 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Deep Learning Using Improved Unsupervised Discriminant Projection
Paper and Code

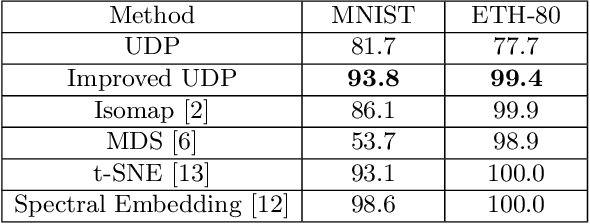
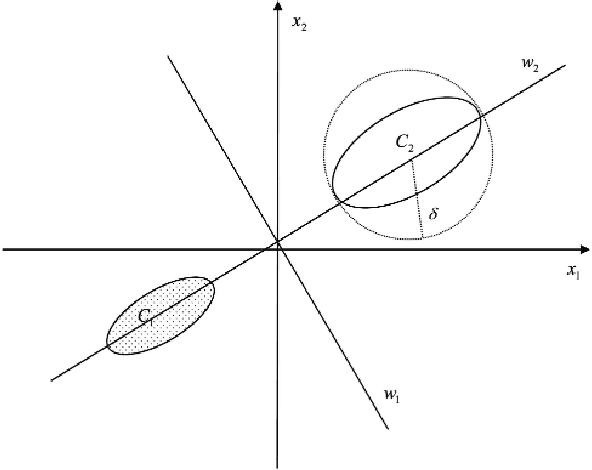
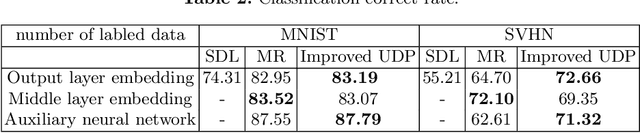
Deep learning demands a huge amount of well-labeled data to train the network parameters. How to use the least amount of labeled data to obtain the desired classification accuracy is of great practical significance, because for many real-world applications (such as medical diagnosis), it is difficult to obtain so many labeled samples. In this paper, modify the unsupervised discriminant projection algorithm from dimension reduction and apply it as a regularization term to propose a new semi-supervised deep learning algorithm, which is able to utilize both the local and nonlocal distribution of abundant unlabeled samples to improve classification performance. Experiments show that given dozens of labeled samples, the proposed algorithm can train a deep network to attain satisfactory classification results.