 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Model Choice to Model Belief: Establishing a New Measure for LLM-Based Research
Dec 29, 2025Large language models (LLMs) are increasingly used to simulate human behavior, but common practices to use LLM-generated data are inefficient. Treating an LLM's output ("model choice") as a single data point underutilizes the information inherent to the probabilistic nature of LLMs. This paper introduces and formalizes "model belief," a measure derived from an LLM's token-level probabilities that captures the model's belief distribution over choice alternatives in a single generation run. The authors prove that model belief is asymptotically equivalent to the mean of model choices (a non-trivial property) but forms a more statistically efficient estimator, with lower variance and a faster convergence rate. Analogous properties are shown to hold for smooth functions of model belief and model choice often used in downstream applications. The authors demonstrate the performance of model belief through a demand estimation study, where an LLM simulates consumer responses to different prices. In practical settings with limited numbers of runs, model belief explains and predicts ground-truth model choice better than model choice itself, and reduces the computation needed to reach sufficiently accurate estimates by roughly a factor of 20. The findings support using model belief as the default measure to extract more information from LLM-generated data.
AccentSpeech: Learning Accent from Crowd-sourced Data for Target Speaker TTS with Accents
Oct 31, 2022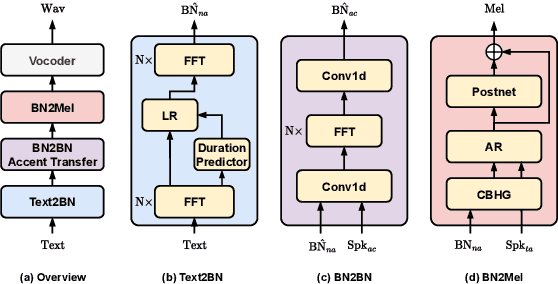
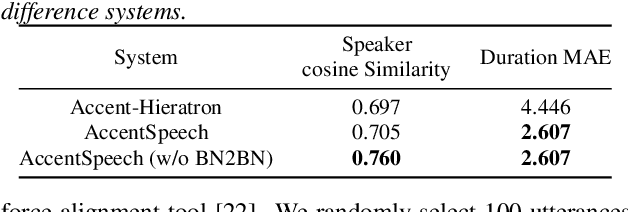
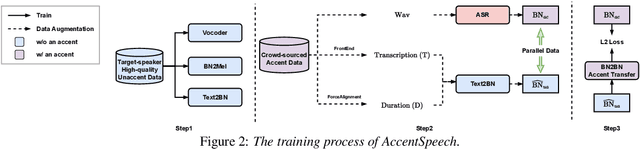
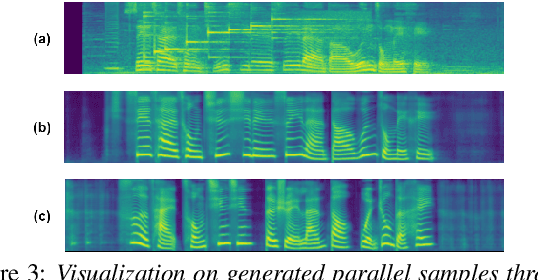
Learning accent from crowd-sourced data is a feasible way to achieve a target speaker TTS system that can synthesize accent speech. To this end, there are two challenging problems to be solved. First, direct use of the poor acoustic quality crowd-sourced data and the target speaker data in accent transfer will apparently lead to synthetic speech with degraded quality. To mitigate this problem, we take a bottleneck feature (BN) based TTS approach, in which TTS is decomposed into a Text-to-BN (T2BN) module to learn accent and a BN-to-Mel (BN2Mel) module to learn speaker timbre, where neural network based BN feature serves as the intermediate representation that are robust to noise interference. Second, direct training T2BN using the crowd-sourced data in the two-stage system will produce accent speech of target speaker with poor prosody. This is because the the crowd-sourced recordings are contributed from the ordinary unprofessional speakers. To tackle this problem, we update the two-stage approach to a novel three-stage approach, where T2BN and BN2Mel are trained using the high-quality target speaker data and a new BN-to-BN module is plugged in between the two modules to perform accent transfer. To train the BN2BN module, the parallel unaccented and accented BN features are obtained by a proposed data augmentation procedure. Finally the proposed three-stage approach manages to produce accent speech for the target speaker with good prosody, as the prosody pattern is inherited from the professional target speaker and accent transfer is achieved by the BN2BN module at the same time. The proposed approach, named as AccentSpeech, is validated in a Mandarin TTS accent transfer task.