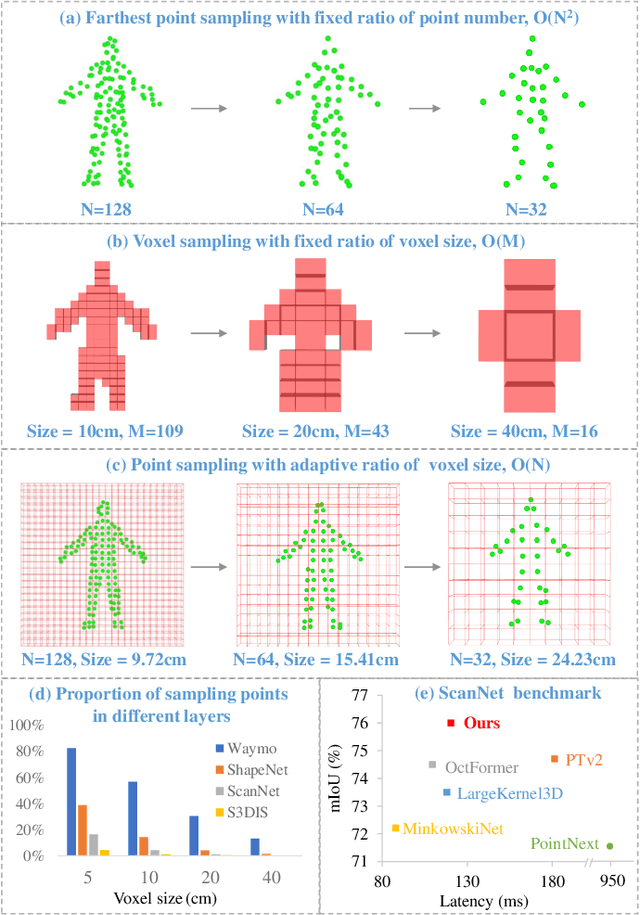
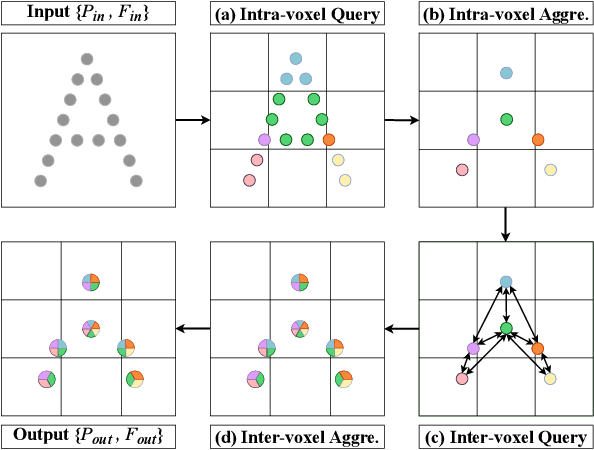
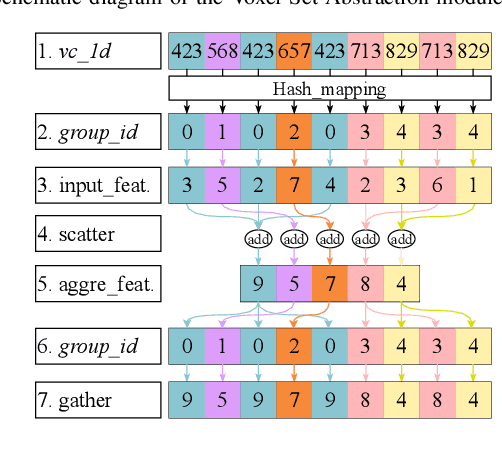
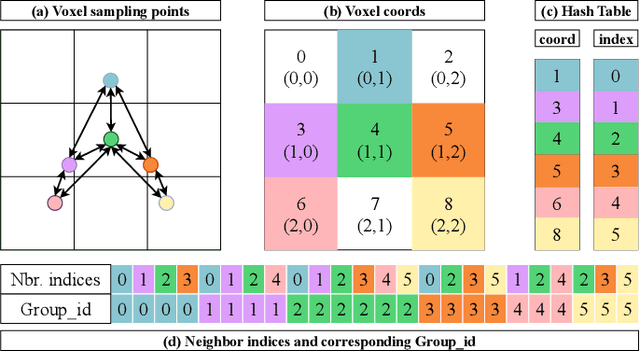
Efficient downsampling plays a crucial role in point cloud learning, particularly for large-scale 3D scenes. Existing downsampling methods either require a huge computational burden or sacrifice fine-grained geometric information. This paper presents an advanced sampler that achieves both high accuracy and efficiency. The proposed method utilizes voxel-based sampling as a foundation, but effectively addresses the challenges regarding voxel size determination and the preservation of critical geometric cues. Specifically, we propose a Voxel Adaptation Module that adaptively adjusts voxel sizes with the reference of point-based downsampling ratio. This ensures the sampling results exhibit a favorable distribution for comprehending various 3D objects or scenes. Additionally, we introduce a network compatible with arbitrary voxel sizes for sampling and feature extraction while maintaining high efficiency. Our method achieves state-of-the-art accuracy on the ShapeNetPart and ScanNet benchmarks with promising efficiency. Code will be available at https://github.com/yhc2021/AVS-Net.
