 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSKETCH: Semantic Key-Point Conditioning for Long-Horizon Vessel Trajectory Prediction
Jan 26, 2026Accurate long-horizon vessel trajectory prediction remains challenging due to compounded uncertainty from complex navigation behaviors and environmental factors. Existing methods often struggle to maintain global directional consistency, leading to drifting or implausible trajectories when extrapolated over long time horizons. To address this issue, we propose a semantic-key-point-conditioned trajectory modeling framework, in which future trajectories are predicted by conditioning on a high-level Next Key Point (NKP) that captures navigational intent. This formulation decomposes long-horizon prediction into global semantic decision-making and local motion modeling, effectively restricting the support of future trajectories to semantically feasible subsets. To efficiently estimate the NKP prior from historical observations, we adopt a pretrain-finetune strategy. Extensive experiments on real-world AIS data demonstrate that the proposed method consistently outperforms state-of-the-art approaches, particularly for long travel durations, directional accuracy, and fine-grained trajectory prediction.
AIS Data-Driven Maritime Monitoring Based on Transformer: A Comprehensive Review
May 12, 2025



With the increasing demands for safety, efficiency, and sustainability in global shipping, Automatic Identification System (AIS) data plays an increasingly important role in maritime monitoring. AIS data contains spatial-temporal variation patterns of vessels that hold significant research value in the marine domain. However, due to its massive scale, the full potential of AIS data has long remained untapped. With its powerful sequence modeling capabilities, particularly its ability to capture long-range dependencies and complex temporal dynamics, the Transformer model has emerged as an effective tool for processing AIS data. Therefore, this paper reviews the research on Transformer-based AIS data-driven maritime monitoring, providing a comprehensive overview of the current applications of Transformer models in the marine field. The focus is on Transformer-based trajectory prediction methods, behavior detection, and prediction techniques. Additionally, this paper collects and organizes publicly available AIS datasets from the reviewed papers, performing data filtering, cleaning, and statistical analysis. The statistical results reveal the operational characteristics of different vessel types, providing data support for further research on maritime monitoring tasks. Finally, we offer valuable suggestions for future research, identifying two promising research directions. Datasets are available at https://github.com/eyesofworld/Maritime-Monitoring.
Stereo Endoscopic Image Super-Resolution Using Disparity-Constrained Parallel Attention
Mar 19, 2020
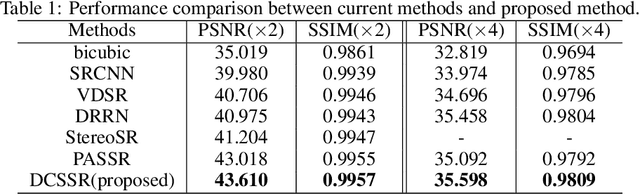
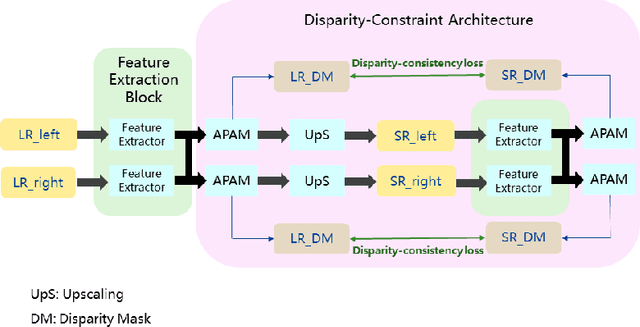
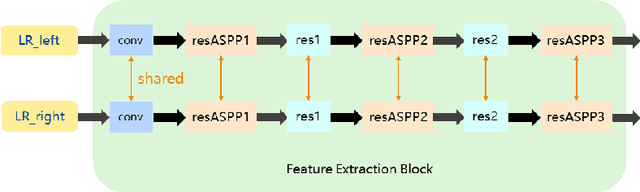
With the popularity of stereo cameras in computer assisted surgery techniques, a second viewpoint would provide additional information in surgery. However, how to effectively access and use stereo information for the super-resolution (SR) purpose is often a challenge. In this paper, we propose a disparity-constrained stereo super-resolution network (DCSSRnet) to simultaneously compute a super-resolved image in a stereo image pair. In particular, we incorporate a disparity-based constraint mechanism into the generation of SR images in a deep neural network framework with an additional atrous parallax-attention modules. Experiment results on laparoscopic images demonstrate that the proposed framework outperforms current SR methods on both quantitative and qualitative evaluations. Our DCSSRnet provides a promising solution on enhancing spatial resolution of stereo image pairs, which will be extremely beneficial for the endoscopic surgery.
