 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Historical AIS Data For Vessel Path Prediction: A Comprehensive Treatment
Jan 02, 2020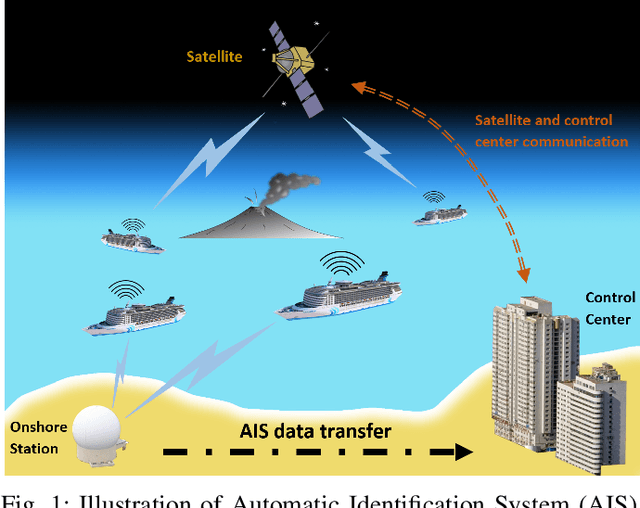
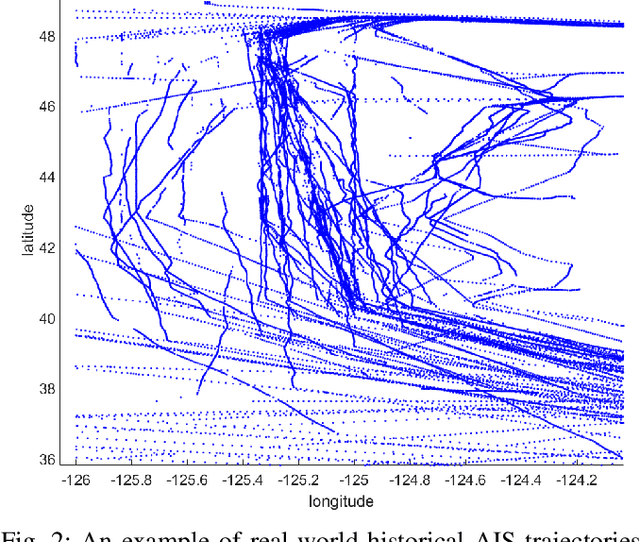
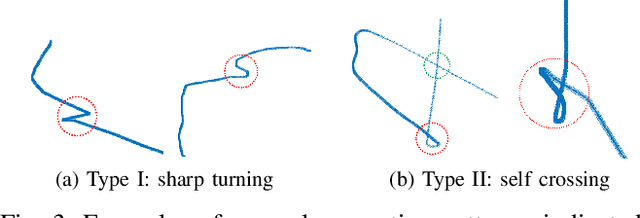
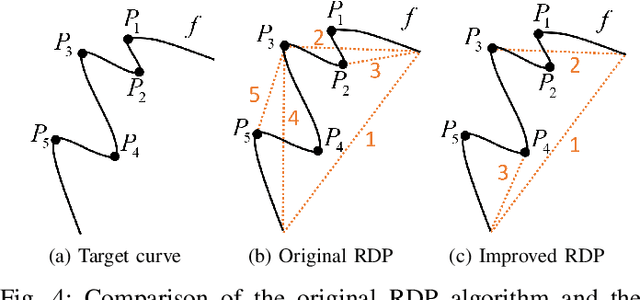
The prosperity of artificial intelligence has aroused intensive interests in intelligent/autonomous navigation, in which path prediction is a key functionality for decision supports, e.g. route planning, collision warning, and traffic regulation. For maritime intelligence, Automatic Identification System (AIS) plays an important role because it recently has been made compulsory for large international commercial vessels and is able to provide nearly real-time information of the vessel. Therefore AIS data based vessel path prediction is a promising way in future maritime intelligence. However, real-world AIS data collected online are just highly irregular trajectory segments (AIS message sequences) from different types of vessels and geographical regions, with possibly very low data quality. So even there are some works studying how to build a path prediction model using historical AIS data, but still, it is a very challenging problem. In this paper, we propose a comprehensive framework to model massive historical AIS trajectory segments for accurate vessel path prediction. Experimental comparisons with existing popular methods are made to validate the proposed approach and results show that our approach could outperform the baseline methods by a wide margin.
