 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAUTILUS: A Large Multimodal Model for Underwater Scene Understanding
Oct 31, 2025Underwater exploration offers critical insights into our planet and attracts increasing attention for its broader applications in resource exploration, national security, etc. We study the underwater scene understanding methods, which aim to achieve automated underwater exploration. The underwater scene understanding task demands multi-task perceptions from multiple granularities. However, the absence of large-scale underwater multi-task instruction-tuning datasets hinders the progress of this research. To bridge this gap, we construct NautData, a dataset containing 1.45 M image-text pairs supporting eight underwater scene understanding tasks. It enables the development and thorough evaluation of the underwater scene understanding models. Underwater image degradation is a widely recognized challenge that interferes with underwater tasks. To improve the robustness of underwater scene understanding, we introduce physical priors derived from underwater imaging models and propose a plug-and-play vision feature enhancement (VFE) module, which explicitly restores clear underwater information. We integrate this module into renowned baselines LLaVA-1.5 and Qwen2.5-VL and build our underwater LMM, NAUTILUS. Experiments conducted on the NautData and public underwater datasets demonstrate the effectiveness of the VFE module, consistently improving the performance of both baselines on the majority of supported tasks, thus ensuring the superiority of NAUTILUS in the underwater scene understanding area. Data and models are available at https://github.com/H-EmbodVis/NAUTILUS.
Deep Learning Reforms Image Matching: A Survey and Outlook
Jun 05, 2025Image matching, which establishes correspondences between two-view images to recover 3D structure and camera geometry, serves as a cornerstone in computer vision and underpins a wide range of applications, including visual localization, 3D reconstruction, and simultaneous localization and mapping (SLAM). Traditional pipelines composed of ``detector-descriptor, feature matcher, outlier filter, and geometric estimator'' falter in challenging scenarios. Recent deep-learning advances have significantly boosted both robustness and accuracy. This survey adopts a unique perspective by comprehensively reviewing how deep learning has incrementally transformed the classical image matching pipeline. Our taxonomy highly aligns with the traditional pipeline in two key aspects: i) the replacement of individual steps in the traditional pipeline with learnable alternatives, including learnable detector-descriptor, outlier filter, and geometric estimator; and ii) the merging of multiple steps into end-to-end learnable modules, encompassing middle-end sparse matcher, end-to-end semi-dense/dense matcher, and pose regressor. We first examine the design principles, advantages, and limitations of both aspects, and then benchmark representative methods on relative pose recovery, homography estimation, and visual localization tasks. Finally, we discuss open challenges and outline promising directions for future research. By systematically categorizing and evaluating deep learning-driven strategies, this survey offers a clear overview of the evolving image matching landscape and highlights key avenues for further innovation.
You Only Look One Step: Accelerating Backpropagation in Diffusion Sampling with Gradient Shortcuts
May 12, 2025Diffusion models (DMs) have recently demonstrated remarkable success in modeling large-scale data distributions. However, many downstream tasks require guiding the generated content based on specific differentiable metrics, typically necessitating backpropagation during the generation process. This approach is computationally expensive, as generating with DMs often demands tens to hundreds of recursive network calls, resulting in high memory usage and significant time consumption. In this paper, we propose a more efficient alternative that approaches the problem from the perspective of parallel denoising. We show that full backpropagation throughout the entire generation process is unnecessary. The downstream metrics can be optimized by retaining the computational graph of only one step during generation, thus providing a shortcut for gradient propagation. The resulting method, which we call Shortcut Diffusion Optimization (SDO), is generic, high-performance, and computationally lightweight, capable of optimizing all parameter types in diffusion sampling. We demonstrate the effectiveness of SDO on several real-world tasks, including controlling generation by optimizing latent and aligning the DMs by fine-tuning network parameters. Compared to full backpropagation, our approach reduces computational costs by $\sim 90\%$ while maintaining superior performance. Code is available at https://github.com/deng-ai-lab/SDO.
Image Restoration via Multi-domain Learning
May 07, 2025



Due to adverse atmospheric and imaging conditions, natural images suffer from various degradation phenomena. Consequently, image restoration has emerged as a key solution and garnered substantial attention. Although recent Transformer architectures have demonstrated impressive success across various restoration tasks, their considerable model complexity poses significant challenges for both training and real-time deployment. Furthermore, instead of investigating the commonalities among different degradations, most existing restoration methods focus on modifying Transformer under limited restoration priors. In this work, we first review various degradation phenomena under multi-domain perspective, identifying common priors. Then, we introduce a novel restoration framework, which integrates multi-domain learning into Transformer. Specifically, in Token Mixer, we propose a Spatial-Wavelet-Fourier multi-domain structure that facilitates local-region-global multi-receptive field modeling to replace vanilla self-attention. Additionally, in Feed-Forward Network, we incorporate multi-scale learning to fuse multi-domain features at different resolutions. Comprehensive experimental results across ten restoration tasks, such as dehazing, desnowing, motion deblurring, defocus deblurring, rain streak/raindrop removal, cloud removal, shadow removal, underwater enhancement and low-light enhancement, demonstrate that our proposed model outperforms state-of-the-art methods and achieves a favorable trade-off among restoration performance, parameter size, computational cost and inference latency. The code is available at: https://github.com/deng-ai-lab/SWFormer.