End-To-End Graph-based Deep Semi-Supervised Learning
Feb 23, 2020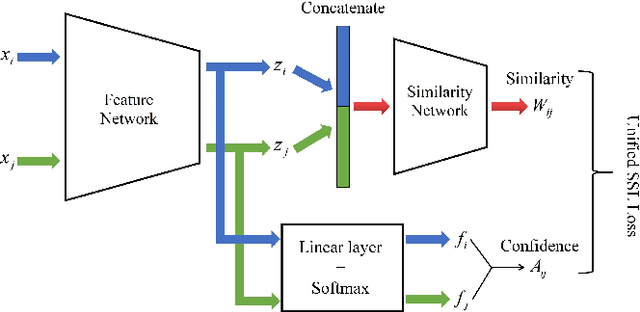
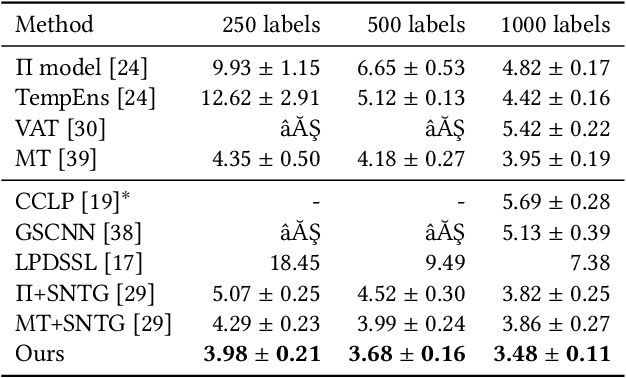


The quality of a graph is determined jointly by three key factors of the graph: nodes, edges and similarity measure (or edge weights), and is very crucial to the success of graph-based semi-supervised learning (SSL) approaches. Recently, dynamic graph, which means part/all its factors are dynamically updated during the training process, has demonstrated to be promising for graph-based semi-supervised learning. However, existing approaches only update part of the three factors and keep the rest manually specified during the learning stage. In this paper, we propose a novel graph-based semi-supervised learning approach to optimize all three factors simultaneously in an end-to-end learning fashion. To this end, we concatenate two neural networks (feature network and similarity network) together to learn the categorical label and semantic similarity, respectively, and train the networks to minimize a unified SSL objective function. We also introduce an extended graph Laplacian regularization term to increase training efficiency. Extensive experiments on several benchmark datasets demonstrate the effectiveness of our approach.
Modeling Historical AIS Data For Vessel Path Prediction: A Comprehensive Treatment
Jan 02, 2020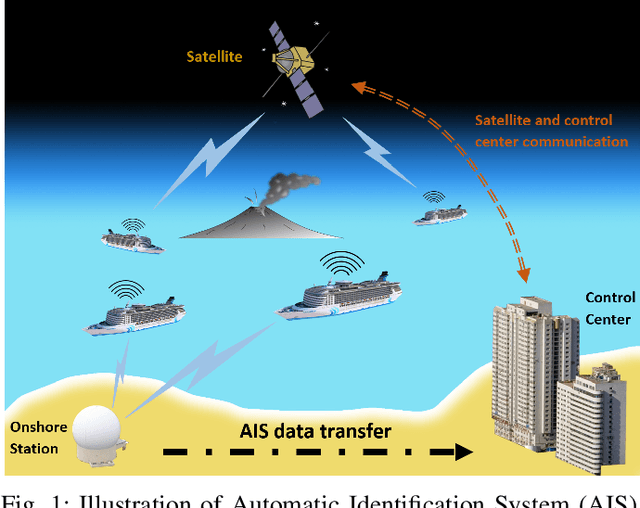
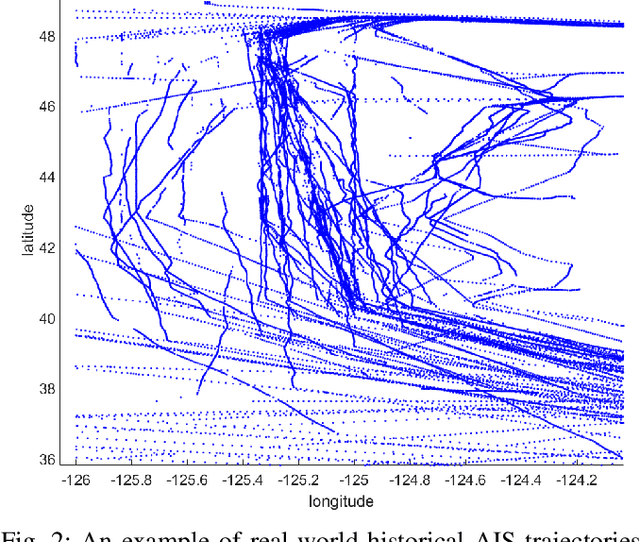
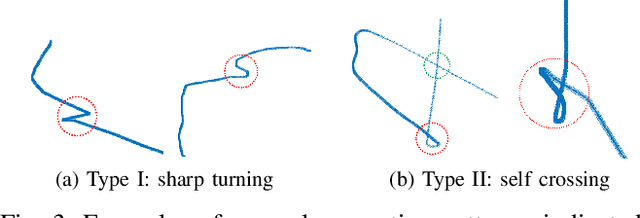
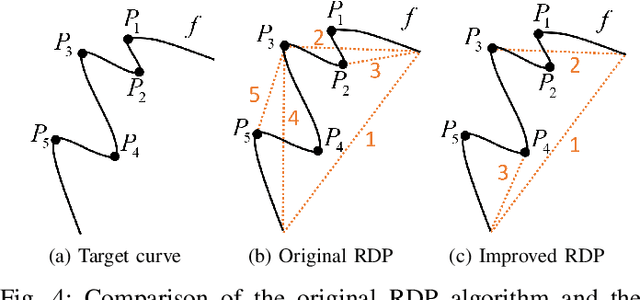
The prosperity of artificial intelligence has aroused intensive interests in intelligent/autonomous navigation, in which path prediction is a key functionality for decision supports, e.g. route planning, collision warning, and traffic regulation. For maritime intelligence, Automatic Identification System (AIS) plays an important role because it recently has been made compulsory