 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSI-Bench: A Benchmark for Dynamic Spatial Intelligence
Oct 21, 2025Reasoning about dynamic spatial relationships is essential, as both observers and objects often move simultaneously. Although vision-language models (VLMs) and visual expertise models excel in 2D tasks and static scenarios, their ability to fully understand dynamic 3D scenarios remains limited. We introduce Dynamic Spatial Intelligence and propose DSI-Bench, a benchmark with nearly 1,000 dynamic videos and over 1,700 manually annotated questions covering nine decoupled motion patterns of observers and objects. Spatially and temporally symmetric designs reduce biases and enable systematic evaluation of models' reasoning about self-motion and object motion. Our evaluation of 14 VLMs and expert models reveals key limitations: models often conflate observer and object motion, exhibit semantic biases, and fail to accurately infer relative relationships in dynamic scenarios. Our DSI-Bench provides valuable findings and insights about the future development of general and expertise models with dynamic spatial intelligence.
CMMCoT: Enhancing Complex Multi-Image Comprehension via Multi-Modal Chain-of-Thought and Memory Augmentation
Mar 07, 2025



While previous multimodal slow-thinking methods have demonstrated remarkable success in single-image understanding scenarios, their effectiveness becomes fundamentally constrained when extended to more complex multi-image comprehension tasks. This limitation stems from their predominant reliance on text-based intermediate reasoning processes. While for human, when engaging in sophisticated multi-image analysis, they typically perform two complementary cognitive operations: (1) continuous cross-image visual comparison through region-of-interest matching, and (2) dynamic memorization of critical visual concepts throughout the reasoning chain. Motivated by these observations, we propose the Complex Multi-Modal Chain-of-Thought (CMMCoT) framework, a multi-step reasoning framework that mimics human-like "slow thinking" for multi-image understanding. Our approach incorporates two key innovations: 1. The construction of interleaved multimodal multi-step reasoning chains, which utilize critical visual region tokens, extracted from intermediate reasoning steps, as supervisory signals. This mechanism not only facilitates comprehensive cross-modal understanding but also enhances model interpretability. 2. The introduction of a test-time memory augmentation module that expands the model reasoning capacity during inference while preserving parameter efficiency. Furthermore, to facilitate research in this direction, we have curated a novel multi-image slow-thinking dataset. Extensive experiments demonstrate the effectiveness of our model.
MINT: Multi-modal Chain of Thought in Unified Generative Models for Enhanced Image Generation
Mar 03, 2025Unified generative models have demonstrated extraordinary performance in both text and image generation. However, they tend to underperform when generating intricate images with various interwoven conditions, which is hard to solely rely on straightforward text-to-image generation. In response to this challenge, we introduce MINT, an innovative unified generative model, empowered with native multimodal chain of thought (MCoT) for enhanced image generation for the first time. Firstly, we design Mixture of Transformer Experts (MTXpert), an expert-parallel structure that effectively supports both natural language generation (NLG) and visual capabilities, while avoiding potential modality conflicts that could hinder the full potential of each modality. Building on this, we propose an innovative MCoT training paradigm, a step-by-step approach to multimodal thinking, reasoning, and reflection specifically designed to enhance image generation. This paradigm equips MINT with nuanced, element-wise decoupled alignment and a comprehensive understanding of textual and visual components. Furthermore, it fosters advanced multimodal reasoning and self-reflection, enabling the construction of images that are firmly grounded in the logical relationships between these elements. Notably, MINT has been validated to exhibit superior performance across multiple benchmarks for text-to-image (T2I) and image-to-text (I2T) tasks.