MINIMA: Modality Invariant Image Matching
Dec 27, 2024



Image matching for both cross-view and cross-modality plays a critical role in multimodal perception. In practice, the modality gap caused by different imaging systems/styles poses great challenges to the matching task. Existing works try to extract invariant features for specific modalities and train on limited datasets, showing poor generalization. In this paper, we present MINIMA, a unified image matching framework for multiple cross-modal cases. Without pursuing fancy modules, our MINIMA aims to enhance universal performance from the perspective of data scaling up. For such purpose, we propose a simple yet effective data engine that can freely produce a large dataset containing multiple modalities, rich scenarios, and accurate matching labels. Specifically, we scale up the modalities from cheap but rich RGB-only matching data, by means of generative models. Under this setting, the matching labels and rich diversity of the RGB dataset are well inherited by the generated multimodal data. Benefiting from this, we construct MD-syn, a new comprehensive dataset that fills the data gap for general multimodal image matching. With MD-syn, we can directly train any advanced matching pipeline on randomly selected modality pairs to obtain cross-modal ability. Extensive experiments on in-domain and zero-shot matching tasks, including $19$ cross-modal cases, demonstrate that our MINIMA can significantly outperform the baselines and even surpass modality-specific methods. The dataset and code are available at https://github.com/LSXI7/MINIMA .
AVS-Net: Point Sampling with Adaptive Voxel Size for 3D Point Cloud Analysis
Feb 27, 2024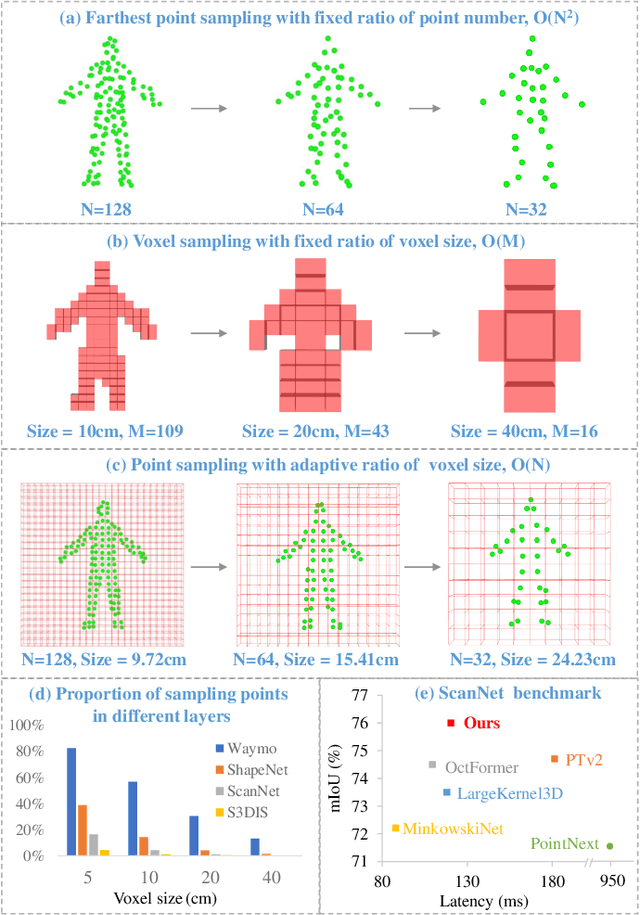
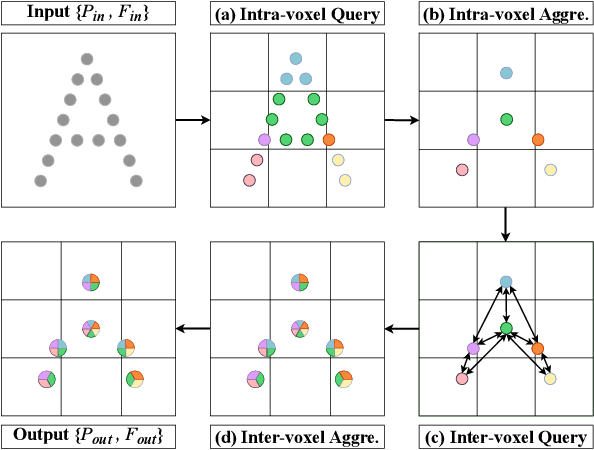
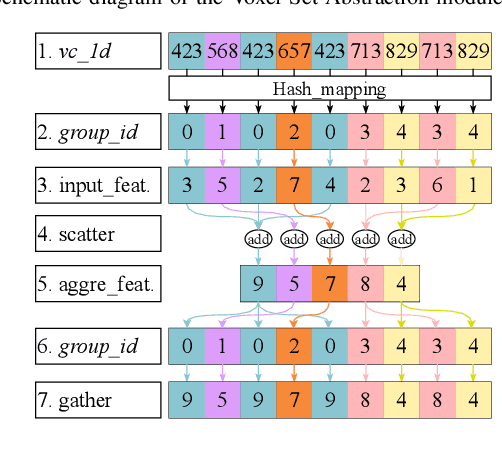
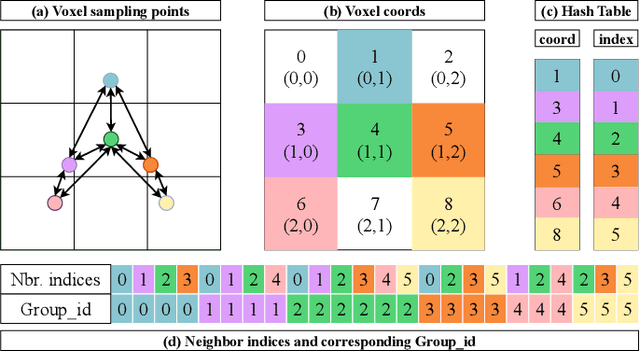
