 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence without Restriction Surpassing Human Intelligence with Probability One: Theoretical Insight into Secrets of the Brain with AI Twins of the Brain
Dec 04, 2024



Artificial Intelligence (AI) has apparently become one of the most important techniques discovered by humans in history while the human brain is widely recognized as one of the most complex systems in the universe. One fundamental critical question which would affect human sustainability remains open: Will artificial intelligence (AI) evolve to surpass human intelligence in the future? This paper shows that in theory new AI twins with fresh cellular level of AI techniques for neuroscience could approximate the brain and its functioning systems (e.g. perception and cognition functions) with any expected small error and AI without restrictions could surpass human intelligence with probability one in the end. This paper indirectly proves the validity of the conjecture made by Frank Rosenblatt 70 years ago about the potential capabilities of AI, especially in the realm of artificial neural networks. Intelligence is just one of fortuitous but sophisticated creations of the nature which has not been fully discovered. Like mathematics and physics, with no restrictions artificial intelligence would lead to a new subject with its self-contained systems and principles. We anticipate that this paper opens new doors for 1) AI twins and other AI techniques to be used in cellular level of efficient neuroscience dynamic analysis, functioning analysis of the brain and brain illness solutions; 2) new worldwide collaborative scheme for interdisciplinary teams concurrently working on and modelling different types of neurons and synapses and different level of functioning subsystems of the brain with AI techniques; 3) development of low energy of AI techniques with the aid of fundamental neuroscience properties; and 4) new controllable, explainable and safe AI techniques with reasoning capabilities of discovering principles in nature.
DocBinFormer: A Two-Level Transformer Network for Effective Document Image Binarization
Dec 06, 2023



In real life, various degradation scenarios exist that might damage document images, making it harder to recognize and analyze them, thus binarization is a fundamental and crucial step for achieving the most optimal performance in any document analysis task. We propose DocBinFormer (Document Binarization Transformer), a novel two-level vision transformer (TL-ViT) architecture based on vision transformers for effective document image binarization. The presented architecture employs a two-level transformer encoder to effectively capture both global and local feature representation from the input images. These complimentary bi-level features are exploited for efficient document image binarization, resulting in improved results for system-generated as well as handwritten document images in a comprehensive approach. With the absence of convolutional layers, the transformer encoder uses the pixel patches and sub-patches along with their positional information to operate directly on them, while the decoder generates a clean (binarized) output image from the latent representation of the patches. Instead of using a simple vision transformer block to extract information from the image patches, the proposed architecture uses two transformer blocks for greater coverage of the extracted feature space on a global and local scale. The encoded feature representation is used by the decoder block to generate the corresponding binarized output. Extensive experiments on a variety of DIBCO and H-DIBCO benchmarks show that the proposed model outperforms state-of-the-art techniques on four metrics. The source code will be made available at https://github.com/RisabBiswas/DocBinFormer.