CustomVideoX: 3D Reference Attention Driven Dynamic Adaptation for Zero-Shot Customized Video Diffusion Transformers
Feb 10, 2025Customized generation has achieved significant progress in image synthesis, yet personalized video generation remains challenging due to temporal inconsistencies and quality degradation. In this paper, we introduce CustomVideoX, an innovative framework leveraging the video diffusion transformer for personalized video generation from a reference image. CustomVideoX capitalizes on pre-trained video networks by exclusively training the LoRA parameters to extract reference features, ensuring both efficiency and adaptability. To facilitate seamless interaction between the reference image and video content, we propose 3D Reference Attention, which enables direct and simultaneous engagement of reference image features with all video frames across spatial and temporal dimensions. To mitigate the excessive influence of reference image features and textual guidance on generated video content during inference, we implement the Time-Aware Reference Attention Bias (TAB) strategy, dynamically modulating reference bias over different time steps. Additionally, we introduce the Entity Region-Aware Enhancement (ERAE) module, aligning highly activated regions of key entity tokens with reference feature injection by adjusting attention bias. To thoroughly evaluate personalized video generation, we establish a new benchmark, VideoBench, comprising over 50 objects and 100 prompts for extensive assessment. Experimental results show that CustomVideoX significantly outperforms existing methods in terms of video consistency and quality.
Development and Testing of a Wood Panels Bark Removal Equipment Based on Deep Learning
Oct 15, 2024Attempting to apply deep learning methods to wood panels bark removal equipment to enhance the quality and efficiency of bark removal is a significant and challenging endeavor. This study develops and tests a deep learning-based wood panels bark removal equipment. In accordance with the practical requirements of sawmills, a wood panels bark removal equipment equipped with a vision inspection system is designed. Based on a substantial collection of wood panel images obtained using the visual inspection system, the first general wood panels semantic segmentation dataset is constructed for training the BiSeNetV1 model employed in this study. Furthermore, the calculation methods and processes for the essential key data required in the bark removal process are presented in detail. Comparative experiments of the BiSeNetV1 model and tests of bark removal effectiveness are conducted in both laboratory and sawmill environments. The results of the comparative experiments indicate that the application of the BiSeNetV1 segmentation model is rational and feasible. The results of the bark removal effectiveness tests demonstrate a significant improvement in both the quality and efficiency of bark removal. The developed equipment fully meets the sawmill's requirements for precision and efficiency in bark removal processing.
LLaVA-MoD: Making LLaVA Tiny via MoE Knowledge Distillation
Aug 28, 2024We introduce LLaVA-MoD, a novel framework designed to enable the efficient training of small-scale Multimodal Language Models (s-MLLM) by distilling knowledge from large-scale MLLM (l-MLLM). Our approach tackles two fundamental challenges in MLLM distillation. First, we optimize the network structure of s-MLLM by integrating a sparse Mixture of Experts (MoE) architecture into the language model, striking a balance between computational efficiency and model expressiveness. Second, we propose a progressive knowledge transfer strategy to ensure comprehensive knowledge migration. This strategy begins with mimic distillation, where we minimize the Kullback-Leibler (KL) divergence between output distributions to enable the student model to emulate the teacher network's understanding. Following this, we introduce preference distillation via Direct Preference Optimization (DPO), where the key lies in treating l-MLLM as the reference model. During this phase, the s-MLLM's ability to discriminate between superior and inferior examples is significantly enhanced beyond l-MLLM, leading to a better student that surpasses its teacher, particularly in hallucination benchmarks. Extensive experiments demonstrate that LLaVA-MoD outperforms existing models across various multimodal benchmarks while maintaining a minimal number of activated parameters and low computational costs. Remarkably, LLaVA-MoD, with only 2B activated parameters, surpasses Qwen-VL-Chat-7B by an average of 8.8% across benchmarks, using merely 0.3% of the training data and 23% trainable parameters. These results underscore LLaVA-MoD's ability to effectively distill comprehensive knowledge from its teacher model, paving the way for the development of more efficient MLLMs. The code will be available on: https://github.com/shufangxun/LLaVA-MoD.