Efficient downsampling plays a crucial role in point cloud learning, particularly for large-scale 3D scenes. Existing downsampling methods either require a huge computational burden or sacrifice fine-grained geometric information. This paper presents an advanced sampler that achieves both high accuracy and efficiency. The proposed method utilizes voxel-based sampling as a foundation, but effectively addresses the challenges regarding voxel size determination and the preservation of critical geometric cues. Specifically, we propose a Voxel Adaptation Module that adaptively adjusts voxel sizes with the reference of point-based downsampling ratio. This ensures the sampling results exhibit a favorable distribution for comprehending various 3D objects or scenes. Additionally, we introduce a network compatible with arbitrary voxel sizes for sampling and feature extraction while maintaining high efficiency. Our method achieves state-of-the-art accuracy on the ShapeNetPart and ScanNet benchmarks with promising efficiency. Code will be available at https://github.com/yhc2021/AVS-Net.
DG-Labeler and DGL-MOTS Dataset: Boost the Autonomous Driving Perception
Oct 15, 2021
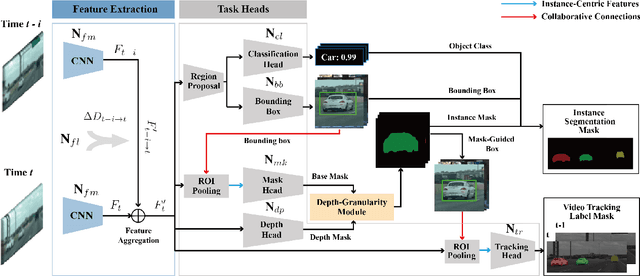
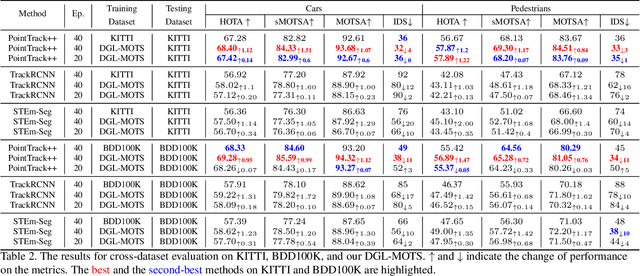
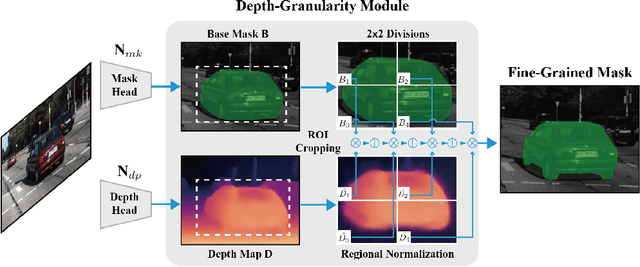
Multi-object tracking and segmentation (MOTS) is a critical task for autonomous driving applications. The existing MOTS studies face two critical challenges: 1) the published datasets inadequately capture the real-world complexity for network training to address various driving settings; 2) the working pipeline annotation tool is under-studied in the literature to improve the quality of MOTS learning examples. In this work, we introduce the DG-Labeler and DGL-MOTS dataset to facilitate the training data annotation for the MOTS task and accordingly improve network training accuracy and efficiency. DG-Labeler uses the novel Depth-Granularity Module to depict the instance spatial relations and produce fine-grained instance masks. Annotated by DG-Labeler, our DGL-MOTS dataset exceeds the prior effort (i.e., KITTI MOTS and BDD100K) in data diversity, annotation quality, and temporal representations. Results on extensive cross-dataset evaluations indicate significant performance improvements for several state-of-the-art methods trained on our DGL-MOTS dataset. We believe our DGL-MOTS Dataset and DG-Labeler hold the valuable potential to boost the visual perception of future transportation.