 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImVideoEdit: Image-learning Video Editing via 2D Spatial Difference Attention Blocks
Apr 09, 2026Current video editing models often rely on expensive paired video data, which limits their practical scalability. In essence, most video editing tasks can be formulated as a decoupled spatiotemporal process, where the temporal dynamics of the pretrained model are preserved while spatial content is selectively and precisely modified. Based on this insight, we propose ImVideoEdit, an efficient framework that learns video editing capabilities entirely from image pairs. By freezing the pre-trained 3D attention modules and treating images as single-frame videos, we decouple the 2D spatial learning process to help preserve the original temporal dynamics. The core of our approach is a Predict-Update Spatial Difference Attention module that progressively extracts and injects spatial differences. Rather than relying on rigid external masks, we incorporate a Text-Guided Dynamic Semantic Gating mechanism for adaptive and implicit text-driven modifications. Despite training on only 13K image pairs for 5 epochs with exceptionally low computational overhead, ImVideoEdit achieves editing fidelity and temporal consistency comparable to larger models trained on extensive video datasets.
Chat-Scene++: Exploiting Context-Rich Object Identification for 3D LLM
Mar 29, 2026Recent advancements in multi-modal large language models (MLLMs) have shown strong potential for 3D scene understanding. However, existing methods struggle with fine-grained object grounding and contextual reasoning, limiting their ability to interpret and interact with complex 3D environments. In this paper, we present Chat-Scene++, an MLLM framework that represents 3D scenes as context-rich object sequences. By structuring scenes as sequences of objects with contextual semantics, Chat-Scene++ enables object-centric representation and interaction. It decomposes a 3D scene into object representations paired with identifier tokens, allowing LLMs to follow instructions across diverse 3D vision-language tasks. To capture inter-object relationships and global semantics, Chat-Scene++ extracts context-rich object features using large-scale pre-trained 3D scene-level and 2D image-level encoders, unlike the isolated per-object features in Chat-Scene. Its flexible object-centric design also supports grounded chain-of-thought (G-CoT) reasoning, enabling the model to distinguish objects at both category and spatial levels during multi-step inference. Without the need for additional task-specific heads or fine-tuning, Chat-Scene++ achieves state-of-the-art performance on five major 3D vision-language benchmarks: ScanRefer, Multi3DRefer, Scan2Cap, ScanQA, and SQA3D. These results highlight its effectiveness in scene comprehension, object grounding, and spatial reasoning. Additionally, without reconstructing 3D worlds through computationally expensive processes, we demonstrate its applicability to real-world scenarios using only 2D inputs.
WorldCompass: Reinforcement Learning for Long-Horizon World Models
Feb 09, 2026This work presents WorldCompass, a novel Reinforcement Learning (RL) post-training framework for the long-horizon, interactive video-based world models, enabling them to explore the world more accurately and consistently based on interaction signals. To effectively "steer" the world model's exploration, we introduce three core innovations tailored to the autoregressive video generation paradigm: 1) Clip-level rollout Strategy: We generate and evaluate multiple samples at a single target clip, which significantly boosts rollout efficiency and provides fine-grained reward signals. 2) Complementary Reward Functions: We design reward functions for both interaction-following accuracy and visual quality, which provide direct supervision and effectively suppress reward-hacking behaviors. 3) Efficient RL Algorithm: We employ the negative-aware fine-tuning strategy coupled with various efficiency optimizations to efficiently and effectively enhance model capacity. Evaluations on the SoTA open-source world model, WorldPlay, demonstrate that WorldCompass significantly improves interaction accuracy and visual fidelity across various scenarios.
WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Modeling
Dec 16, 2025This paper presents WorldPlay, a streaming video diffusion model that enables real-time, interactive world modeling with long-term geometric consistency, resolving the trade-off between speed and memory that limits current methods. WorldPlay draws power from three key innovations. 1) We use a Dual Action Representation to enable robust action control in response to the user's keyboard and mouse inputs. 2) To enforce long-term consistency, our Reconstituted Context Memory dynamically rebuilds context from past frames and uses temporal reframing to keep geometrically important but long-past frames accessible, effectively alleviating memory attenuation. 3) We also propose Context Forcing, a novel distillation method designed for memory-aware model. Aligning memory context between the teacher and student preserves the student's capacity to use long-range information, enabling real-time speeds while preventing error drift. Taken together, WorldPlay generates long-horizon streaming 720p video at 24 FPS with superior consistency, comparing favorably with existing techniques and showing strong generalization across diverse scenes. Project page and online demo can be found: https://3d-models.hunyuan.tencent.com/world/ and https://3d.hunyuan.tencent.com/sceneTo3D.
DSI-Bench: A Benchmark for Dynamic Spatial Intelligence
Oct 21, 2025Reasoning about dynamic spatial relationships is essential, as both observers and objects often move simultaneously. Although vision-language models (VLMs) and visual expertise models excel in 2D tasks and static scenarios, their ability to fully understand dynamic 3D scenarios remains limited. We introduce Dynamic Spatial Intelligence and propose DSI-Bench, a benchmark with nearly 1,000 dynamic videos and over 1,700 manually annotated questions covering nine decoupled motion patterns of observers and objects. Spatially and temporally symmetric designs reduce biases and enable systematic evaluation of models' reasoning about self-motion and object motion. Our evaluation of 14 VLMs and expert models reveals key limitations: models often conflate observer and object motion, exhibit semantic biases, and fail to accurately infer relative relationships in dynamic scenarios. Our DSI-Bench provides valuable findings and insights about the future development of general and expertise models with dynamic spatial intelligence.
GenSpace: Benchmarking Spatially-Aware Image Generation
May 30, 2025

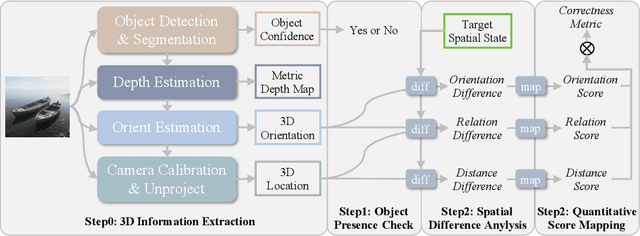
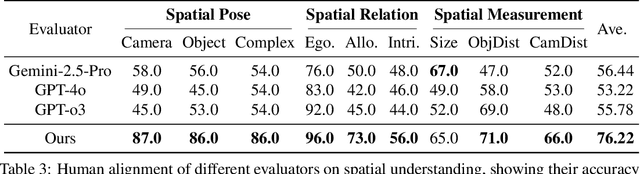
Humans can intuitively compose and arrange scenes in the 3D space for photography. However, can advanced AI image generators plan scenes with similar 3D spatial awareness when creating images from text or image prompts? We present GenSpace, a novel benchmark and evaluation pipeline to comprehensively assess the spatial awareness of current image generation models. Furthermore, standard evaluations using general Vision-Language Models (VLMs) frequently fail to capture the detailed spatial errors. To handle this challenge, we propose a specialized evaluation pipeline and metric, which reconstructs 3D scene geometry using multiple visual foundation models and provides a more accurate and human-aligned metric of spatial faithfulness. Our findings show that while AI models create visually appealing images and can follow general instructions, they struggle with specific 3D details like object placement, relationships, and measurements. We summarize three core limitations in the spatial perception of current state-of-the-art image generation models: 1) Object Perspective Understanding, 2) Egocentric-Allocentric Transformation and 3) Metric Measurement Adherence, highlighting possible directions for improving spatial intelligence in image generation.