DeeptDCS: Deep Learning-Based Estimation of Currents Induced During Transcranial Direct Current Stimulation
May 04, 2022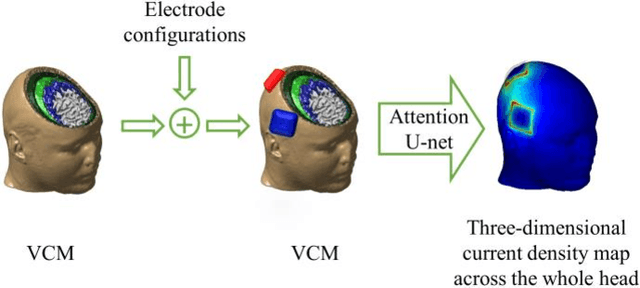
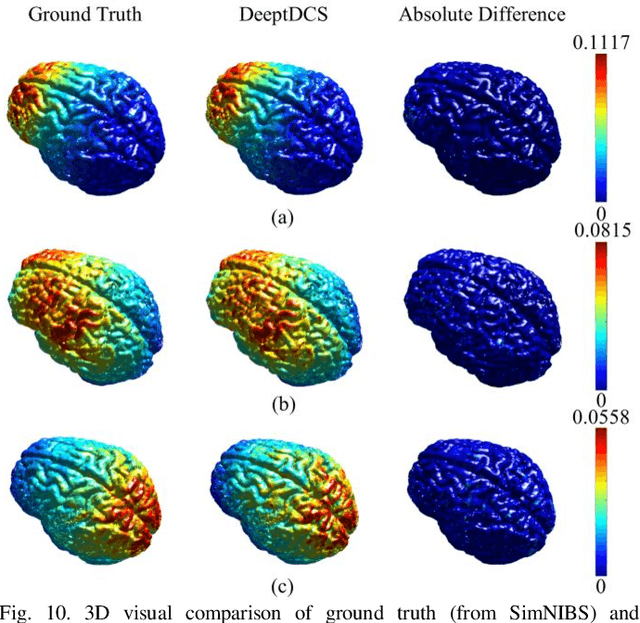
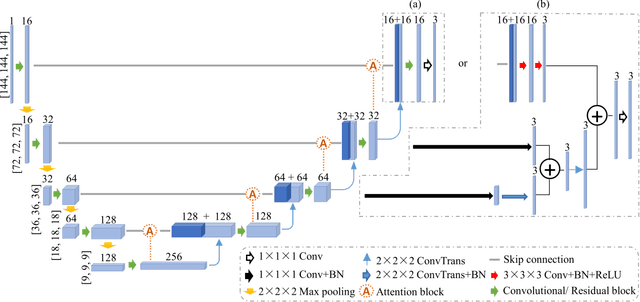
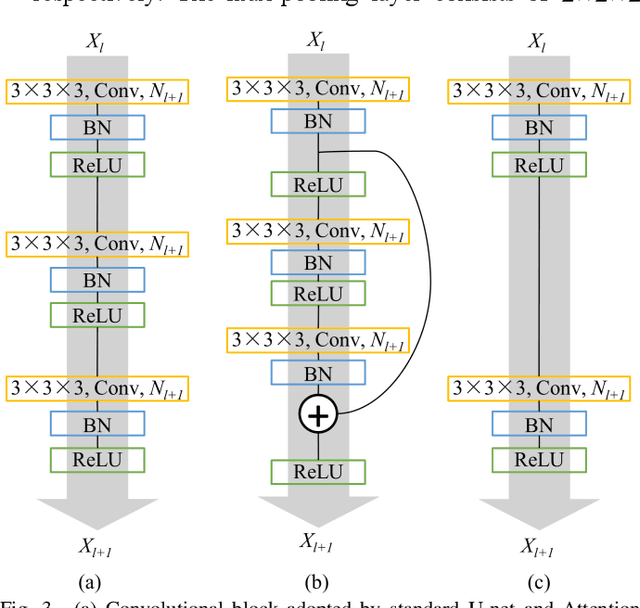
Objective: Transcranial direct current stimulation (tDCS) is a non-invasive brain stimulation technique used to generate conduction currents in the head and disrupt brain functions. To rapidly evaluate the tDCS-induced current density in near real-time, this paper proposes a deep learning-based emulator, named DeeptDCS. Methods: The emulator leverages Attention U-net taking the volume conductor models (VCMs) of head tissues as inputs and outputting the three-dimensional current density distribution across the entire head. The electrode configurations are also incorporated into VCMs without increasing the number of input channels; this enables the straightforward incorporation of the non-parametric features of electrodes (e.g., thickness, shape, size, and position) in the training and testing of the proposed emulator. Results: Attention U-net outperforms standard U-net and its other three variants (Residual U-net, Attention Residual U-net, and Multi-scale Residual U-net) in terms of accuracy. The generalization ability of DeeptDCS to non-trained electrode positions can be greatly enhanced through fine-tuning the model. The computational time required by one emulation via DeeptDCS is a fraction of a second. Conclusion: DeeptDCS is at least two orders of magnitudes faster than a physics-based open-source simulator, while providing satisfactorily accurate results. Significance: The high computational efficiency permits the use of DeeptDCS in applications requiring its repetitive execution, such as uncertainty quantification and optimization studies of tDCS.