for large international commercial vessels and is able to provide nearly real-time information of the vessel. Therefore AIS data based vessel path prediction is a promising way in future maritime intelligence. However, real-world AIS data collected online are just highly irregular trajectory segments (AIS message sequences) from different types of vessels and geographical regions, with possibly very low data quality. So even there are some works studying how to build a path prediction model using historical AIS data, but still, it is a very challenging problem. In this paper, we propose a comprehensive framework to model massive historical AIS trajectory segments for accurate vessel path prediction. Experimental comparisons with existing popular methods are made to validate the proposed approach and results show that our approach could outperform the baseline methods by a wide margin.
Semi-Supervised Deep Learning Using Improved Unsupervised Discriminant Projection
Dec 19, 2019
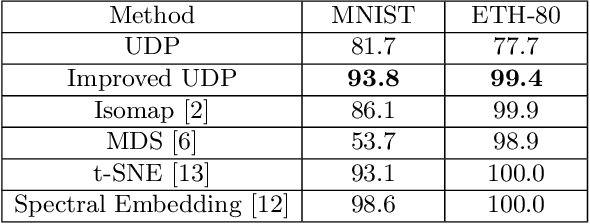
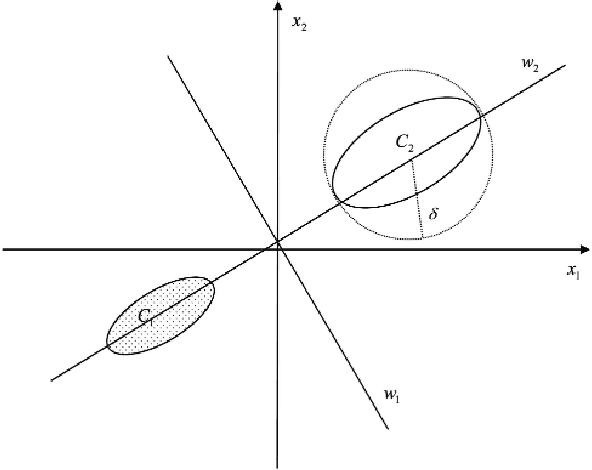
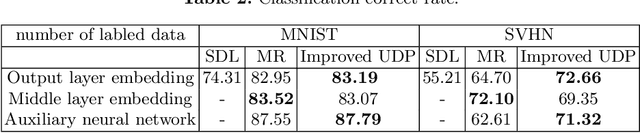
Deep learning demands a huge amount of well-labeled data to train the network parameters. How to use the least amount of labeled data to obtain the desired classification accuracy is of great practical significance, because for many real-world applications (such as medical diagnosis), it is difficult to obtain so many labeled samples. In this paper, modify the unsupervised discriminant projection algorithm from dimension reduction and apply it as a regularization term to propose a new semi-supervised deep learning algorithm, which is able to utilize both the local and nonlocal distribution of abundant unlabeled samples to improve classification performance. Experiments show that given dozens of labeled samples, the proposed algorithm can train a deep network to attain satisfactory classification results.