Depth Anything with Any Prior
May 15, 2025This work presents Prior Depth Anything, a framework that combines incomplete but precise metric information in depth measurement with relative but complete geometric structures in depth prediction, generating accurate, dense, and detailed metric depth maps for any scene. To this end, we design a coarse-to-fine pipeline to progressively integrate the two complementary depth sources. First, we introduce pixel-level metric alignment and distance-aware weighting to pre-fill diverse metric priors by explicitly using depth prediction. It effectively narrows the domain gap between prior patterns, enhancing generalization across varying scenarios. Second, we develop a conditioned monocular depth estimation (MDE) model to refine the inherent noise of depth priors. By conditioning on the normalized pre-filled prior and prediction, the model further implicitly merges the two complementary depth sources. Our model showcases impressive zero-shot generalization across depth completion, super-resolution, and inpainting over 7 real-world datasets, matching or even surpassing previous task-specific methods. More importantly, it performs well on challenging, unseen mixed priors and enables test-time improvements by switching prediction models, providing a flexible accuracy-efficiency trade-off while evolving with advancements in MDE models.
T2A-Feedback: Improving Basic Capabilities of Text-to-Audio Generation via Fine-grained AI Feedback
May 15, 2025

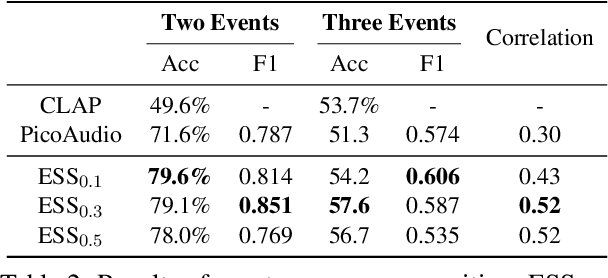

Text-to-audio (T2A) generation has achieved remarkable progress in generating a variety of audio outputs from language prompts. However, current state-of-the-art T2A models still struggle to satisfy human preferences for prompt-following and acoustic quality when generating complex multi-event audio. To improve the performance of the model in these high-level applications, we propose to enhance the basic capabilities of the model with AI feedback learning. First, we introduce fine-grained AI audio scoring pipelines to: 1) verify whether each event in the text prompt is present in the audio (Event Occurrence Score), 2) detect deviations in event sequences from the language description (Event Sequence Score), and 3) assess the overall acoustic and harmonic quality of the generated audio (Acoustic&Harmonic Quality). We evaluate these three automatic scoring pipelines and find that they correlate significantly better with human preferences than other evaluation metrics. This highlights their value as both feedback signals and evaluation metrics. Utilizing our robust scoring pipelines, we construct a large audio preference dataset, T2A-FeedBack, which contains 41k prompts and 249k audios, each accompanied by detailed scores. Moreover, we introduce T2A-EpicBench, a benchmark that focuses on long captions, multi-events, and story-telling scenarios, aiming to evaluate the advanced capabilities of T2A models. Finally, we demonstrate how T2A-FeedBack can enhance current state-of-the-art audio model. With simple preference tuning, the audio generation model exhibits significant improvements in both simple (AudioCaps test set) and complex (T2A-EpicBench) scenarios.
