 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion Omni: Enabling Empathetic Speech Response Generation through Large Language Models
Aug 26, 2025With the development of speech large language models (speech LLMs), users can now interact directly with assistants via speech. However, most existing models simply convert the response content into speech without fully understanding the rich emotional and paralinguistic cues embedded in the user's query. In many cases, the same sentence can have different meanings depending on the emotional expression. Furthermore, emotional understanding is essential for improving user experience in human-machine interaction. Currently, most speech LLMs with empathetic capabilities are trained on massive datasets. This approach requires vast amounts of data and significant computational resources. Therefore, a key challenge lies in how to develop a speech LLM capable of generating empathetic responses with limited data and without the need for large-scale training. To address this challenge, we propose Emotion Omni, a novel model architecture designed to understand the emotional content of user speech input and generate empathetic speech responses. Additionally, we developed a data generation pipeline based on an open-source TTS framework to construct a 200k emotional dialogue dataset, which supports the construction of an empathetic speech assistant. The demos are available at https://w311411.github.io/omni_demo/
HunyuanVideo-Foley: Multimodal Diffusion with Representation Alignment for High-Fidelity Foley Audio Generation
Aug 23, 2025Recent advances in video generation produce visually realistic content, yet the absence of synchronized audio severely compromises immersion. To address key challenges in video-to-audio generation, including multimodal data scarcity, modality imbalance and limited audio quality in existing methods, we propose HunyuanVideo-Foley, an end-to-end text-video-to-audio framework that synthesizes high-fidelity audio precisely aligned with visual dynamics and semantic context. Our approach incorporates three core innovations: (1) a scalable data pipeline curating 100k-hour multimodal datasets through automated annotation; (2) a representation alignment strategy using self-supervised audio features to guide latent diffusion training, efficiently improving audio quality and generation stability; (3) a novel multimodal diffusion transformer resolving modal competition, containing dual-stream audio-video fusion through joint attention, and textual semantic injection via cross-attention. Comprehensive evaluations demonstrate that HunyuanVideo-Foley achieves new state-of-the-art performance across audio fidelity, visual-semantic alignment, temporal alignment and distribution matching. The demo page is available at: https://szczesnys.github.io/hunyuanvideo-foley/.
FLY-TTS: Fast, Lightweight and High-Quality End-to-End Text-to-Speech Synthesis
Jun 30, 2024While recent advances in Text-To-Speech synthesis have yielded remarkable improvements in generating high-quality speech, research on lightweight and fast models is limited. This paper introduces FLY-TTS, a new fast, lightweight and high-quality speech synthesis system based on VITS. Specifically, 1) We replace the decoder with ConvNeXt blocks that generate Fourier spectral coefficients followed by the inverse short-time Fourier transform to synthesize waveforms; 2) To compress the model size, we introduce the grouped parameter-sharing mechanism to the text encoder and flow-based model; 3) We further employ the large pre-trained WavLM model for adversarial training to improve synthesis quality. Experimental results show that our model achieves a real-time factor of 0.0139 on an Intel Core i9 CPU, 8.8x faster than the baseline (0.1221), with a 1.6x parameter compression. Objective and subjective evaluations indicate that FLY-TTS exhibits comparable speech quality to the strong baseline.