A Review of Semi Supervised Learning Theories and Recent Advances
May 28, 2019

Semi-supervised learning, which has emerged from the beginning of this century, is a new type of learning method between traditional supervised learning and unsupervised learning. The main idea of semi-supervised learning is to introduce unlabeled samples into the model training process to avoid performance (or model) degeneration due to insufficiency of labeled samples. Semi-supervised learning has been applied successfully in many fields. This paper reviews the development process and main theories of semi-supervised learning, as well as its recent advances and importance in solving real-world problems demonstrated by typical application examples.
A Theoretical Study of The Relationship Between Whole An ELM Network and Its Subnetworks
Oct 30, 2016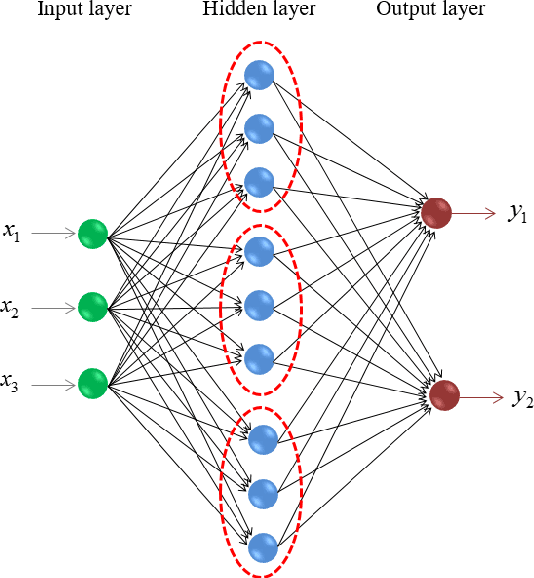
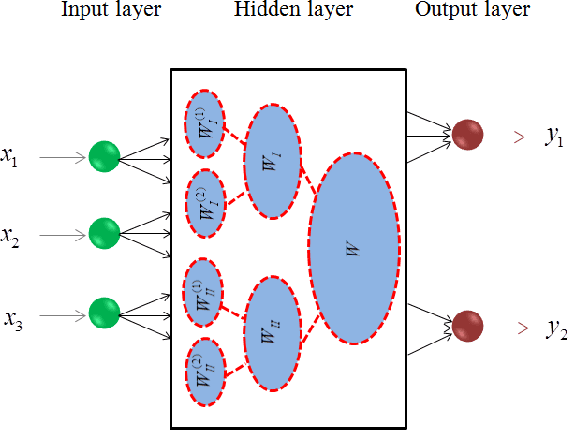
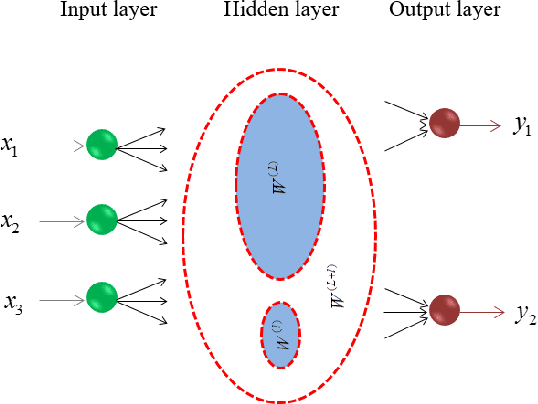
A biological neural network is constituted by numerous subnetworks and modules with different functionalities. For an artificial neural network, the relationship between a network and its subnetworks is also important and useful for both theoretical and algorithmic research, i.e. it can be exploited to develop incremental network training algorithm or parallel network training algorithm. In this paper we explore the relationship between an ELM neural network and its subnetworks. To the best of our knowledge, we are the first to prove a theorem that shows an ELM neural network can be scattered into subnetworks and its optimal solution can be constructed recursively by the optimal solutions of these subnetworks. Based on the theorem we also present two algorithms to train a large ELM neural network efficiently: one is a parallel network training algorithm and the other is an incremental network training algorithm. The experimental results demonstrate the usefulness of the theorem and the validity of the developed algorithms.
