 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Look Bottom-Up for Monocular 3D Object Detection
Jan 27, 2024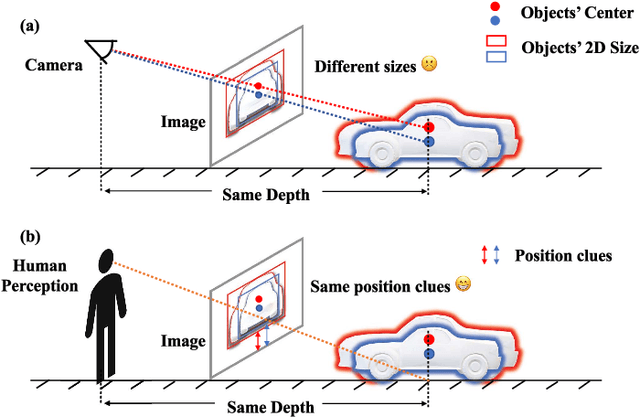
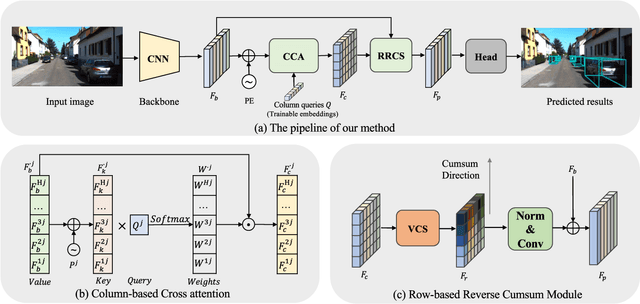
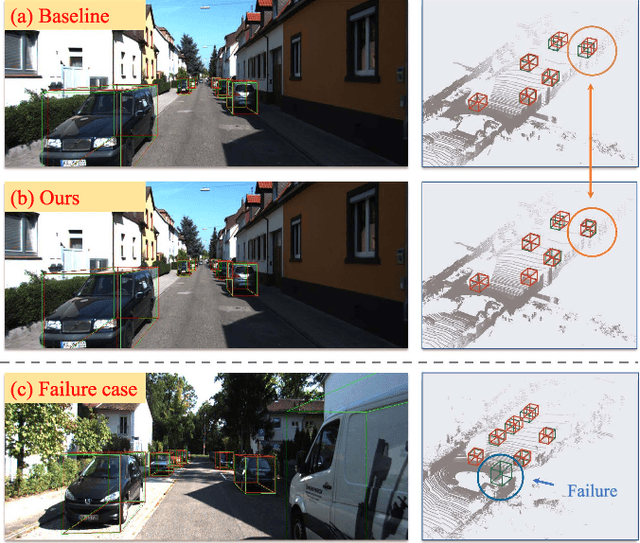
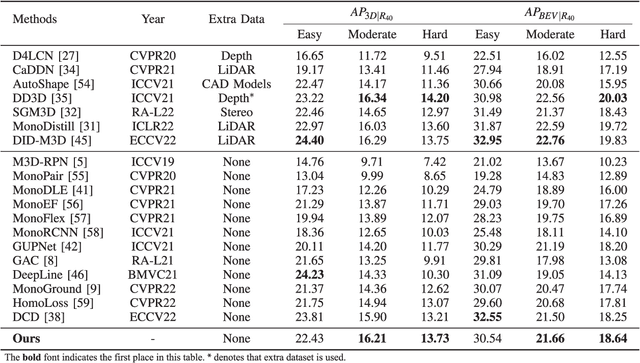
Monocular 3D Object Detection is an essential task for autonomous driving. Meanwhile, accurate 3D object detection from pure images is very challenging due to the loss of depth information. Most existing image-based methods infer objects' location in 3D space based on their 2D sizes on the image plane, which usually ignores the intrinsic position clues from images, leading to unsatisfactory performances. Motivated by the fact that humans could leverage the bottom-up positional clues to locate objects in 3D space from a single image, in this paper, we explore the position modeling from the image feature column and propose a new method named You Only Look Bottum-Up (YOLOBU). Specifically, our YOLOBU leverages Column-based Cross Attention to determine how much a pixel contributes to pixels above it. Next, the Row-based Reverse Cumulative Sum (RRCS) is introduced to build the connections of pixels in the bottom-up direction. Our YOLOBU fully explores the position clues for monocular 3D detection via building the relationship of pixels from the bottom-up way. Extensive experiments on the KITTI dataset demonstrate the effectiveness and superiority of our method.