Modeling Historical AIS Data For Vessel Path Prediction: A Comprehensive Treatment
Jan 02, 2020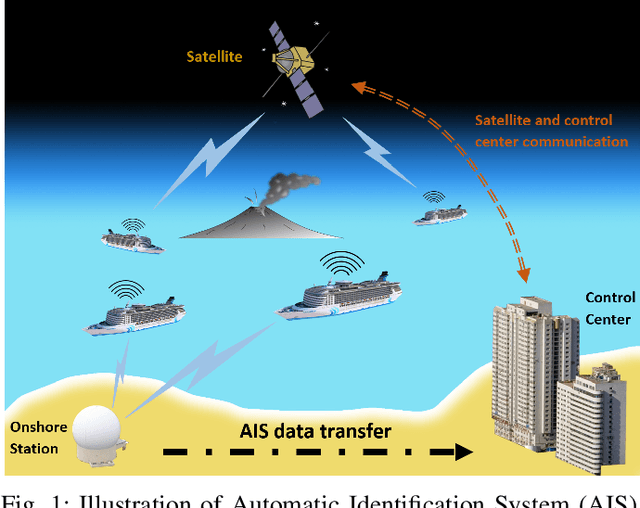
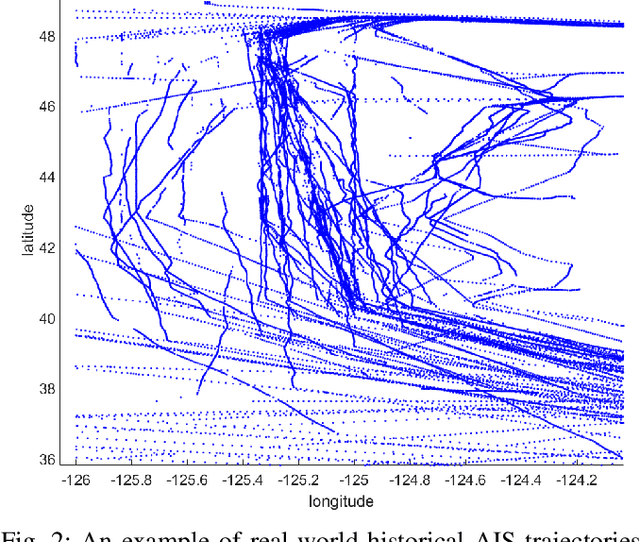
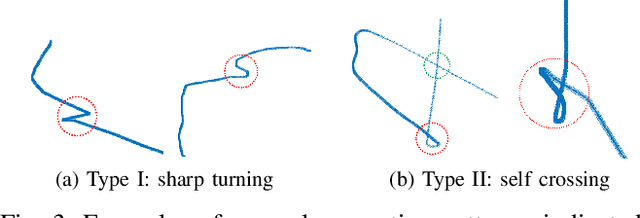
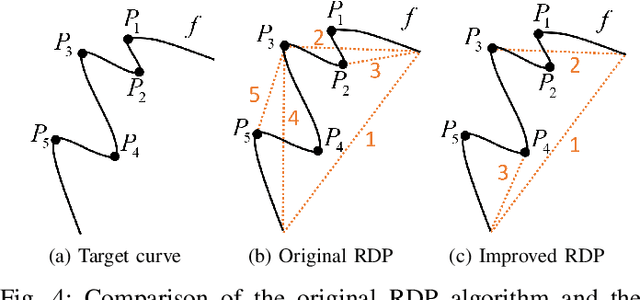
The prosperity of artificial intelligence has aroused intensive interests in intelligent/autonomous navigation, in which path prediction is a key functionality for decision supports, e.g. route planning, collision warning, and traffic regulation. For maritime intelligence, Automatic Identification System (AIS) plays an important role because it recently has been made compulsory for large international commercial vessels and is able to provide nearly real-time information of the vessel. Therefore AIS data based vessel path prediction is a promising way in future maritime intelligence. However, real-world AIS data collected online are just highly irregular trajectory segments (AIS message sequences) from different types of vessels and geographical regions, with possibly very low data quality. So even there are some works studying how to build a path prediction model using historical AIS data, but still, it is a very challenging problem. In this paper, we propose a comprehensive framework to model massive historical AIS trajectory segments for accurate vessel path prediction. Experimental comparisons with existing popular methods are made to validate the proposed approach and results show that our approach could outperform the baseline methods by a wide margin.