WPS-Dataset: A benchmark for wood plate segmentation in bark removal processing
Apr 17, 2024
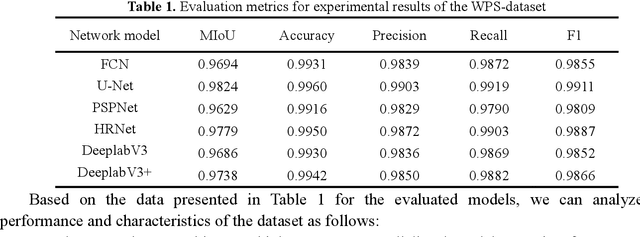


Using deep learning methods is a promising approach to improving bark removal efficiency and enhancing the quality of wood products. However, the lack of publicly available datasets for wood plate segmentation in bark removal processing poses challenges for researchers in this field. To address this issue, a benchmark for wood plate segmentation in bark removal processing named WPS-dataset is proposed in this study, which consists of 4863 images. We designed an image acquisition device and assembled it on a bark removal equipment to capture images in real industrial settings. We evaluated the WPS-dataset using six typical segmentation models. The models effectively learn and understand the WPS-dataset characteristics during training, resulting in high performance and accuracy in wood plate segmentation tasks. We believe that our dataset can lay a solid foundation for future research in bark removal processing and contribute to advancements in this field.
Modeling Historical AIS Data For Vessel Path Prediction: A Comprehensive Treatment
Jan 02, 2020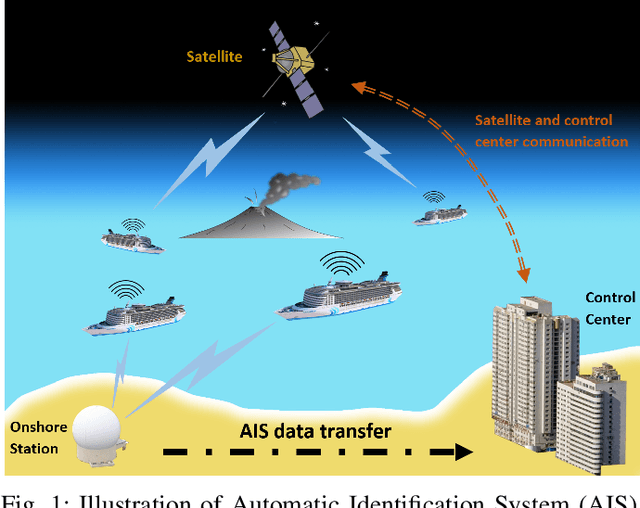
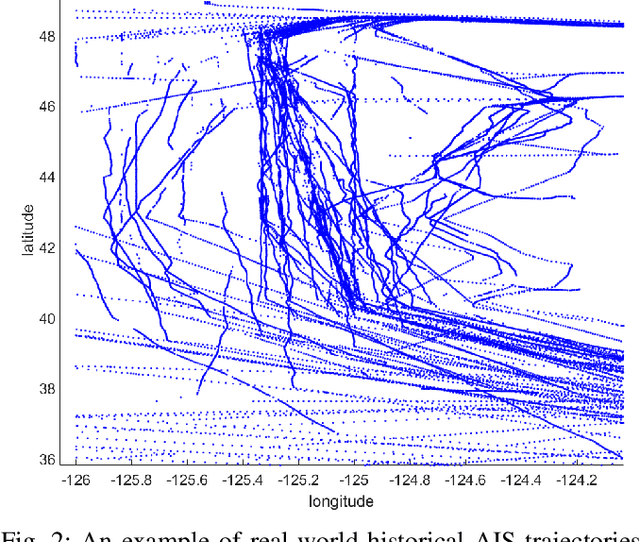
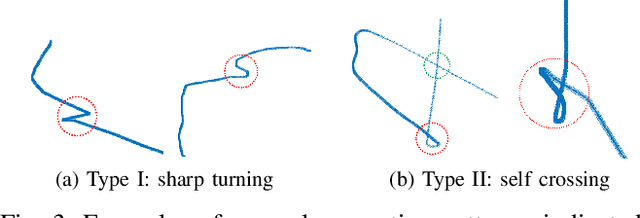
The prosperity of artificial intelligence has aroused intensive interests in intelligent/autonomous navigation, in which path prediction is a key functionality for decision supports, e.g. route planning, collision warning, and traffic regulation. For maritime intelligence, Automatic Identification System (AIS) plays an important role because it recently has been made compulsory for large international commercial vessels and is able to provide nearly real-time information of the vessel. Therefore AIS data based vessel path prediction is a promising way in future maritime intelligence. However, real-world AIS data collected online are just highly irregular trajectory segments (AIS message sequences) from different types of vessels and geographical regions, with possibly very low data quality. So even there are some works studying how to build a path prediction model using historical AIS data, but still, it is a very challenging problem. In this paper, we propose a comprehensive framework to model massive historical AIS trajectory segments for accurate vessel path prediction. Experimental comparisons with existing popular methods are made to validate the proposed approach and results show that our approach could outperform the baseline methods by a wide margin.
