 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSGaussian: Semantic-Aware and Structure-Preserving 3D Style Transfer
Sep 04, 2025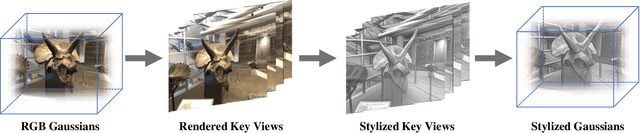
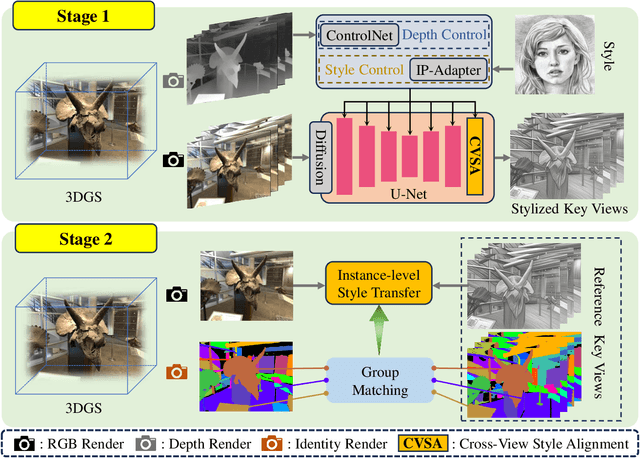


Recent advancements in neural representations, such as Neural Radiance Fields and 3D Gaussian Splatting, have increased interest in applying style transfer to 3D scenes. While existing methods can transfer style patterns onto 3D-consistent neural representations, they struggle to effectively extract and transfer high-level style semantics from the reference style image. Additionally, the stylized results often lack structural clarity and separation, making it difficult to distinguish between different instances or objects within the 3D scene. To address these limitations, we propose a novel 3D style transfer pipeline that effectively integrates prior knowledge from pretrained 2D diffusion models. Our pipeline consists of two key stages: First, we leverage diffusion priors to generate stylized renderings of key viewpoints. Then, we transfer the stylized key views onto the 3D representation. This process incorporates two innovative designs. The first is cross-view style alignment, which inserts cross-view attention into the last upsampling block of the UNet, allowing feature interactions across multiple key views. This ensures that the diffusion model generates stylized key views that maintain both style fidelity and instance-level consistency. The second is instance-level style transfer, which effectively leverages instance-level consistency across stylized key views and transfers it onto the 3D representation. This results in a more structured, visually coherent, and artistically enriched stylization. Extensive qualitative and quantitative experiments demonstrate that our 3D style transfer pipeline significantly outperforms state-of-the-art methods across a wide range of scenes, from forward-facing to challenging 360-degree environments. Visit our project page https://jm-xu.github.io/SSGaussian for immersive visualization.
T2A-Feedback: Improving Basic Capabilities of Text-to-Audio Generation via Fine-grained AI Feedback
May 15, 2025

