 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper Resolution Using Segmentation-Prior Self-Attention Generative Adversarial Network
Mar 07, 2020
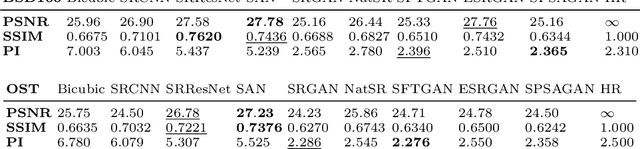

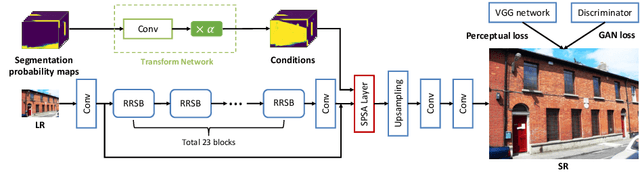
Convolutional Neural Network (CNN) is intensively implemented to solve super resolution (SR) tasks because of its superior performance. However, the problem of super resolution is still challenging due to the lack of prior knowledge and small receptive field of CNN. We propose the Segmentation-Piror Self-Attention Generative Adversarial Network (SPSAGAN) to combine segmentation-priors and feature attentions into a unified framework. This combination is led by a carefully designed weighted addition to balance the influence of feature and segmentation attentions, so that the network can emphasize textures in the same segmentation category and meanwhile focus on the long-distance feature relationship. We also propose a lightweight skip connection architecture called Residual-in-Residual Sparse Block (RRSB) to further improve the super-resolution performance and save computation. Extensive experiments show that SPSAGAN can generate more realistic and visually pleasing textures compared to state-of-the-art SFTGAN and ESRGAN on many SR datasets.
Triplet Distillation for Deep Face Recognition
May 19, 2019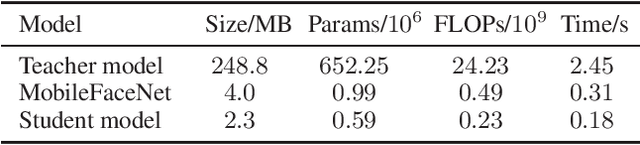
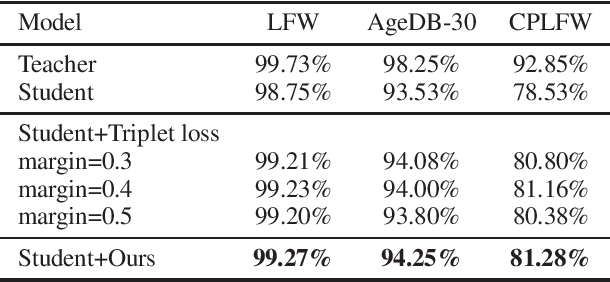
Convolutional neural networks (CNNs) have achieved a great success in face recognition, which unfortunately comes at the cost of massive computation and storage consumption. Many compact face recognition networks are thus proposed to resolve this problem. Triplet loss is effective to further improve the performance of those compact models. However, it normally employs a fixed margin to all the samples, which neglects the informative similarity structures between different identities. In this paper, we propose an enhanced version of triplet loss, named triplet distillation, which exploits the capability of a teacher model to transfer the similarity information to a small model by adaptively varying the margin between positive and negative pairs. Experiments on LFW, AgeDB, and CPLFW datasets show the merits of our method compared to the original triplet loss.
Three Dimensional Convolutional Neural Network Pruning with Regularization-Based Method
Nov 19, 2018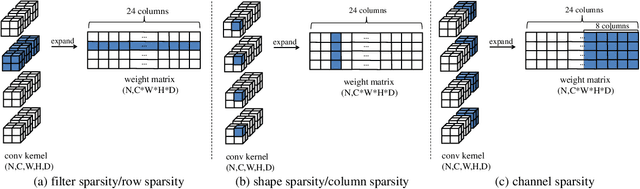

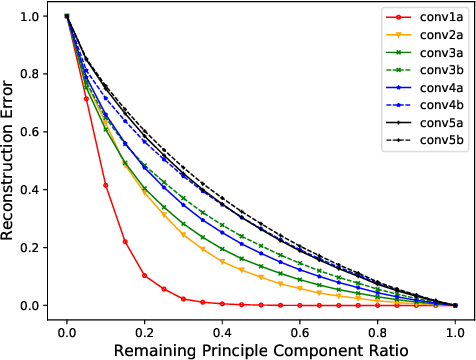
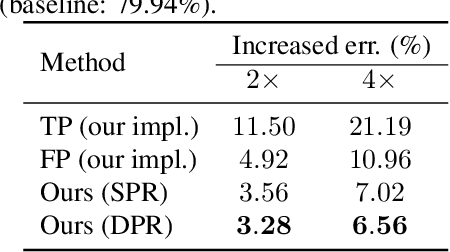
In recent years, three-dimensional convolutional neural network (3D CNN) is intensively applied in video analysis and receives good performance. However, 3D CNN leads to massive computation and storage consumption, which hinders its deployment on mobile and embedded devices. In this paper, we propose a three-dimensional regularization-based pruning method to assign different regularization parameters to different weight groups based on their importance to the network. Experiments show that the proposed method outperforms other popular methods in this area.