A Theoretical Study of The Relationship Between Whole An ELM Network and Its Subnetworks
Oct 30, 2016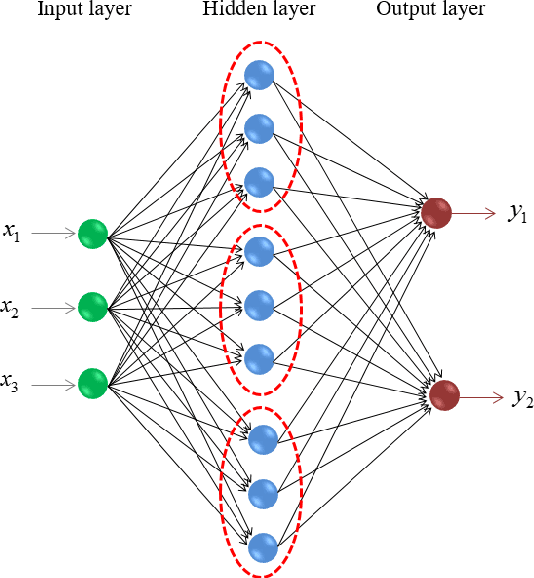
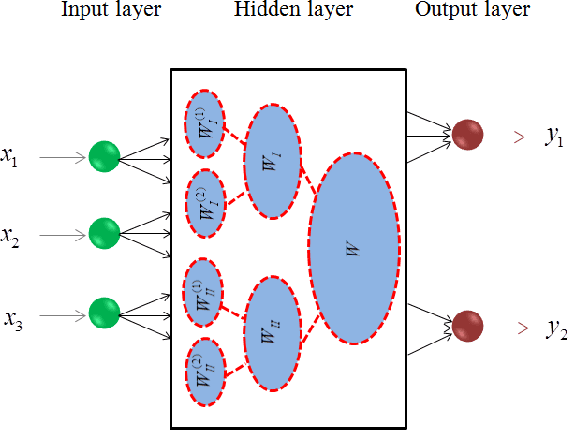
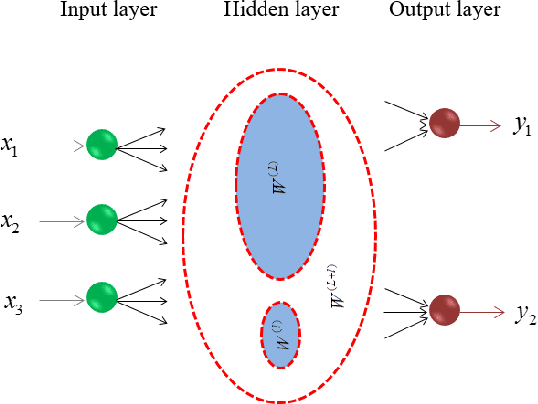
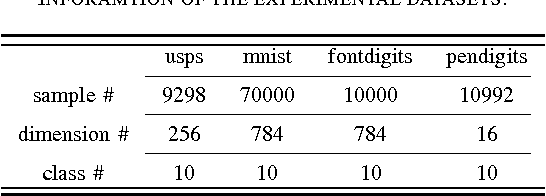
A biological neural network is constituted by numerous subnetworks and modules with different functionalities. For an artificial neural network, the relationship between a network and its subnetworks is also important and useful for both theoretical and algorithmic research, i.e. it can be exploited to develop incremental network training algorithm or parallel network training algorithm. In this paper we explore the relationship between an ELM neural network and its subnetworks. To the best of our knowledge, we are the first to prove a theorem that shows an ELM neural network can be scattered into subnetworks and its optimal solution can be constructed recursively by the optimal solutions of these subnetworks. Based on the theorem we also present two algorithms to train a large ELM neural network efficiently: one is a parallel network training algorithm and the other is an incremental network training algorithm. The experimental results demonstrate the usefulness of the theorem and the validity of the developed algorithms.