 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccent Recognition with Hybrid Phonetic Features
Paper and Code
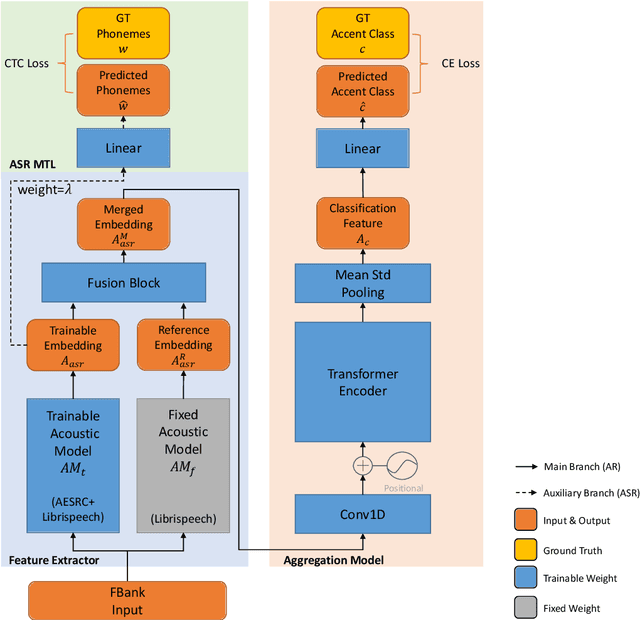

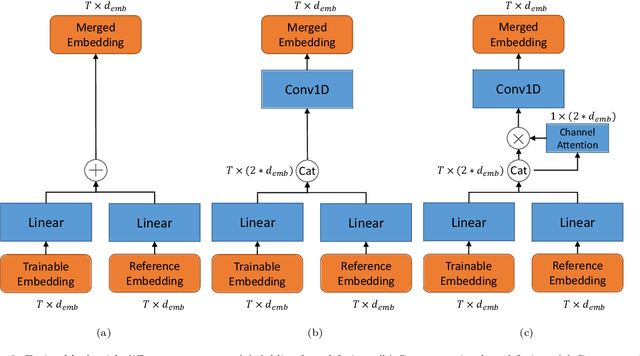
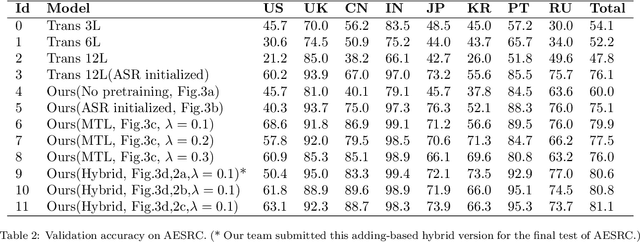
The performance of voice-controlled systems is usually influenced by accented speech. To make these systems more robust, the frontend accent recognition (AR) technologies have received increased attention in recent years. As accent is a high-level abstract feature that has a profound relationship with the language knowledge, AR is more challenging than other language-agnostic audio classification tasks. In this paper, we use an auxiliary automatic speech recognition (ASR) task to extract language-related phonetic features. Furthermore, we propose a hybrid structure that incorporates the embeddings of both a fixed acoustic model and a trainable acoustic model, making the language-related acoustic feature more robust. We conduct several experiments on the Accented English Speech Recognition Challenge (AESRC) 2020 dataset. The results demonstrate that our approach can obtain a 6.57% relative improvement on the validation set. We also get a 7.28% relative improvement on the final test set for this competition, showing the merits of the proposed method.