Continuous Target Speech Extraction: Enhancing Personalized Diarization and Extraction on Complex Recordings
Jan 29, 2024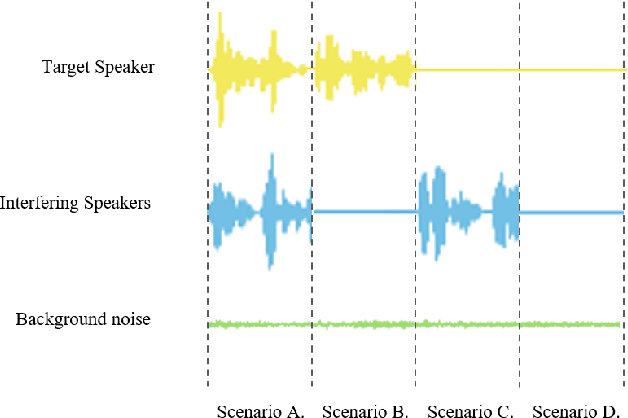
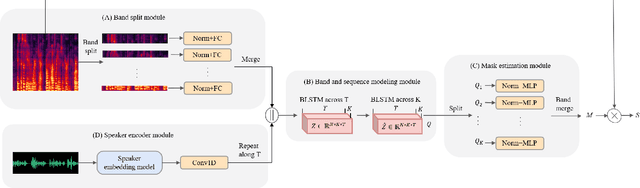
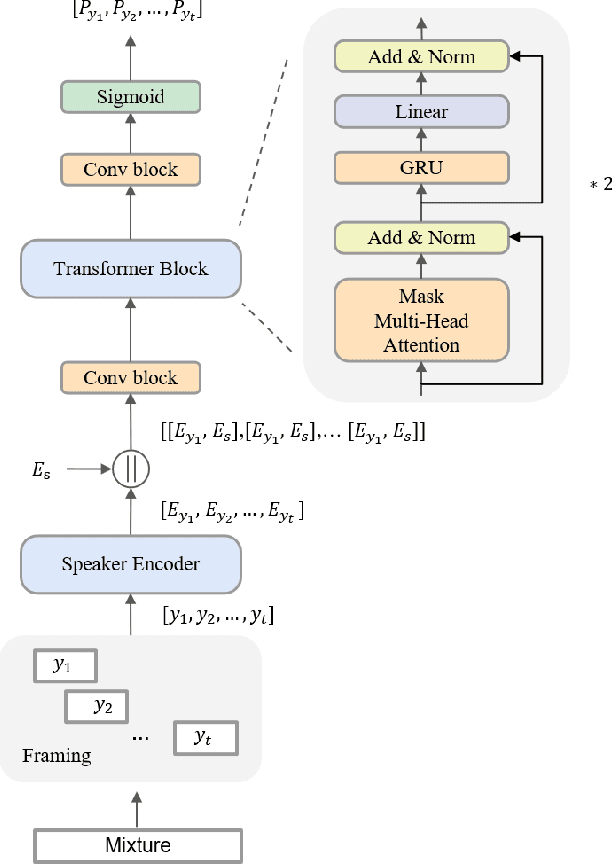
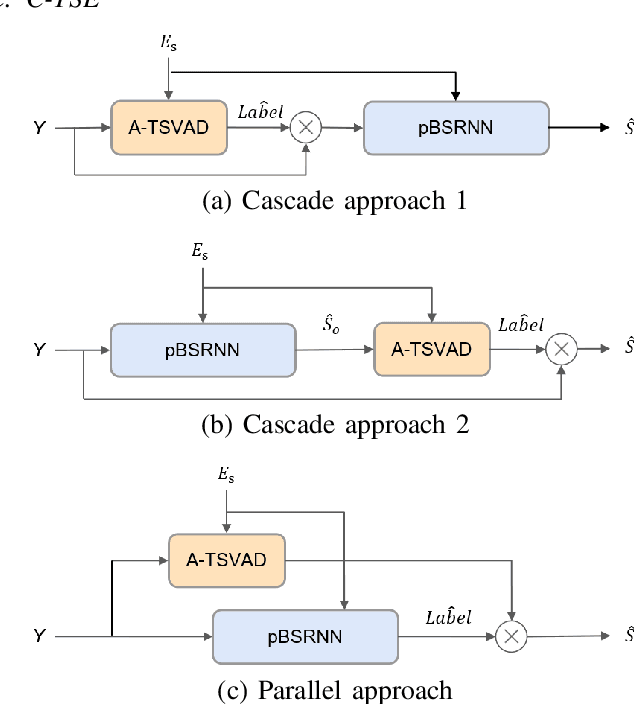
Target speaker extraction (TSE) aims to extract the target speaker's voice from the input mixture. Previous studies have concentrated on high-overlapping scenarios. However, real-world applications usually meet more complex scenarios like variable speaker overlapping and target speaker absence. In this paper, we introduces a framework to perform continuous TSE (C-TSE), comprising a target speaker voice activation detection (TSVAD) and a TSE model. This framework significantly improves TSE performance on similar speakers and enhances personalization, which is lacking in traditional diarization methods. In detail, unlike conventional TSVAD deployed to refine the diarization results, the proposed Attention-target speaker voice activation detection (A-TSVAD) directly generates timestamps of the target speaker. We also explore some different integration methods of A-TSVAD and TSE by comparing the cascaded and parallel methods. The framework's effectiveness is assessed using a range of metrics, including diarization and enhancement metrics. Our experiments demonstrate that A-TSVAD outperforms conventional methods in reducing diarization errors. Furthermore, the integration of A-TSVAD and TSE in a sequential cascaded manner further enhances extraction accuracy.
