 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAda-TTA: Towards Adaptive High-Quality Text-to-Talking Avatar Synthesis
Paper and Code
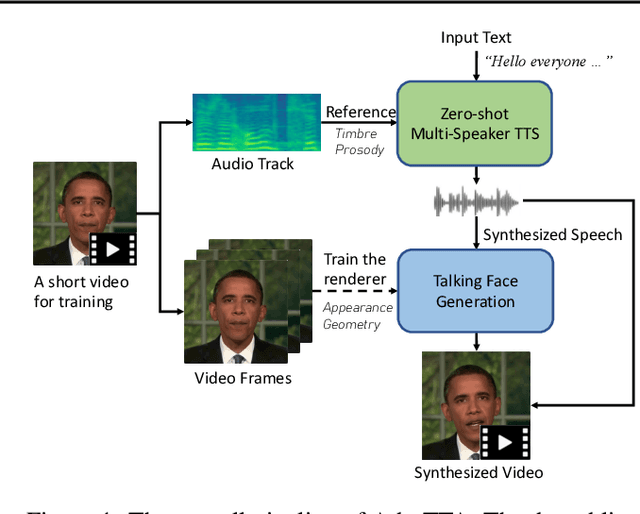



We are interested in a novel task, namely low-resource text-to-talking avatar. Given only a few-minute-long talking person video with the audio track as the training data and arbitrary texts as the driving input, we aim to synthesize high-quality talking portrait videos corresponding to the input text. This task has broad application prospects in the digital human industry but has not been technically achieved yet due to two challenges: (1) It is challenging to mimic the timbre from out-of-domain audio for a traditional multi-speaker Text-to-Speech system. (2) It is hard to render high-fidelity and lip-synchronized talking avatars with limited training data. In this paper, we introduce Adaptive Text-to-Talking Avatar (Ada-TTA), which (1) designs a generic zero-shot multi-speaker TTS model that well disentangles the text content, timbre, and prosody; and (2) embraces recent advances in neural rendering to achieve realistic audio-driven talking face video generation. With these designs, our method overcomes the aforementioned two challenges and achieves to generate identity-preserving speech and realistic talking person video. Experiments demonstrate that our method could synthesize realistic, identity-preserving, and audio-visual synchronized talking avatar videos.