 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast-Slow Thinking for Large Vision-Language Model Reasoning
Apr 25, 2025Recent advances in large vision-language models (LVLMs) have revealed an \textit{overthinking} phenomenon, where models generate verbose reasoning across all tasks regardless of questions. To address this issue, we present \textbf{FAST}, a novel \textbf{Fa}st-\textbf{S}low \textbf{T}hinking framework that dynamically adapts reasoning depth based on question characteristics. Through empirical analysis, we establish the feasibility of fast-slow thinking in LVLMs by investigating how response length and data distribution affect performance. We develop FAST-GRPO with three components: model-based metrics for question characterization, an adaptive thinking reward mechanism, and difficulty-aware KL regularization. Experiments across seven reasoning benchmarks demonstrate that FAST achieves state-of-the-art accuracy with over 10\% relative improvement compared to the base model, while reducing token usage by 32.7-67.3\% compared to previous slow-thinking approaches, effectively balancing reasoning length and accuracy.
CMMCoT: Enhancing Complex Multi-Image Comprehension via Multi-Modal Chain-of-Thought and Memory Augmentation
Mar 07, 2025



While previous multimodal slow-thinking methods have demonstrated remarkable success in single-image understanding scenarios, their effectiveness becomes fundamentally constrained when extended to more complex multi-image comprehension tasks. This limitation stems from their predominant reliance on text-based intermediate reasoning processes. While for human, when engaging in sophisticated multi-image analysis, they typically perform two complementary cognitive operations: (1) continuous cross-image visual comparison through region-of-interest matching, and (2) dynamic memorization of critical visual concepts throughout the reasoning chain. Motivated by these observations, we propose the Complex Multi-Modal Chain-of-Thought (CMMCoT) framework, a multi-step reasoning framework that mimics human-like "slow thinking" for multi-image understanding. Our approach incorporates two key innovations: 1. The construction of interleaved multimodal multi-step reasoning chains, which utilize critical visual region tokens, extracted from intermediate reasoning steps, as supervisory signals. This mechanism not only facilitates comprehensive cross-modal understanding but also enhances model interpretability. 2. The introduction of a test-time memory augmentation module that expands the model reasoning capacity during inference while preserving parameter efficiency. Furthermore, to facilitate research in this direction, we have curated a novel multi-image slow-thinking dataset. Extensive experiments demonstrate the effectiveness of our model.
MINT: Multi-modal Chain of Thought in Unified Generative Models for Enhanced Image Generation
Mar 03, 2025Unified generative models have demonstrated extraordinary performance in both text and image generation. However, they tend to underperform when generating intricate images with various interwoven conditions, which is hard to solely rely on straightforward text-to-image generation. In response to this challenge, we introduce MINT, an innovative unified generative model, empowered with native multimodal chain of thought (MCoT) for enhanced image generation for the first time. Firstly, we design Mixture of Transformer Experts (MTXpert), an expert-parallel structure that effectively supports both natural language generation (NLG) and visual capabilities, while avoiding potential modality conflicts that could hinder the full potential of each modality. Building on this, we propose an innovative MCoT training paradigm, a step-by-step approach to multimodal thinking, reasoning, and reflection specifically designed to enhance image generation. This paradigm equips MINT with nuanced, element-wise decoupled alignment and a comprehensive understanding of textual and visual components. Furthermore, it fosters advanced multimodal reasoning and self-reflection, enabling the construction of images that are firmly grounded in the logical relationships between these elements. Notably, MINT has been validated to exhibit superior performance across multiple benchmarks for text-to-image (T2I) and image-to-text (I2T) tasks.
Boosting Private Domain Understanding of Efficient MLLMs: A Tuning-free, Adaptive, Universal Prompt Optimization Framework
Dec 27, 2024Efficient multimodal large language models (EMLLMs), in contrast to multimodal large language models (MLLMs), reduce model size and computational costs and are often deployed on resource-constrained devices. However, due to data privacy concerns, existing open-source EMLLMs rarely have access to private domain-specific data during the pre-training process, making them difficult to directly apply in device-specific domains, such as certain business scenarios. To address this weakness, this paper focuses on the efficient adaptation of EMLLMs to private domains, specifically in two areas: 1) how to reduce data requirements, and 2) how to avoid parameter fine-tuning. Specifically, we propose a tun\textbf{\underline{I}}ng-free, a\textbf{\underline{D}}aptiv\textbf{\underline{E}}, univers\textbf{\underline{AL}} \textbf{\underline{Prompt}} Optimization Framework, abbreviated as \textit{\textbf{\ourmethod{}}} which consists of two stages: 1) Predefined Prompt, based on the reinforcement searching strategy, generate a prompt optimization strategy tree to acquire optimization priors; 2) Prompt Reflection initializes the prompt based on optimization priors, followed by self-reflection to further search and refine the prompt. By doing so, \ourmethod{} elegantly generates the ``ideal prompts'' for processing private domain-specific data. Note that our method requires no parameter fine-tuning and only a small amount of data to quickly adapt to the data distribution of private data. Extensive experiments across multiple tasks demonstrate that our proposed \ourmethod{} significantly improves both efficiency and performance compared to baselines.
T2I-FactualBench: Benchmarking the Factuality of Text-to-Image Models with Knowledge-Intensive Concepts
Dec 05, 2024