Audio Deepfake Detection with Self-Supervised WavLM and Multi-Fusion Attentive Classifier
Dec 13, 2023With the rapid development of speech synthesis and voice conversion technologies, Audio Deepfake has become a serious threat to the Automatic Speaker Verification (ASV) system. Numerous countermeasures are proposed to detect this type of attack. In this paper, we report our efforts to combine the self-supervised WavLM model and Multi-Fusion Attentive classifier for audio deepfake detection. Our method exploits the WavLM model to extract features that are more conducive to spoofing detection for the first time. Then, we propose a novel Multi-Fusion Attentive (MFA) classifier based on the Attentive Statistics Pooling (ASP) layer. The MFA captures the complementary information of audio features at both time and layer levels. Experiments demonstrate that our methods achieve state-of-the-art results on the ASVspoof 2021 DF set and provide competitive results on the ASVspoof 2019 and 2021 LA set.
Mispronunciation Detection and Correction via Discrete Acoustic Units
Aug 12, 2021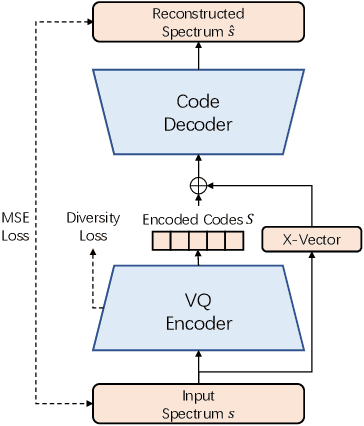

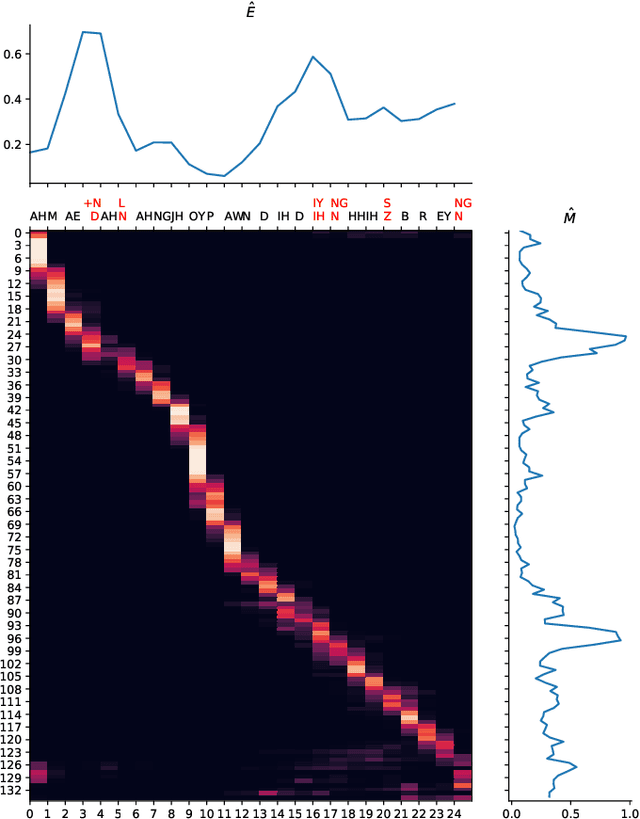
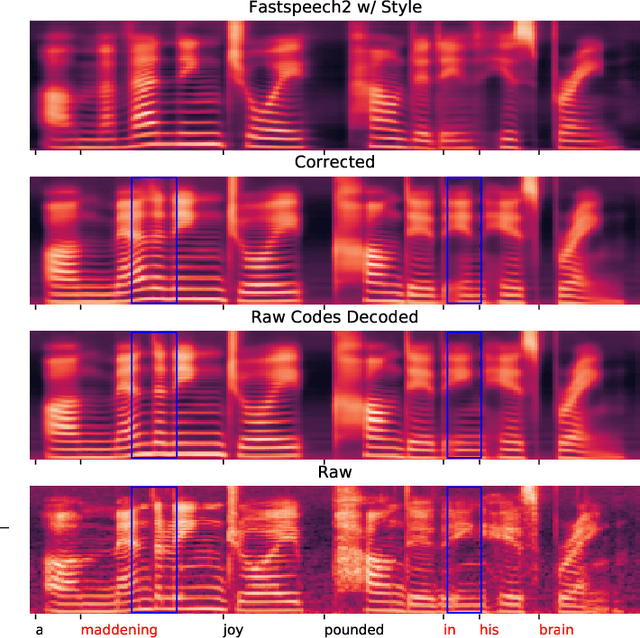
Computer-Assisted Pronunciation Training (CAPT) plays an important role in language learning. However, conventional CAPT methods cannot effectively use non-native utterances for supervised training because the ground truth pronunciation needs expensive annotation. Meanwhile, certain undefined nonnative phonemes cannot be correctly classified into standard phonemes. To solve these problems, we use the vector-quantized variational autoencoder (VQ-VAE) to encode the speech into discrete acoustic units in a self-supervised manner. Based on these units, we propose a novel method that integrates both discriminative and generative models. The proposed method can detect mispronunciation and generate the correct pronunciation at the same time. Experiments on the L2-Arctic dataset show that the detection F1 score is improved by 9.58% relatively compared with recognition-based methods. The proposed method also achieves a comparable word error rate (WER) and the best style preservation for mispronunciation correction compared with text-to-speech (TTS) methods.
