 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnify-Agent: A Unified Multimodal Agent for World-Grounded Image Synthesis
Apr 01, 2026Unified multimodal models provide a natural and promising architecture for understanding diverse and complex real-world knowledge while generating high-quality images. However, they still rely primarily on frozen parametric knowledge, which makes them struggle with real-world image generation involving long-tail and knowledge-intensive concepts. Inspired by the broad success of agents on real-world tasks, we explore agentic modeling to address this limitation. Specifically, we present Unify-Agent, a unified multimodal agent for world-grounded image synthesis, which reframes image generation as an agentic pipeline consisting of prompt understanding, multimodal evidence searching, grounded recaptioning, and final synthesis. To train our model, we construct a tailored multimodal data pipeline and curate 143K high-quality agent trajectories for world-grounded image synthesis, enabling effective supervision over the full agentic generation process. We further introduce FactIP, a benchmark covering 12 categories of culturally significant and long-tail factual concepts that explicitly requires external knowledge grounding. Extensive experiments show that our proposed Unify-Agent substantially improves over its base unified model across diverse benchmarks and real world generation tasks, while approaching the world knowledge capabilities of the strongest closed-source models. As an early exploration of agent-based modeling for world-grounded image synthesis, our work highlights the value of tightly coupling reasoning, searching, and generation for reliable open-world agentic image synthesis.
AUV: Teaching Audio Universal Vector Quantization with Single Nested Codebook
Sep 26, 2025We propose AUV, a unified neural audio codec with a single codebook, which enables a favourable reconstruction of speech and further extends to general audio, including vocal, music, and sound. AUV is capable of tackling any 16 kHz mixed-domain audio segment at bit rates around 700 bps. To accomplish this, we guide the matryoshka codebook with nested domain-specific partitions, assigned with corresponding teacher models to perform distillation, all in a single-stage training. A conformer-style encoder-decoder architecture with STFT features as audio representation is employed, yielding better audio quality. Comprehensive evaluations demonstrate that AUV exhibits comparable audio reconstruction ability to state-of-the-art domain-specific single-layer quantizer codecs, showcasing the potential of audio universal vector quantization with a single codebook. The pre-trained model and demo samples are available at https://swivid.github.io/AUV/.
DualSpeechLM: Towards Unified Speech Understanding and Generation via Dual Speech Token Modeling with Large Language Models
Aug 12, 2025Extending pre-trained Large Language Models (LLMs)'s speech understanding or generation abilities by introducing various effective speech tokens has attracted great attention in the speech community. However, building a unified speech understanding and generation model still faces the following challenges: (1) Due to the huge modality gap between speech tokens and text tokens, extending text LLMs to unified speech LLMs relies on large-scale paired data for fine-tuning, and (2) Generation and understanding tasks prefer information at different levels, e.g., generation benefits from detailed acoustic features, while understanding favors high-level semantics. This divergence leads to difficult performance optimization in one unified model. To solve these challenges, in this paper, we present two key insights in speech tokenization and speech language modeling. Specifically, we first propose an Understanding-driven Speech Tokenizer (USTokenizer), which extracts high-level semantic information essential for accomplishing understanding tasks using text LLMs. In this way, USToken enjoys better modality commonality with text, which reduces the difficulty of modality alignment in adapting text LLMs to speech LLMs. Secondly, we present DualSpeechLM, a dual-token modeling framework that concurrently models USToken as input and acoustic token as output within a unified, end-to-end framework, seamlessly integrating speech understanding and generation capabilities. Furthermore, we propose a novel semantic supervision loss and a Chain-of-Condition (CoC) strategy to stabilize model training and enhance speech generation performance. Experimental results demonstrate that our proposed approach effectively fosters a complementary relationship between understanding and generation tasks, highlighting the promising strategy of mutually enhancing both tasks in one unified model.
Towards Hallucination-Free Music: A Reinforcement Learning Preference Optimization Framework for Reliable Song Generation
Aug 07, 2025Recent advances in audio-based generative language models have accelerated AI-driven lyric-to-song generation. However, these models frequently suffer from content hallucination, producing outputs misaligned with the input lyrics and undermining musical coherence. Current supervised fine-tuning (SFT) approaches, limited by passive label-fitting, exhibit constrained self-improvement and poor hallucination mitigation. To address this core challenge, we propose a novel reinforcement learning (RL) framework leveraging preference optimization for hallucination control. Our key contributions include: (1) Developing a robust hallucination preference dataset constructed via phoneme error rate (PER) computation and rule-based filtering to capture alignment with human expectations; (2) Implementing and evaluating three distinct preference optimization strategies within the RL framework: Direct Preference Optimization (DPO), Proximal Policy Optimization (PPO), and Group Relative Policy Optimization (GRPO). DPO operates off-policy to enhance positive token likelihood, achieving a significant 7.4% PER reduction. PPO and GRPO employ an on-policy approach, training a PER-based reward model to iteratively optimize sequences via reward maximization and KL-regularization, yielding PER reductions of 4.9% and 4.7%, respectively. Comprehensive objective and subjective evaluations confirm that our methods effectively suppress hallucinations while preserving musical quality. Crucially, this work presents a systematic, RL-based solution to hallucination control in lyric-to-song generation. The framework's transferability also unlocks potential for music style adherence and musicality enhancement, opening new avenues for future generative song research.