A Theoretical Study of The Relationship Between Whole An ELM Network and Its Subnetworks
Oct 30, 2016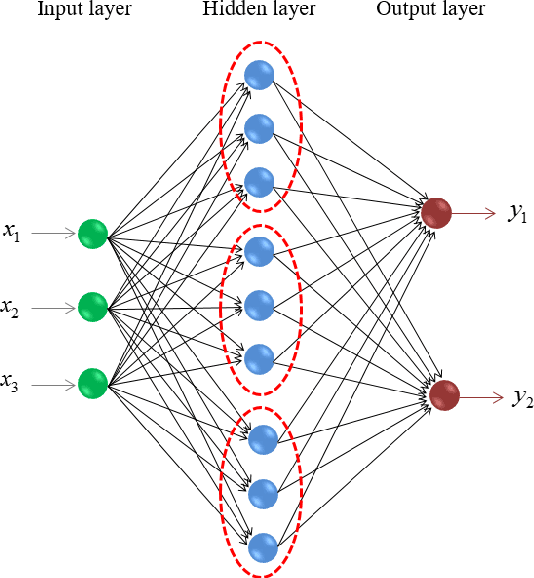
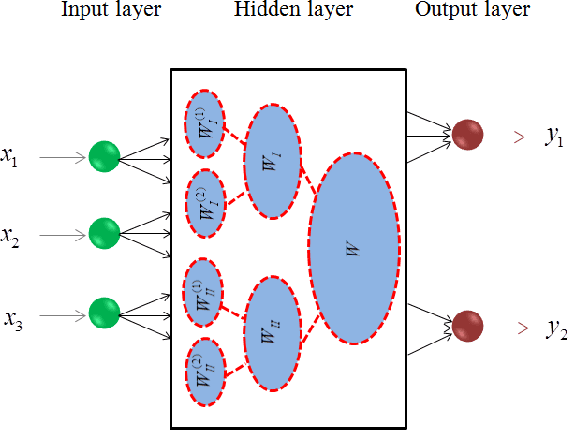
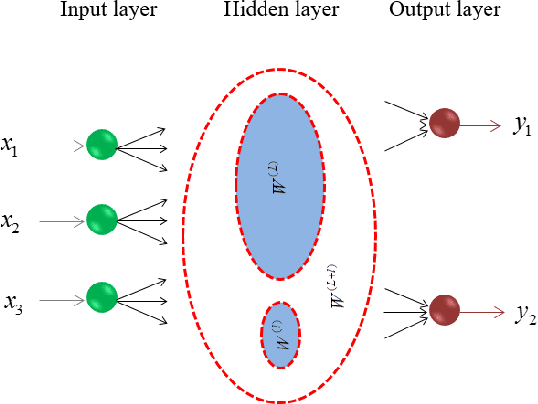
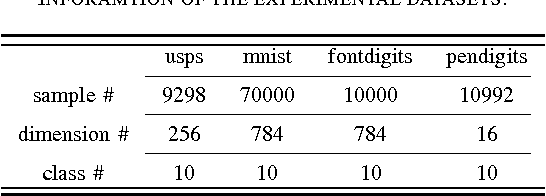
A biological neural network is constituted by numerous subnetworks and modules with different functionalities. For an artificial neural network, the relationship between a network and its subnetworks is also important and useful for both theoretical and algorithmic research, i.e. it can be exploited to develop incremental network training algorithm or parallel network training algorithm. In this paper we explore the relationship between an ELM neural network and its subnetworks. To the best of our knowledge, we are the first to prove a theorem that shows an ELM neural network can be scattered into subnetworks and its optimal solution can be constructed recursively by the optimal solutions of these subnetworks. Based on the theorem we also present two algorithms to train a large ELM neural network efficiently: one is a parallel network training algorithm and the other is an incremental network training algorithm. The experimental results demonstrate the usefulness of the theorem and the validity of the developed algorithms.