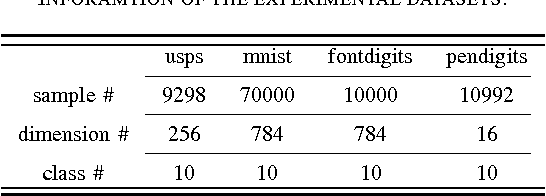
A Graph-Based Semi-Supervised k Nearest-Neighbor Method for Nonlinear Manifold Distributed Data Classification
Jun 03, 2016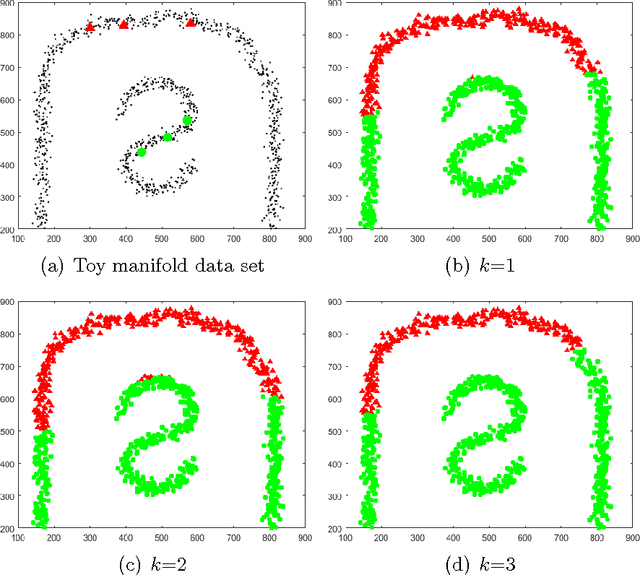
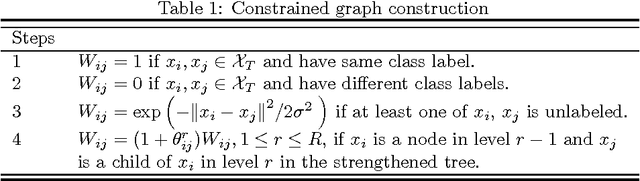
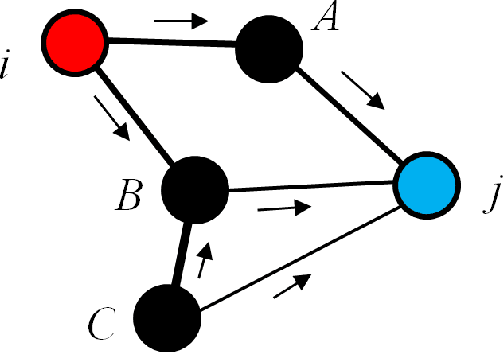

$k$ Nearest Neighbors ($k$NN) is one of the most widely used supervised learning algorithms to classify Gaussian distributed data, but it does not achieve good results when it is applied to nonlinear manifold distributed data, especially when a very limited amount of labeled samples are available. In this paper, we propose a new graph-based $k$NN algorithm which can effectively handle both Gaussian distributed data and nonlinear manifold distributed data. To achieve this goal, we first propose a constrained Tired Random Walk (TRW) by constructing an $R$-level nearest-neighbor strengthened tree over the graph, and then compute a TRW matrix for similarity measurement purposes. After this, the nearest neighbors are identified according to the TRW matrix and the class label of a query point is determined by the sum of all the TRW weights of its nearest neighbors. To deal with online situations, we also propose a new algorithm to handle sequential samples based a local neighborhood reconstruction. Comparison experiments are conducted on both synthetic data sets and real-world data sets to demonstrate the validity of the proposed new $k$NN algorithm and its improvements to other version of $k$NN algorithms. Given the widespread appearance of manifold structures in real-world problems and the popularity of the traditional $k$NN algorithm, the proposed manifold version $k$NN shows promising potential for classifying manifold-distributed data.