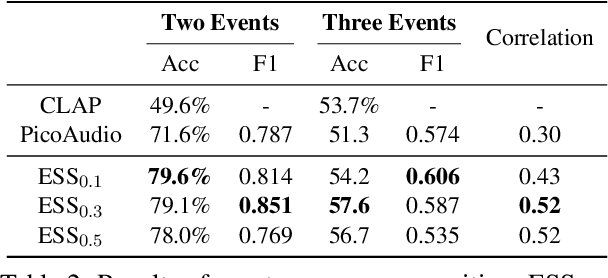

Text-to-audio (T2A) generation has achieved remarkable progress in generating a variety of audio outputs from language prompts. However, current state-of-the-art T2A models still struggle to satisfy human preferences for prompt-following and acoustic quality when generating complex multi-event audio. To improve the performance of the model in these high-level applications, we propose to enhance the basic capabilities of the model with AI feedback learning. First, we introduce fine-grained AI audio scoring pipelines to: 1) verify whether each event in the text prompt is present in the audio (Event Occurrence Score), 2) detect deviations in event sequences from the language description (Event Sequence Score), and 3) assess the overall acoustic and harmonic quality of the generated audio (Acoustic&Harmonic Quality). We evaluate these three automatic scoring pipelines and find that they correlate significantly better with human preferences than other evaluation metrics. This highlights their value as both feedback signals and evaluation metrics. Utilizing our robust scoring pipelines, we construct a large audio preference dataset, T2A-FeedBack, which contains 41k prompts and 249k audios, each accompanied by detailed scores. Moreover, we introduce T2A-EpicBench, a benchmark that focuses on long captions, multi-events, and story-telling scenarios, aiming to evaluate the advanced capabilities of T2A models. Finally, we demonstrate how T2A-FeedBack can enhance current state-of-the-art audio model. With simple preference tuning, the audio generation model exhibits significant improvements in both simple (AudioCaps test set) and complex (T2A-EpicBench) scenarios.
Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis
Feb 26, 2025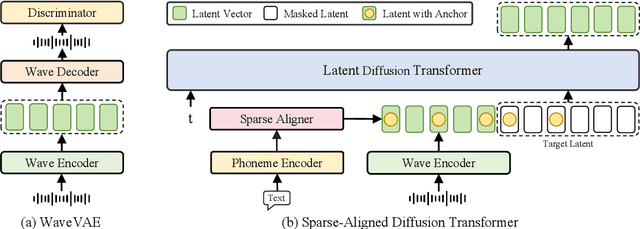
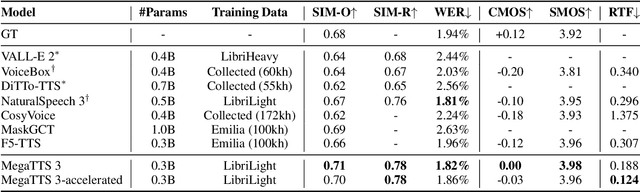
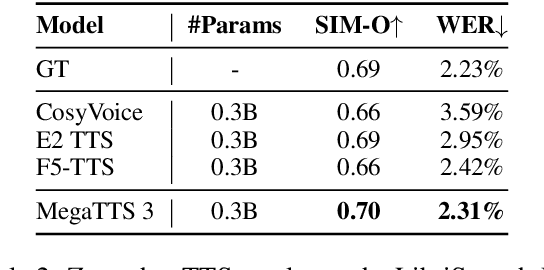

While recent zero-shot text-to-speech (TTS) models have significantly improved speech quality and expressiveness, mainstream systems still suffer from issues related to speech-text alignment modeling: 1) models without explicit speech-text alignment modeling exhibit less robustness, especially for hard sentences in practical applications; 2) predefined alignment-based models suffer from naturalness constraints of forced alignments. This paper introduces \textit{S-DiT}, a TTS system featuring an innovative sparse alignment algorithm that guides the latent diffusion transformer (DiT). Specifically, we provide sparse alignment boundaries to S-DiT to reduce the difficulty of alignment learning without limiting the search space, thereby achieving high naturalness. Moreover, we employ a multi-condition classifier-free guidance strategy for accent intensity adjustment and adopt the piecewise rectified flow technique to accelerate the generation process. Experiments demonstrate that S-DiT achieves state-of-the-art zero-shot TTS speech quality and supports highly flexible control over accent intensity. Notably, our system can generate high-quality one-minute speech with only 8 sampling steps. Audio samples are available at https://sditdemo.github.io/sditdemo/.
HumanDiT: Pose-Guided Diffusion Transformer for Long-form Human Motion Video Generation
Feb 10, 2025



Human motion video generation has advanced significantly, while existing methods still struggle with accurately rendering detailed body parts like hands and faces, especially in long sequences and intricate motions. Current approaches also rely on fixed resolution and struggle to maintain visual consistency. To address these limitations, we propose HumanDiT, a pose-guided Diffusion Transformer (DiT)-based framework trained on a large and wild dataset containing 14,000 hours of high-quality video to produce high-fidelity videos with fine-grained body rendering. Specifically, (i) HumanDiT, built on DiT, supports numerous video resolutions and variable sequence lengths, facilitating learning for long-sequence video generation; (ii) we introduce a prefix-latent reference strategy to maintain personalized characteristics across extended sequences. Furthermore, during inference, HumanDiT leverages Keypoint-DiT to generate subsequent pose sequences, facilitating video continuation from static images or existing videos. It also utilizes a Pose Adapter to enable pose transfer with given sequences. Extensive experiments demonstrate its superior performance in generating long-form, pose-accurate videos across diverse scenarios.
MimicTalk: Mimicking a personalized and expressive 3D talking face in minutes
Oct 09, 2024