SongBloom: Coherent Song Generation via Interleaved Autoregressive Sketching and Diffusion Refinement
Jun 09, 2025Generating music with coherent structure, harmonious instrumental and vocal elements remains a significant challenge in song generation. Existing language models and diffusion-based methods often struggle to balance global coherence with local fidelity, resulting in outputs that lack musicality or suffer from incoherent progression and mismatched lyrics. This paper introduces $\textbf{SongBloom}$, a novel framework for full-length song generation that leverages an interleaved paradigm of autoregressive sketching and diffusion-based refinement. SongBloom employs an autoregressive diffusion model that combines the high fidelity of diffusion models with the scalability of language models. Specifically, it gradually extends a musical sketch from short to long and refines the details from coarse to fine-grained. The interleaved generation paradigm effectively integrates prior semantic and acoustic context to guide the generation process. Experimental results demonstrate that SongBloom outperforms existing methods across both subjective and objective metrics and achieves performance comparable to the state-of-the-art commercial music generation platforms. Audio samples are available on our demo page: https://cypress-yang.github.io/SongBloom\_demo.
LeVo: High-Quality Song Generation with Multi-Preference Alignment
Jun 09, 2025



Recent advances in large language models (LLMs) and audio language models have significantly improved music generation, particularly in lyrics-to-song generation. However, existing approaches still struggle with the complex composition of songs and the scarcity of high-quality data, leading to limitations in sound quality, musicality, instruction following, and vocal-instrument harmony. To address these challenges, we introduce LeVo, an LM-based framework consisting of LeLM and a music codec. LeLM is capable of parallelly modeling two types of tokens: mixed tokens, which represent the combined audio of vocals and accompaniment to achieve vocal-instrument harmony, and dual-track tokens, which separately encode vocals and accompaniment for high-quality song generation. It employs two decoder-only transformers and a modular extension training strategy to prevent interference between different token types. To further enhance musicality and instruction following, we introduce a multi-preference alignment method based on Direct Preference Optimization (DPO). This method handles diverse human preferences through a semi-automatic data construction process and DPO post-training. Experimental results demonstrate that LeVo consistently outperforms existing methods on both objective and subjective metrics. Ablation studies further justify the effectiveness of our designs. Audio examples are available at https://levo-demo.github.io/.
WAKE: Watermarking Audio with Key Enrichment
Jun 06, 2025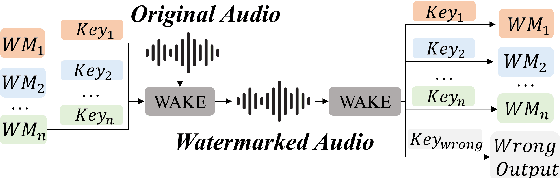

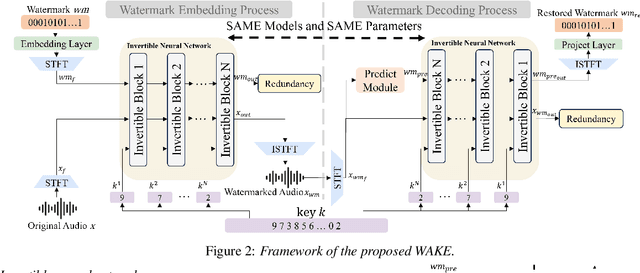
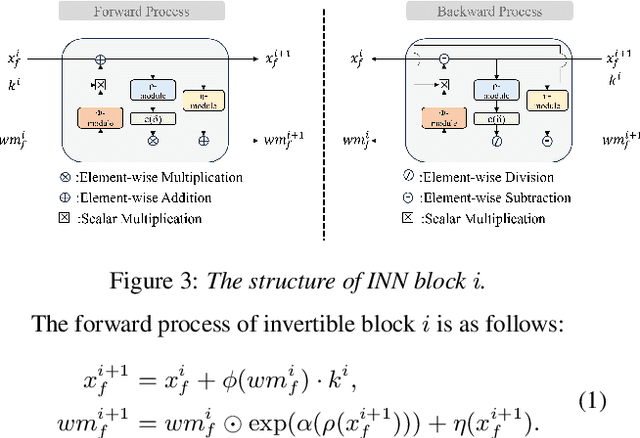
As deep learning advances in audio generation, challenges in audio security and copyright protection highlight the need for robust audio watermarking. Recent neural network-based methods have made progress but still face three main issues: preventing unauthorized access, decoding initial watermarks after multiple embeddings, and embedding varying lengths of watermarks. To address these issues, we propose WAKE, the first key-controllable audio watermark framework. WAKE embeds watermarks using specific keys and recovers them with corresponding keys, enhancing security by making incorrect key decoding impossible. It also resolves the overwriting issue by allowing watermark decoding after multiple embeddings and supports variable-length watermark insertion. WAKE outperforms existing models in both watermarked audio quality and watermark detection accuracy. Code, more results, and demo page: https://thuhcsi.github.io/WAKE.