Manifold Criterion Guided Transfer Learning via Intermediate Domain Generation
Mar 25, 2019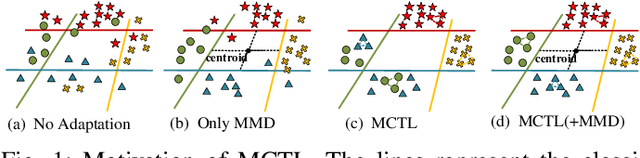
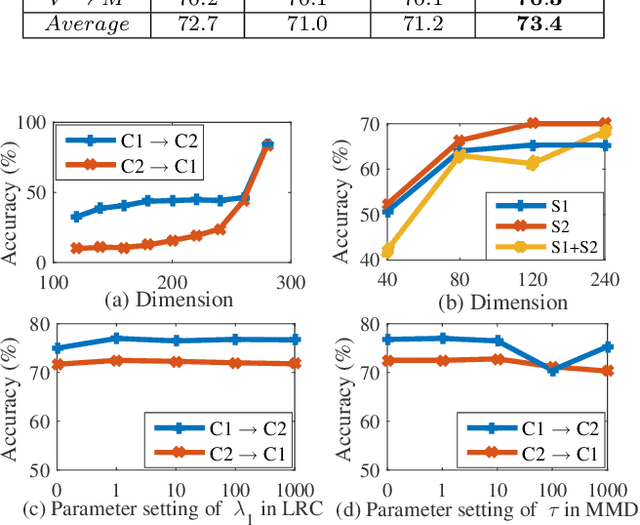
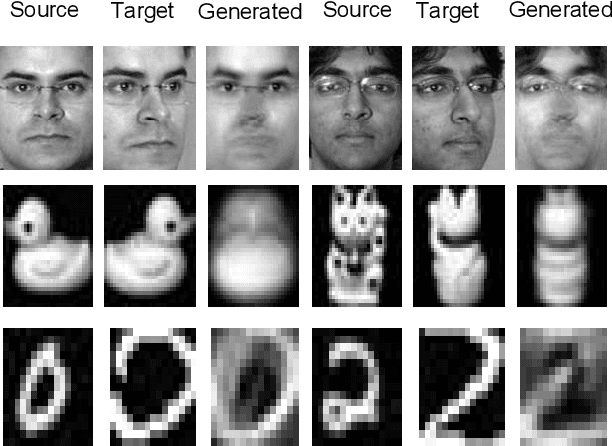
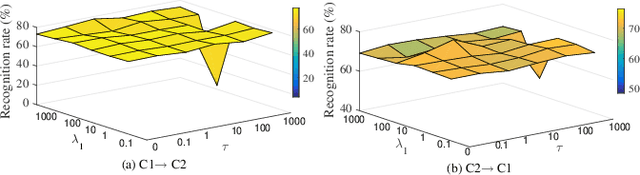
In many practical transfer learning scenarios, the feature distribution is different across the source and target domains (i.e. non-i.i.d.). Maximum mean discrepancy (MMD), as a domain discrepancy metric, has achieved promising performance in unsupervised domain adaptation (DA). We argue that MMD-based DA methods ignore the data locality structure, which, to some extent, would cause the negative transfer effect. The locality plays an important role in minimizing the nonlinear local domain discrepancy underlying the marginal distributions. For better exploiting the domain locality, a novel local generative discrepancy metric (LGDM) based intermediate domain generation learning called Manifold Criterion guided Transfer Learning (MCTL) is proposed in this paper. The merits of the proposed MCTL are four-fold: 1) the concept of manifold criterion (MC) is first proposed as a measure validating the distribution matching across domains, and domain adaptation is achieved if the MC is satisfied; 2) the proposed MC can well guide the generation of the intermediate domain sharing similar distribution with the target domain, by minimizing the local domain discrepancy; 3) a global generative discrepancy metric (GGDM) is presented, such that both the global and local discrepancy can be effectively and positively reduced; 4) a simplified version of MCTL called MCTL-S is presented under a perfect domain generation assumption for more generic learning scenario. Experiments on a number of benchmark visual transfer tasks demonstrate the superiority of the proposed manifold criterion guided generative transfer method, by comparing with other state-of-the-art methods. The source code is available in https://github.com/wangshanshanCQU/MCTL.