Talking face generation (TFG) aims to animate a target identity's face to create realistic talking videos. Personalized TFG is a variant that emphasizes the perceptual identity similarity of the synthesized result (from the perspective of appearance and talking style). While previous works typically solve this problem by learning an individual neural radiance field (NeRF) for each identity to implicitly store its static and dynamic information, we find it inefficient and non-generalized due to the per-identity-per-training framework and the limited training data. To this end, we propose MimicTalk, the first attempt that exploits the rich knowledge from a NeRF-based person-agnostic generic model for improving the efficiency and robustness of personalized TFG. To be specific, (1) we first come up with a person-agnostic 3D TFG model as the base model and propose to adapt it into a specific identity; (2) we propose a static-dynamic-hybrid adaptation pipeline to help the model learn the personalized static appearance and facial dynamic features; (3) To generate the facial motion of the personalized talking style, we propose an in-context stylized audio-to-motion model that mimics the implicit talking style provided in the reference video without information loss by an explicit style representation. The adaptation process to an unseen identity can be performed in 15 minutes, which is 47 times faster than previous person-dependent methods. Experiments show that our MimicTalk surpasses previous baselines regarding video quality, efficiency, and expressiveness. Source code and video samples are available at https://mimictalk.github.io .
MulliVC: Multi-lingual Voice Conversion With Cycle Consistency
Aug 08, 2024Voice conversion aims to modify the source speaker's voice to resemble the target speaker while preserving the original speech content. Despite notable advancements in voice conversion these days, multi-lingual voice conversion (including both monolingual and cross-lingual scenarios) has yet to be extensively studied. It faces two main challenges: 1) the considerable variability in prosody and articulation habits across languages; and 2) the rarity of paired multi-lingual datasets from the same speaker. In this paper, we propose MulliVC, a novel voice conversion system that only converts timbre and keeps original content and source language prosody without multi-lingual paired data. Specifically, each training step of MulliVC contains three substeps: In step one the model is trained with monolingual speech data; then, steps two and three take inspiration from back translation, construct a cyclical process to disentangle the timbre and other information (content, prosody, and other language-related information) in the absence of multi-lingual data from the same speaker. Both objective and subjective results indicate that MulliVC significantly surpasses other methods in both monolingual and cross-lingual contexts, demonstrating the system's efficacy and the viability of the three-step approach with cycle consistency. Audio samples can be found on our demo page (mullivc.github.io).
FreeBind: Free Lunch in Unified Multimodal Space via Knowledge Fusion
May 10, 2024



Unified multi-model representation spaces are the foundation of multimodal understanding and generation. However, the billions of model parameters and catastrophic forgetting problems make it challenging to further enhance pre-trained unified spaces. In this work, we propose FreeBind, an idea that treats multimodal representation spaces as basic units, and freely augments pre-trained unified space by integrating knowledge from extra expert spaces via "space bonds". Specifically, we introduce two kinds of basic space bonds: 1) Space Displacement Bond and 2) Space Combination Bond. Based on these basic bonds, we design Complex Sequential & Parallel Bonds to effectively integrate multiple spaces simultaneously. Benefiting from the modularization concept, we further propose a coarse-to-fine customized inference strategy to flexibly adjust the enhanced unified space for different purposes. Experimentally, we bind ImageBind with extra image-text and audio-text expert spaces, resulting in three main variants: ImageBind++, InternVL_IB, and InternVL_IB++. These resulting spaces outperform ImageBind on 5 audio-image-text downstream tasks across 9 datasets. Moreover, via customized inference, it even surpasses the advanced audio-text and image-text expert spaces.
Molecule-Space: Free Lunch in Unified Multimodal Space via Knowledge Fusion
May 08, 2024Unified multi-model representation spaces are the foundation of multimodal understanding and generation. However, the billions of model parameters and catastrophic forgetting problems make it challenging to further enhance pre-trained unified spaces. In this work, we propose Molecule-Space, an idea that treats multimodal representation spaces as "molecules", and augments pre-trained unified space by integrating knowledge from extra expert spaces via "molecules space reactions". Specifically, we introduce two kinds of basic space reactions: 1) Space Displacement Reaction and 2) Space Combination Reaction. Based on these defined basic reactions, we design Complex Sequential & Parallel Reactions to effectively integrate multiple spaces simultaneously. Benefiting from the modularization concept, we further propose a coarse-to-fine customized inference strategy to flexibly adjust the enhanced unified space for different purposes. Experimentally, we fuse the audio-image-text space of ImageBind with the image-text and audio-text expert spaces. The resulting space outperforms ImageBind on 5 downstream tasks across 9 datasets. Moreover, via customized inference, it even surpasses the used image-text and audio-text expert spaces.
Real3D-Portrait: One-shot Realistic 3D Talking Portrait Synthesis
Jan 20, 2024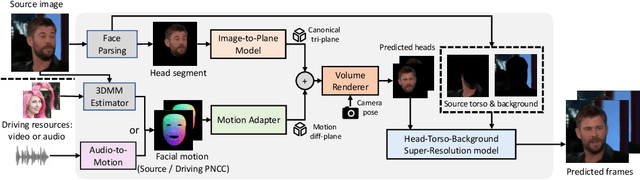