Structured Deep Neural Network Pruning by Varying Regularization Parameters
Apr 25, 2018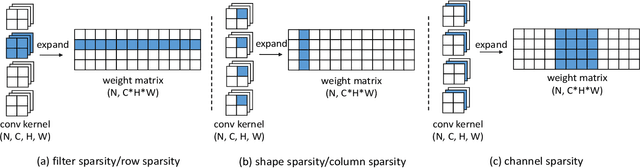
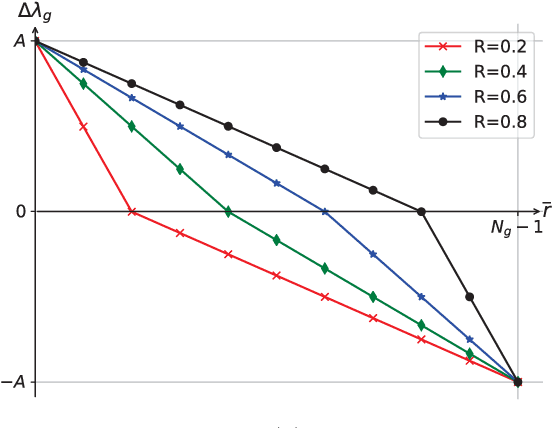
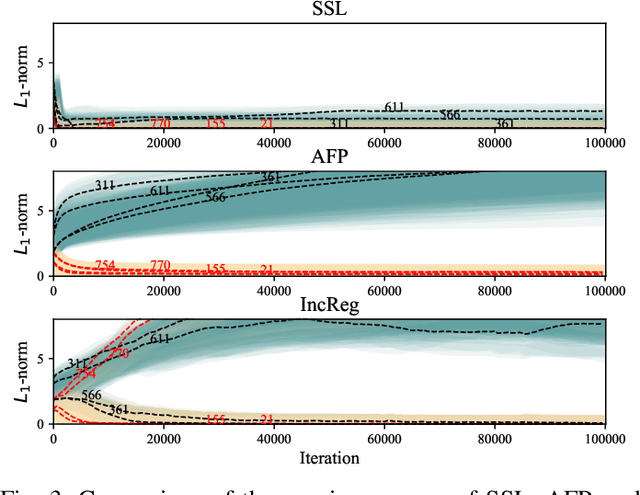
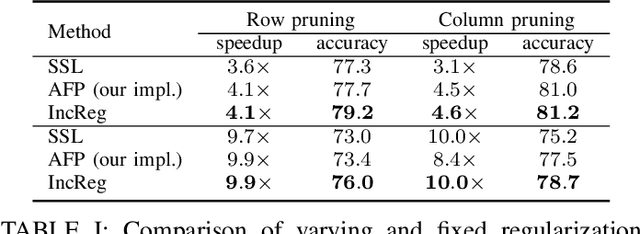
Convolutional Neural Networks (CNN's) are restricted by their massive computation and high storage. Parameter pruning is a promising approach for CNN compression and acceleration, which aims at eliminating redundant model parameters with tolerable performance loss. Despite its effectiveness, existing regularization-based parameter pruning methods usually assign a fixed regularization parameter to all weights, which neglects the fact that different weights may have different importance to CNN. To solve this problem, we propose a theoretically sound regularization-based pruning method to incrementally assign different regularization parameters to different weights based on their importance to the network. On AlexNet and VGG-16, our method can achieve 4x theoretical speedup with similar accuracies compared with the baselines. For ResNet-50, the proposed method also achieves 2x acceleration and only suffers 0.1% top-5 accuracy loss.