 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Target Speech Extraction: Enhancing Personalized Diarization and Extraction on Complex Recordings
Paper and Code
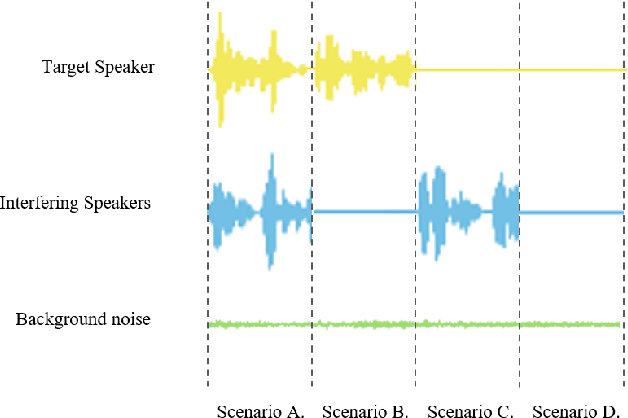
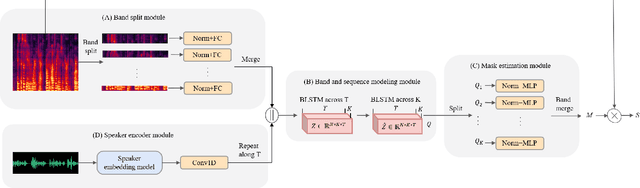
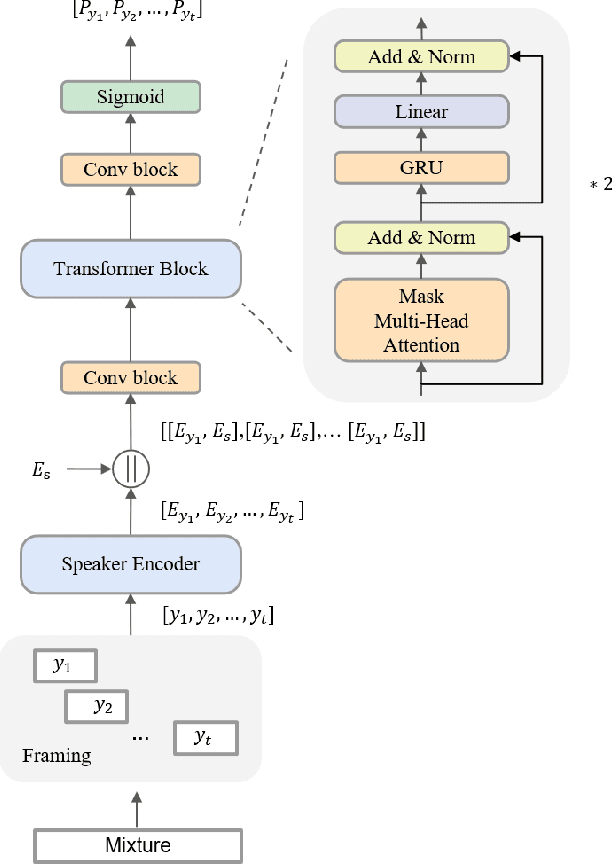
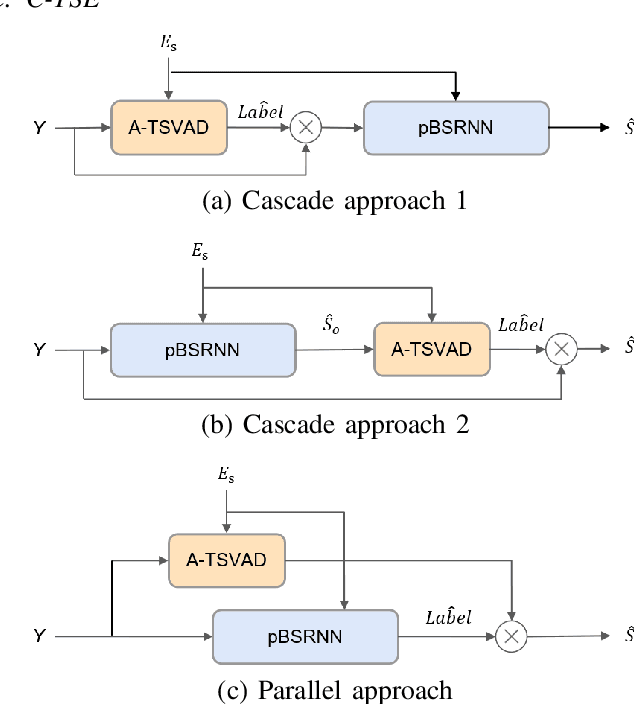
Target speaker extraction (TSE) aims to extract the target speaker's voice from the input mixture. Previous studies have concentrated on high-overlapping scenarios. However, real-world applications usually meet more complex scenarios like variable speaker overlapping and target speaker absence. In this paper, we introduces a framework to perform continuous TSE (C-TSE), comprising a target speaker voice activation detection (TSVAD) and a TSE model. This framework significantly improves TSE performance on similar speakers and enhances personalization, which is lacking in traditional diarization methods. In detail, unlike conventional TSVAD deployed to refine the diarization results, the proposed Attention-target speaker voice activation detection (A-TSVAD) directly generates timestamps of the target speaker. We also explore some different integration methods of A-TSVAD and TSE by comparing the cascaded and parallel methods. The framework's effectiveness is assessed using a range of metrics, including diarization and enhancement metrics. Our experiments demonstrate that A-TSVAD outperforms conventional methods in reducing diarization errors. Furthermore, the integration of A-TSVAD and TSE in a sequential cascaded manner further enhances extraction accuracy.