RoboGround: Robotic Manipulation with Grounded Vision-Language Priors
Apr 30, 2025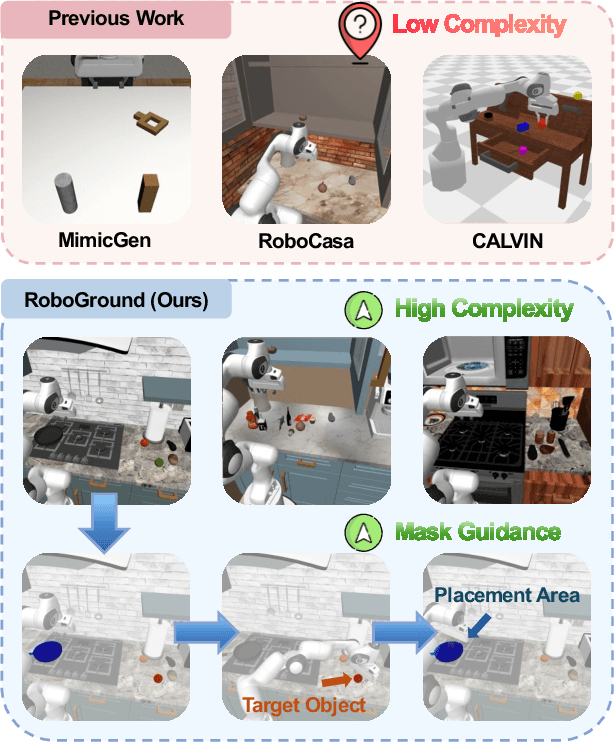

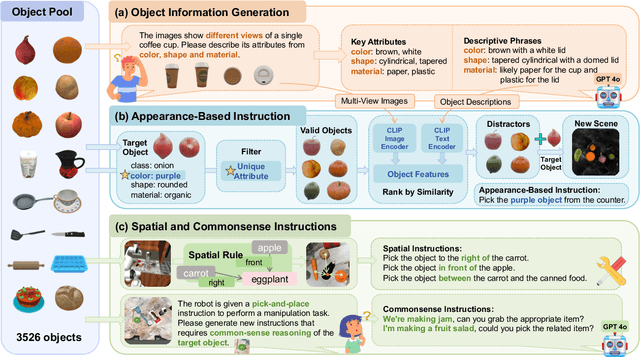
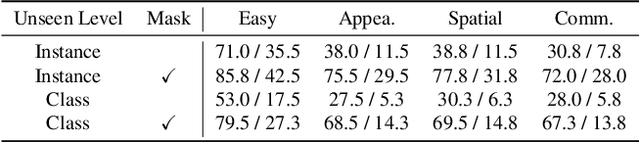
Recent advancements in robotic manipulation have highlighted the potential of intermediate representations for improving policy generalization. In this work, we explore grounding masks as an effective intermediate representation, balancing two key advantages: (1) effective spatial guidance that specifies target objects and placement areas while also conveying information about object shape and size, and (2) broad generalization potential driven by large-scale vision-language models pretrained on diverse grounding datasets. We introduce RoboGround, a grounding-aware robotic manipulation system that leverages grounding masks as an intermediate representation to guide policy networks in object manipulation tasks. To further explore and enhance generalization, we propose an automated pipeline for generating large-scale, simulated data with a diverse set of objects and instructions. Extensive experiments show the value of our dataset and the effectiveness of grounding masks as intermediate guidance, significantly enhancing the generalization abilities of robot policies.
Diff-Prompt: Diffusion-Driven Prompt Generator with Mask Supervision
Apr 30, 2025Prompt learning has demonstrated promising results in fine-tuning pre-trained multimodal models. However, the performance improvement is limited when applied to more complex and fine-grained tasks. The reason is that most existing methods directly optimize the parameters involved in the prompt generation process through loss backpropagation, which constrains the richness and specificity of the prompt representations. In this paper, we propose Diffusion-Driven Prompt Generator (Diff-Prompt), aiming to use the diffusion model to generate rich and fine-grained prompt information for complex downstream tasks. Specifically, our approach consists of three stages. In the first stage, we train a Mask-VAE to compress the masks into latent space. In the second stage, we leverage an improved Diffusion Transformer (DiT) to train a prompt generator in the latent space, using the masks for supervision. In the third stage, we align the denoising process of the prompt generator with the pre-trained model in the semantic space, and use the generated prompts to fine-tune the model. We conduct experiments on a complex pixel-level downstream task, referring expression comprehension, and compare our method with various parameter-efficient fine-tuning approaches. Diff-Prompt achieves a maximum improvement of 8.87 in R@1 and 14.05 in R@5 compared to the foundation model and also outperforms other state-of-the-art methods across multiple metrics. The experimental results validate the effectiveness of our approach and highlight the potential of using generative models for prompt generation. Code is available at https://github.com/Kelvin-ywc/diff-prompt.