You Only Look Bottom-Up for Monocular 3D Object Detection
Jan 27, 2024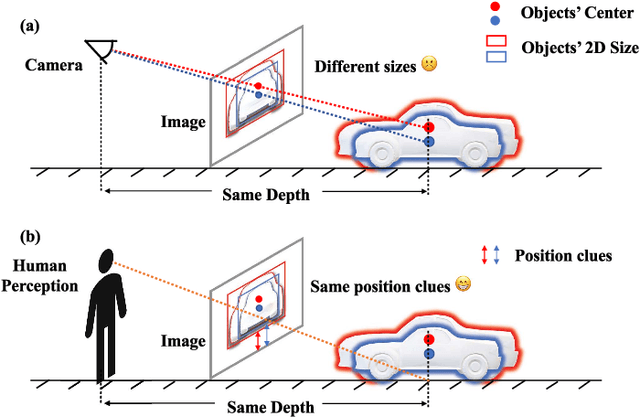
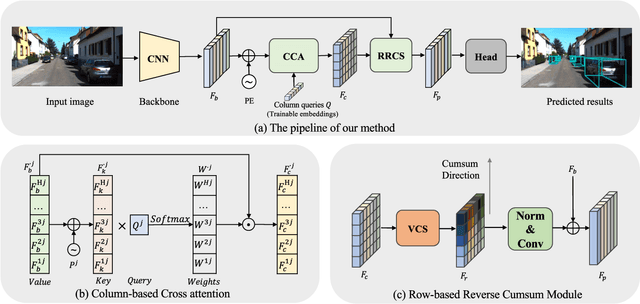
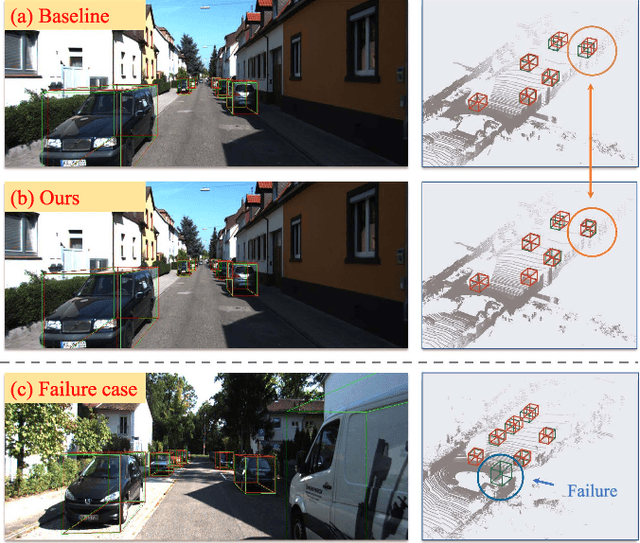
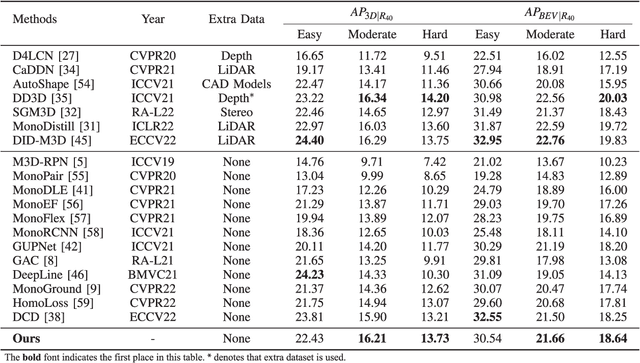
Monocular 3D Object Detection is an essential task for autonomous driving. Meanwhile, accurate 3D object detection from pure images is very challenging due to the loss of depth information. Most existing image-based methods infer objects' location in 3D space based on their 2D sizes on the image plane, which usually ignores the intrinsic position clues from images, leading to unsatisfactory performances. Motivated by the fact that humans could leverage the bottom-up positional clues to locate objects in 3D space from a single image, in this paper, we explore the position modeling from the image feature column and propose a new method named You Only Look Bottum-Up (YOLOBU). Specifically, our YOLOBU leverages Column-based Cross Attention to determine how much a pixel contributes to pixels above it. Next, the Row-based Reverse Cumulative Sum (RRCS) is introduced to build the connections of pixels in the bottom-up direction. Our YOLOBU fully explores the position clues for monocular 3D detection via building the relationship of pixels from the bottom-up way. Extensive experiments on the KITTI dataset demonstrate the effectiveness and superiority of our method.
SAM3D: Zero-Shot 3D Object Detection via Segment Anything Model
Jun 04, 2023With the development of large language models, many remarkable linguistic systems like ChatGPT have thrived and achieved astonishing success on many tasks, showing the incredible power of foundation models. In the spirit of unleashing the capability of foundation models on vision tasks, the Segment Anything Model (SAM), a vision foundation model for image segmentation, has been proposed recently and presents strong zero-shot ability on many downstream 2D tasks. However, whether SAM can be adapted to 3D vision tasks has yet to be explored, especially 3D object detection. With this inspiration, we explore adapting the zero-shot ability of SAM to 3D object detection in this paper. We propose a SAM-powered BEV processing pipeline to detect objects and get promising results on the large-scale Waymo open dataset. As an early attempt, our method takes a step toward 3D object detection with vision foundation models and presents the opportunity to unleash their power on 3D vision tasks. The code is released at https://github.com/DYZhang09/SAM3D.