Layer-wise Investigation of Large-Scale Self-Supervised Music Representation Models
May 22, 2025Recently, pre-trained models for music information retrieval based on self-supervised learning (SSL) are becoming popular, showing success in various downstream tasks. However, there is limited research on the specific meanings of the encoded information and their applicability. Exploring these aspects can help us better understand their capabilities and limitations, leading to more effective use in downstream tasks. In this study, we analyze the advanced music representation model MusicFM and the newly emerged SSL model MuQ. We focus on three main aspects: (i) validating the advantages of SSL models across multiple downstream tasks, (ii) exploring the specialization of layer-wise information for different tasks, and (iii) comparing performance differences when selecting specific layers. Through this analysis, we reveal insights into the structure and potential applications of SSL models in music information retrieval.
UniSep: Universal Target Audio Separation with Language Models at Scale
Mar 31, 2025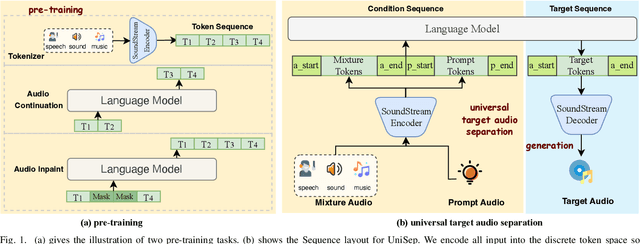
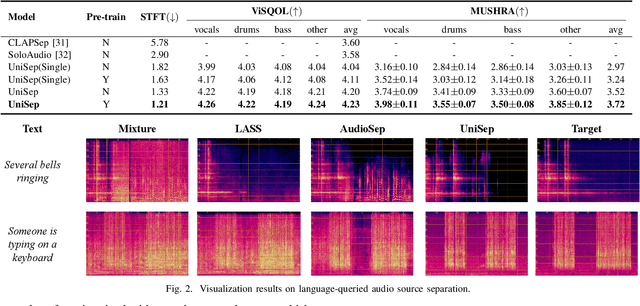

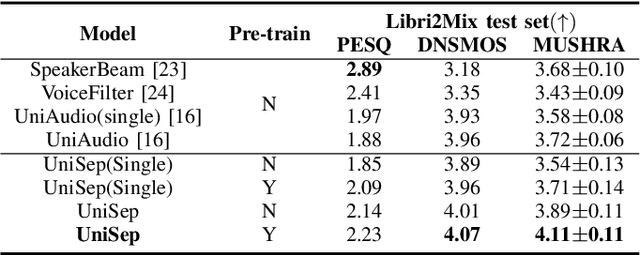
We propose Universal target audio Separation (UniSep), addressing the separation task on arbitrary mixtures of different types of audio. Distinguished from previous studies, UniSep is performed on unlimited source domains and unlimited source numbers. We formulate the separation task as a sequence-to-sequence problem, and a large language model (LLM) is used to model the audio sequence in the discrete latent space, leveraging the power of LLM in handling complex mixture audios with large-scale data. Moreover, a novel pre-training strategy is proposed to utilize audio-only data, which reduces the efforts of large-scale data simulation and enhances the ability of LLMs to understand the consistency and correlation of information within audio sequences. We also demonstrate the effectiveness of scaling datasets in an audio separation task: we use large-scale data (36.5k hours), including speech, music, and sound, to train a universal target audio separation model that is not limited to a specific domain. Experiments show that UniSep achieves competitive subjective and objective evaluation results compared with single-task models.
MuQ: Self-Supervised Music Representation Learning with Mel Residual Vector Quantization
Jan 03, 2025



Recent years have witnessed the success of foundation models pre-trained with self-supervised learning (SSL) in various music informatics understanding tasks, including music tagging, instrument classification, key detection, and more. In this paper, we propose a self-supervised music representation learning model for music understanding. Distinguished from previous studies adopting random projection or existing neural codec, the proposed model, named MuQ, is trained to predict tokens generated by Mel Residual Vector Quantization (Mel-RVQ). Our Mel-RVQ utilizes residual linear projection structure for Mel spectrum quantization to enhance the stability and efficiency of target extraction and lead to better performance. Experiments in a large variety of downstream tasks demonstrate that MuQ outperforms previous self-supervised music representation models with only 0.9K hours of open-source pre-training data. Scaling up the data to over 160K hours and adopting iterative training consistently improve the model performance. To further validate the strength of our model, we present MuQ-MuLan, a joint music-text embedding model based on contrastive learning, which achieves state-of-the-art performance in the zero-shot music tagging task on the MagnaTagATune dataset. Code and checkpoints are open source in https://github.com/tencent-ailab/MuQ.