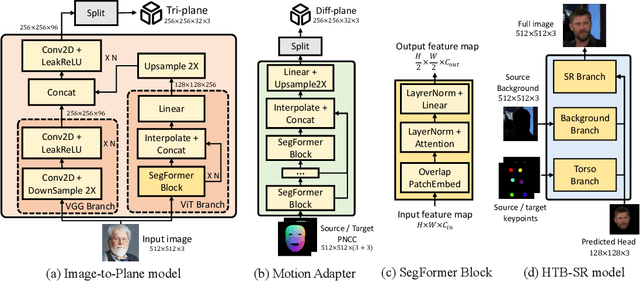
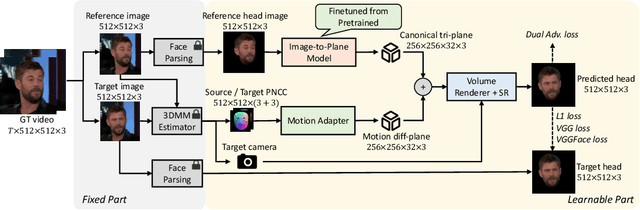
One-shot 3D talking portrait generation aims to reconstruct a 3D avatar from an unseen image, and then animate it with a reference video or audio to generate a talking portrait video. The existing methods fail to simultaneously achieve the goals of accurate 3D avatar reconstruction and stable talking face animation. Besides, while the existing works mainly focus on synthesizing the head part, it is also vital to generate natural torso and background segments to obtain a realistic talking portrait video. To address these limitations, we present Real3D-Potrait, a framework that (1) improves the one-shot 3D reconstruction power with a large image-to-plane model that distills 3D prior knowledge from a 3D face generative model; (2) facilitates accurate motion-conditioned animation with an efficient motion adapter; (3) synthesizes realistic video with natural torso movement and switchable background using a head-torso-background super-resolution model; and (4) supports one-shot audio-driven talking face generation with a generalizable audio-to-motion model. Extensive experiments show that Real3D-Portrait generalizes well to unseen identities and generates more realistic talking portrait videos compared to previous methods. Video samples and source code are available at https://real3dportrait.github.io .
Mega-TTS 2: Zero-Shot Text-to-Speech with Arbitrary Length Speech Prompts
Jul 14, 2023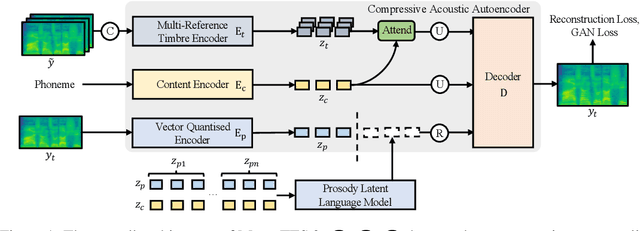
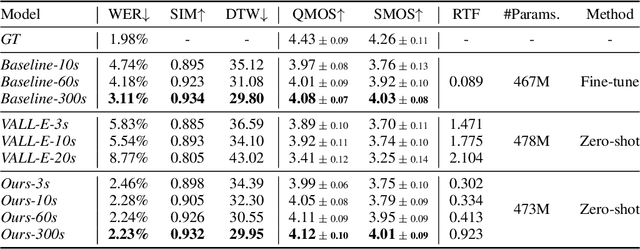
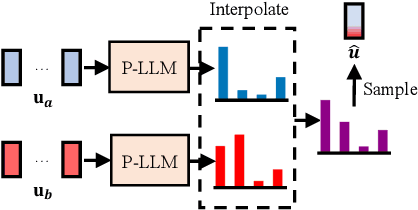

Zero-shot text-to-speech aims at synthesizing voices with unseen speech prompts. Previous large-scale multispeaker TTS models have successfully achieved this goal with an enrolled recording within 10 seconds. However, most of them are designed to utilize only short speech prompts. The limited information in short speech prompts significantly hinders the performance of fine-grained identity imitation. In this paper, we introduce Mega-TTS 2, a generic zero-shot multispeaker TTS model that is capable of synthesizing speech for unseen speakers with arbitrary-length prompts. Specifically, we 1) design a multi-reference timbre encoder to extract timbre information from multiple reference speeches; 2) and train a prosody language model with arbitrary-length speech prompts; With these designs, our model is suitable for prompts of different lengths, which extends the upper bound of speech quality for zero-shot text-to-speech. Besides arbitrary-length prompts, we introduce arbitrary-source prompts, which leverages the probabilities derived from multiple P-LLM outputs to produce expressive and controlled prosody. Furthermore, we propose a phoneme-level auto-regressive duration model to introduce in-context learning capabilities to duration modeling. Experiments demonstrate that our method could not only synthesize identity-preserving speech with a short prompt of an unseen speaker but also achieve improved performance with longer speech prompts. Audio samples can be found in https://mega-tts.github.io/mega2_demo/.