Accent Recognition with Hybrid Phonetic Features
May 05, 2021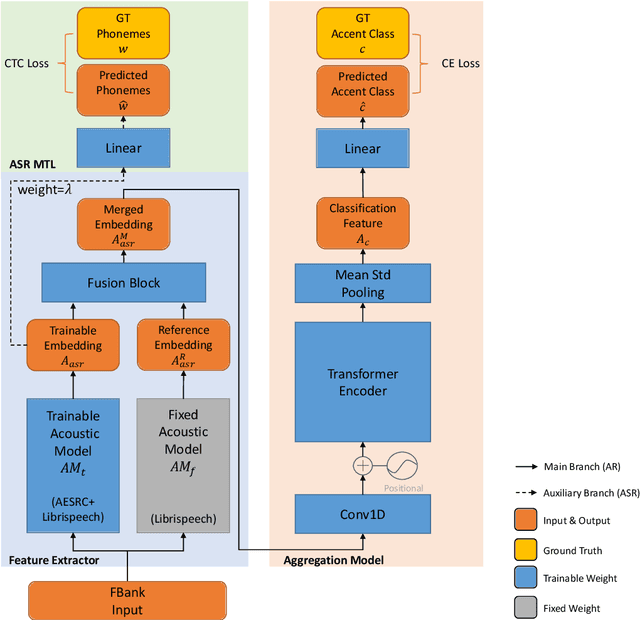

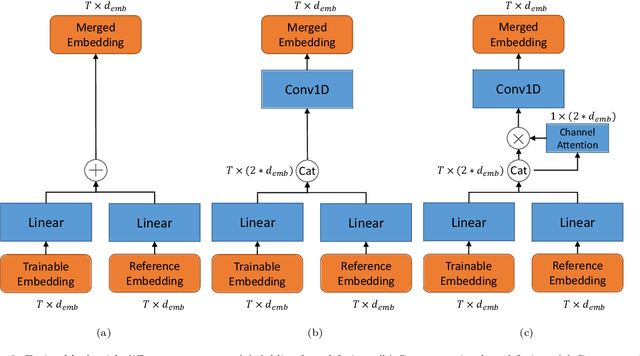
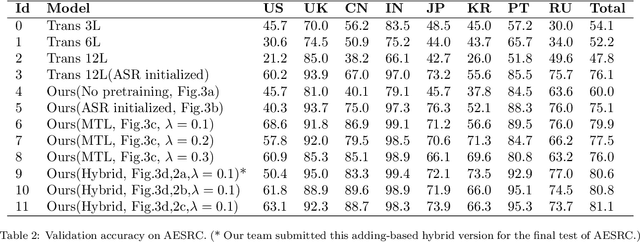
The performance of voice-controlled systems is usually influenced by accented speech. To make these systems more robust, the frontend accent recognition (AR) technologies have received increased attention in recent years. As accent is a high-level abstract feature that has a profound relationship with the language knowledge, AR is more challenging than other language-agnostic audio classification tasks. In this paper, we use an auxiliary automatic speech recognition (ASR) task to extract language-related phonetic features. Furthermore, we propose a hybrid structure that incorporates the embeddings of both a fixed acoustic model and a trainable acoustic model, making the language-related acoustic feature more robust. We conduct several experiments on the Accented English Speech Recognition Challenge (AESRC) 2020 dataset. The results demonstrate that our approach can obtain a 6.57% relative improvement on the validation set. We also get a 7.28% relative improvement on the final test set for this competition, showing the merits of the proposed method.