Syntax-Aware Network for Handwritten Mathematical Expression Recognition
Mar 28, 2022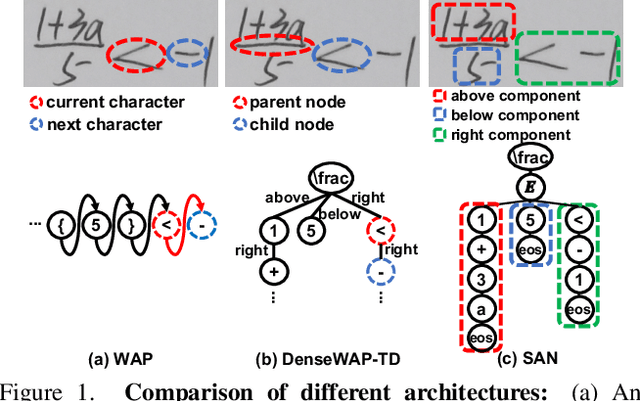

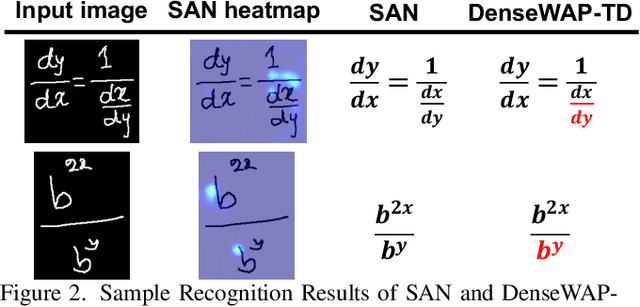
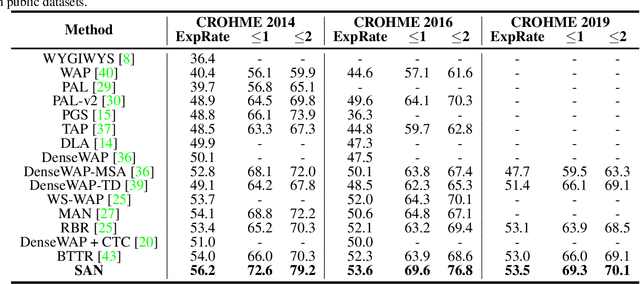
Handwritten mathematical expression recognition (HMER) is a challenging task that has many potential applications. Recent methods for HMER have achieved outstanding performance with an encoder-decoder architecture. However, these methods adhere to the paradigm that the prediction is made "from one character to another", which inevitably yields prediction errors due to the complicated structures of mathematical expressions or crabbed handwritings. In this paper, we propose a simple and efficient method for HMER, which is the first to incorporate syntax information into an encoder-decoder network. Specifically, we present a set of grammar rules for converting the LaTeX markup sequence of each expression into a parsing tree; then, we model the markup sequence prediction as a tree traverse process with a deep neural network. In this way, the proposed method can effectively describe the syntax context of expressions, alleviating the structure prediction errors of HMER. Experiments on three benchmark datasets demonstrate that our method achieves better recognition performance than prior arts. To further validate the effectiveness of our method, we create a large-scale dataset consisting of 100k handwritten mathematical expression images acquired from ten thousand writers. The source code, new dataset, and pre-trained models of this work will be publicly available.
Comprehensive Benchmark Datasets for Amharic Scene Text Detection and Recognition
Mar 23, 2022
Ethiopic/Amharic script is one of the oldest African writing systems, which serves at least 23 languages (e.g., Amharic, Tigrinya) in East Africa for more than 120 million people. The Amharic writing system, Abugida, has 282 syllables, 15 punctuation marks, and 20 numerals. The Amharic syllabic matrix is derived from 34 base graphemes/consonants by adding up to 12 appropriate diacritics or vocalic markers to the characters. The syllables with a common consonant or vocalic markers are likely to be visually similar and challenge text recognition tasks. In this work, we presented the first comprehensive public datasets named HUST-ART, HUST-AST, ABE, and Tana for Amharic script detection and recognition in the natural scene. We have also conducted extensive experiments to evaluate the performance of the state of art methods in detecting and recognizing Amharic scene text on our datasets. The evaluation results demonstrate the robustness of our datasets for benchmarking and its potential of promoting the development of robust Amharic script detection and recognition algorithms. Consequently, the outcome will benefit people in East Africa, including diplomats from several countries and international communities.