Mapping Temporal Variables into the NeuCube for Improved Pattern Recognition, Predictive Modelling and Understanding of Stream Data
Mar 17, 2016
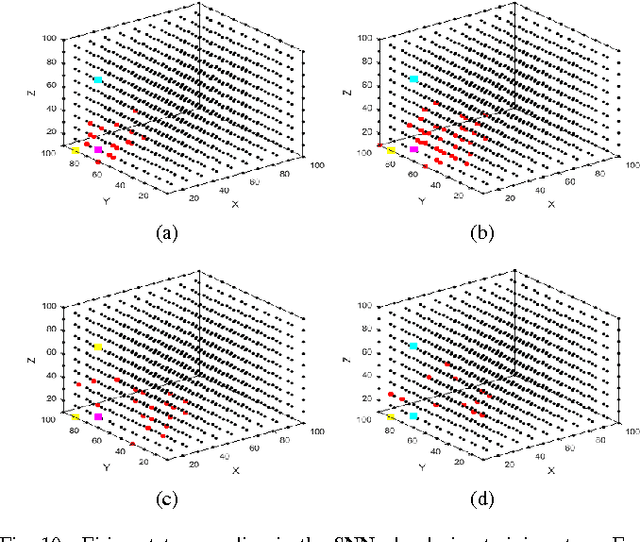
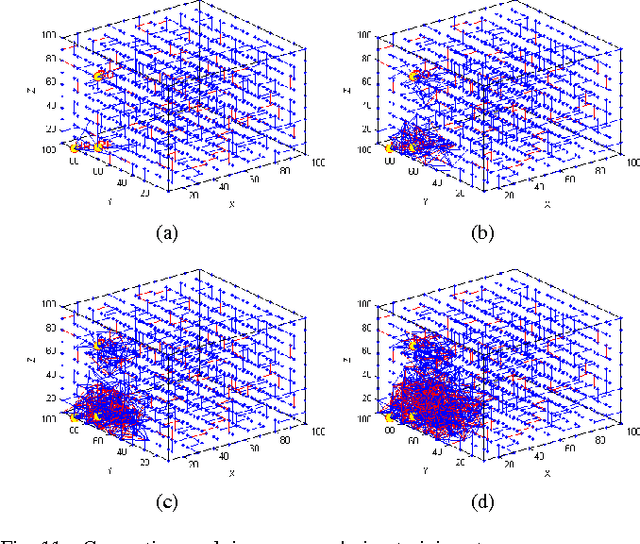
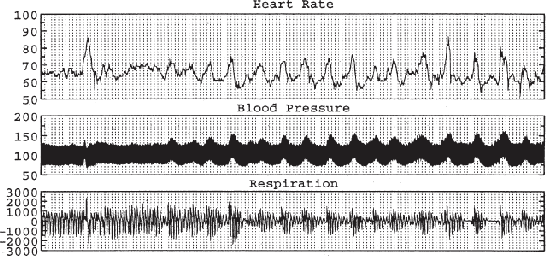
This paper proposes a new method for an optimized mapping of temporal variables, describing a temporal stream data, into the recently proposed NeuCube spiking neural network architecture. This optimized mapping extends the use of the NeuCube, which was initially designed for spatiotemporal brain data, to work on arbitrary stream data and to achieve a better accuracy of temporal pattern recognition, a better and earlier event prediction and a better understanding of complex temporal stream data through visualization of the NeuCube connectivity. The effect of the new mapping is demonstrated on three bench mark problems. The first one is early prediction of patient sleep stage event from temporal physiological data. The second one is pattern recognition of dynamic temporal patterns of traffic in the Bay Area of California and the last one is the Challenge 2012 contest data set. In all cases the use of the proposed mapping leads to an improved accuracy of pattern recognition and event prediction and a better understanding of the data when compared to traditional machine learning techniques or spiking neural network reservoirs with arbitrary mapping of the variables.