Collaborative Distillation for Ultra-Resolution Universal Style Transfer
Mar 24, 2020

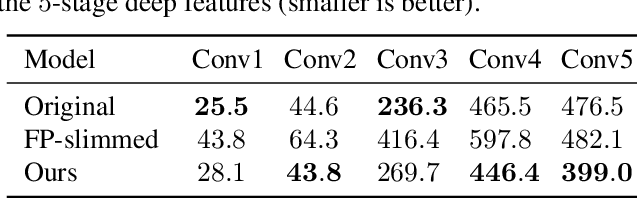
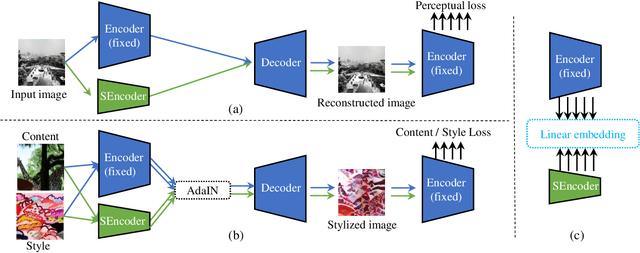
Universal style transfer methods typically leverage rich representations from deep Convolutional Neural Network (CNN) models (e.g., VGG-19) pre-trained on large collections of images. Despite the effectiveness, its application is heavily constrained by the large model size to handle ultra-resolution images given limited memory. In this work, we present a new knowledge distillation method (named Collaborative Distillation) for encoder-decoder based neural style transfer to reduce the convolutional filters. The main idea is underpinned by a finding that the encoder-decoder pairs construct an exclusive collaborative relationship, which is regarded as a new kind of knowledge for style transfer models. Moreover, to overcome the feature size mismatch when applying collaborative distillation, a linear embedding loss is introduced to drive the student network to learn a linear embedding of the teacher's features. Extensive experiments show the effectiveness of our method when applied to different universal style transfer approaches (WCT and AdaIN), even if the model size is reduced by 15.5 times. Especially, on WCT with the compressed models, we achieve ultra-resolution (over 40 megapixels) universal style transfer on a 12GB GPU for the first time. Further experiments on optimization-based stylization scheme show the generality of our algorithm on different stylization paradigms. Our code and trained models are available at https://github.com/mingsun-tse/collaborative-distillation.
Structured Pruning for Efficient ConvNets via Incremental Regularization
Nov 20, 2018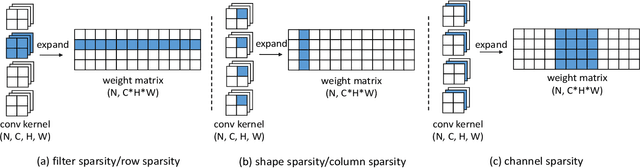
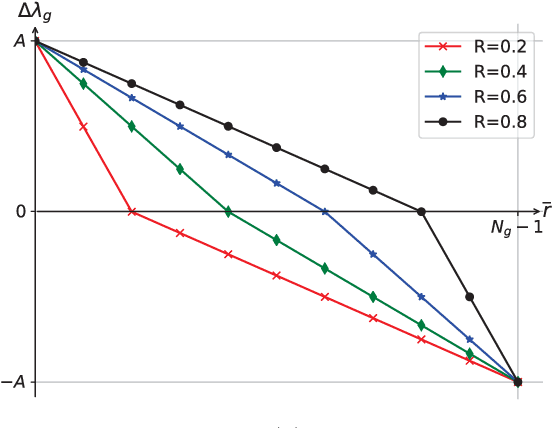
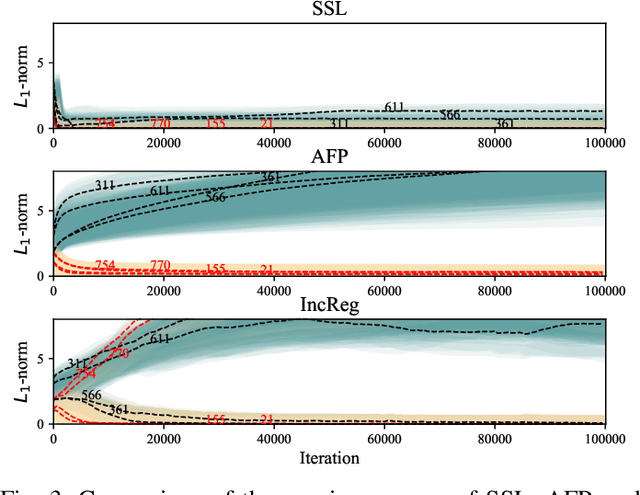
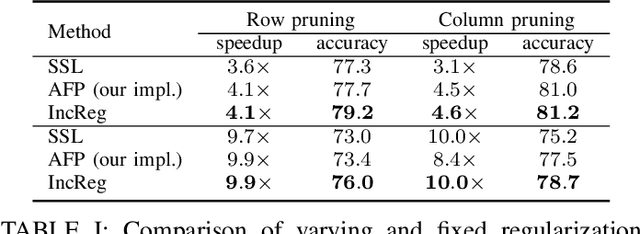
Parameter pruning is a promising approach for CNN compression and acceleration by eliminating redundant model parameters with tolerable performance loss. Despite its effectiveness, existing regularization-based parameter pruning methods usually drive weights towards zero with large and constant regularization factors, which neglects the fact that the expressiveness of CNNs is fragile and needs a more gentle way of regularization for the networks to adapt during pruning. To solve this problem, we propose a new regularization-based pruning method (named IncReg) to incrementally assign different regularization factors to different weight groups based on their relative importance, whose effectiveness is proved on popular CNNs compared with state-of-the-art methods.