A Theoretical Study of The Relationship Between Whole An ELM Network and Its Subnetworks
Oct 30, 2016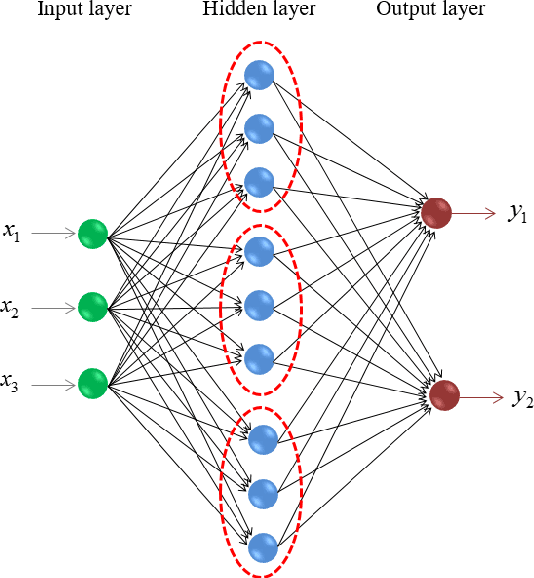
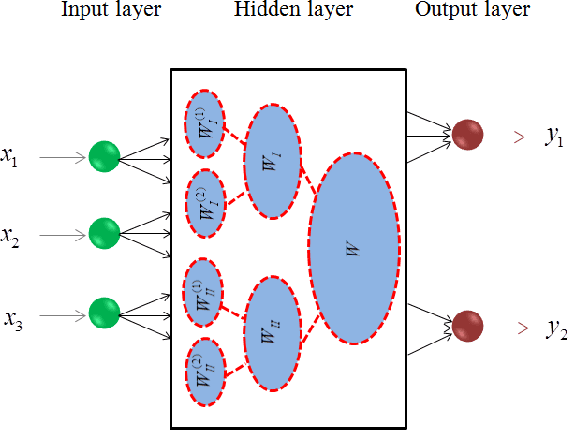
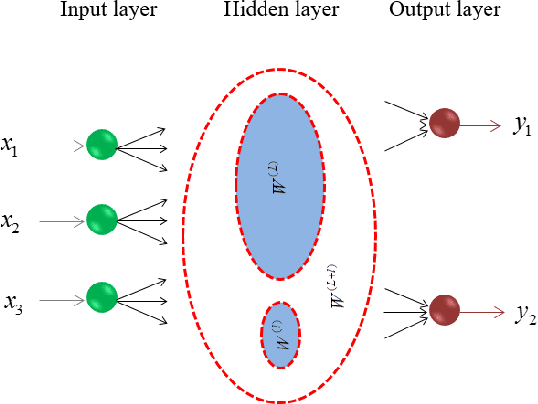
A biological neural network is constituted by numerous subnetworks and modules with different functionalities. For an artificial neural network, the relationship between a network and its subnetworks is also important and useful for both theoretical and algorithmic research, i.e. it can be exploited to develop incremental network training algorithm or parallel network training algorithm. In this paper we explore the relationship between an ELM neural network and its subnetworks. To the best of our knowledge, we are the first to prove a theorem that shows an ELM neural network can be scattered into subnetworks and its optimal solution can be constructed recursively by the optimal solutions of these subnetworks. Based on the theorem we also present two algorithms to train a large ELM neural network efficiently: one is a parallel network training algorithm and the other is an incremental network training algorithm. The experimental results demonstrate the usefulness of the theorem and the validity of the developed algorithms.