Structured Probabilistic Pruning for Convolutional Neural Network Acceleration
Sep 10, 2018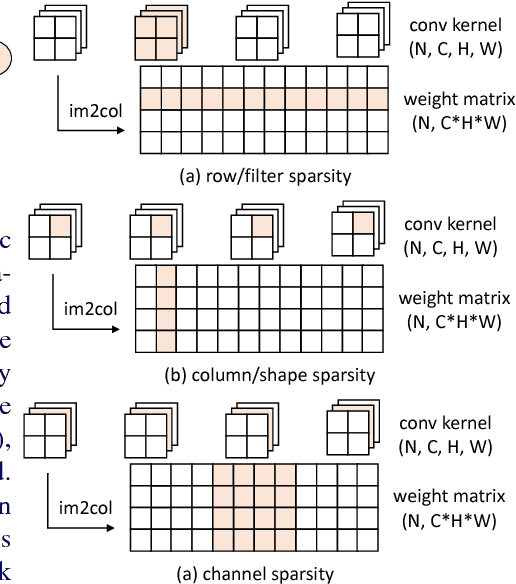
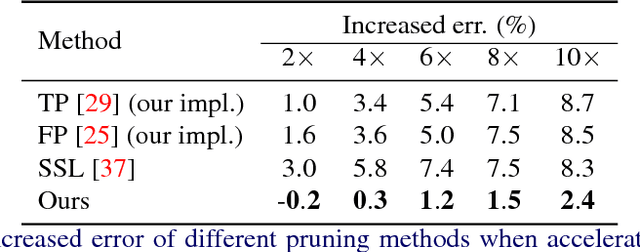
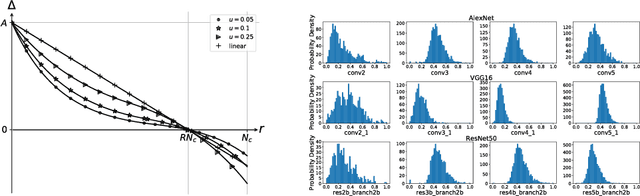

In this paper, we propose a novel progressive parameter pruning method for Convolutional Neural Network acceleration, named Structured Probabilistic Pruning (SPP), which effectively prunes weights of convolutional layers in a probabilistic manner. Unlike existing deterministic pruning approaches, where unimportant weights are permanently eliminated, SPP introduces a pruning probability for each weight, and pruning is guided by sampling from the pruning probabilities. A mechanism is designed to increase and decrease pruning probabilities based on importance criteria in the training process. Experiments show that, with 4x speedup, SPP can accelerate AlexNet with only 0.3% loss of top-5 accuracy and VGG-16 with 0.8% loss of top-5 accuracy in ImageNet classification. Moreover, SPP can be directly applied to accelerate multi-branch CNN networks, such as ResNet, without specific adaptations. Our 2x speedup ResNet-50 only suffers 0.8% loss of top-5 accuracy on ImageNet. We further show the effectiveness of SPP on transfer learning tasks.
* CNN model acceleration, 13 pages, 6 figures, accepted by Proceedings of the British Machine Vision Conference (BMVC), 2018 oral