Evaluating the quality of synthesized images remains a significant challenge in the development of text-to-image (T2I) generation. Most existing studies in this area primarily focus on evaluating text-image alignment, image quality, and object composition capabilities, with comparatively fewer studies addressing the evaluation of the factuality of T2I models, particularly when the concepts involved are knowledge-intensive. To mitigate this gap, we present T2I-FactualBench in this work - the largest benchmark to date in terms of the number of concepts and prompts specifically designed to evaluate the factuality of knowledge-intensive concept generation. T2I-FactualBench consists of a three-tiered knowledge-intensive text-to-image generation framework, ranging from the basic memorization of individual knowledge concepts to the more complex composition of multiple knowledge concepts. We further introduce a multi-round visual question answering (VQA) based evaluation framework to assess the factuality of three-tiered knowledge-intensive text-to-image generation tasks. Experiments on T2I-FactualBench indicate that current state-of-the-art (SOTA) T2I models still leave significant room for improvement.
LLaVA-MoD: Making LLaVA Tiny via MoE Knowledge Distillation
Aug 28, 2024We introduce LLaVA-MoD, a novel framework designed to enable the efficient training of small-scale Multimodal Language Models (s-MLLM) by distilling knowledge from large-scale MLLM (l-MLLM). Our approach tackles two fundamental challenges in MLLM distillation. First, we optimize the network structure of s-MLLM by integrating a sparse Mixture of Experts (MoE) architecture into the language model, striking a balance between computational efficiency and model expressiveness. Second, we propose a progressive knowledge transfer strategy to ensure comprehensive knowledge migration. This strategy begins with mimic distillation, where we minimize the Kullback-Leibler (KL) divergence between output distributions to enable the student model to emulate the teacher network's understanding. Following this, we introduce preference distillation via Direct Preference Optimization (DPO), where the key lies in treating l-MLLM as the reference model. During this phase, the s-MLLM's ability to discriminate between superior and inferior examples is significantly enhanced beyond l-MLLM, leading to a better student that surpasses its teacher, particularly in hallucination benchmarks. Extensive experiments demonstrate that LLaVA-MoD outperforms existing models across various multimodal benchmarks while maintaining a minimal number of activated parameters and low computational costs. Remarkably, LLaVA-MoD, with only 2B activated parameters, surpasses Qwen-VL-Chat-7B by an average of 8.8% across benchmarks, using merely 0.3% of the training data and 23% trainable parameters. These results underscore LLaVA-MoD's ability to effectively distill comprehensive knowledge from its teacher model, paving the way for the development of more efficient MLLMs. The code will be available on: https://github.com/shufangxun/LLaVA-MoD.
TeamLoRA: Boosting Low-Rank Adaptation with Expert Collaboration and Competition
Aug 19, 2024



While Parameter-Efficient Fine-Tuning (PEFT) methods like LoRA have effectively addressed GPU memory constraints during fine-tuning, their performance often falls short, especially in multidimensional task scenarios. To address this issue, one straightforward solution is to introduce task-specific LoRA modules as domain experts, leveraging the modeling of multiple experts' capabilities and thus enhancing the general capability of multi-task learning. Despite promising, these additional components often add complexity to the training and inference process, contravening the efficient characterization of PEFT designed for. Considering this, we introduce an innovative PEFT method, TeamLoRA, consisting of a collaboration and competition module for experts, and thus achieving the right balance of effectiveness and efficiency: (i) For collaboration, a novel knowledge-sharing and -organizing mechanism is devised to appropriately reduce the scale of matrix operations, thereby boosting the training and inference speed. (ii) For competition, we propose leveraging a game-theoretic interaction mechanism for experts, encouraging experts to transfer their domain-specific knowledge while facing diverse downstream tasks, and thus enhancing the performance. By doing so, TeamLoRA elegantly connects the experts as a "Team" with internal collaboration and competition, enabling a faster and more accurate PEFT paradigm for multi-task learning. To validate the superiority of TeamLoRA, we curate a comprehensive multi-task evaluation(CME) benchmark to thoroughly assess the capability of multi-task learning. Experiments conducted on our CME and other benchmarks indicate the effectiveness and efficiency of TeamLoRA. Our project is available at https://github.com/Lin-Tianwei/TeamLoRA.
MARS: Mixture of Auto-Regressive Models for Fine-grained Text-to-image Synthesis
Jul 11, 2024



Auto-regressive models have made significant progress in the realm of language generation, yet they do not perform on par with diffusion models in the domain of image synthesis. In this work, we introduce MARS, a novel framework for T2I generation that incorporates a specially designed Semantic Vision-Language Integration Expert (SemVIE). This innovative component integrates pre-trained LLMs by independently processing linguistic and visual information, freezing the textual component while fine-tuning the visual component. This methodology preserves the NLP capabilities of LLMs while imbuing them with exceptional visual understanding. Building upon the powerful base of the pre-trained Qwen-7B, MARS stands out with its bilingual generative capabilities corresponding to both English and Chinese language prompts and the capacity for joint image and text generation. The flexibility of this framework lends itself to migration towards any-to-any task adaptability. Furthermore, MARS employs a multi-stage training strategy that first establishes robust image-text alignment through complementary bidirectional tasks and subsequently concentrates on refining the T2I generation process, significantly augmenting text-image synchrony and the granularity of image details. Notably, MARS requires only 9% of the GPU days needed by SD1.5, yet it achieves remarkable results across a variety of benchmarks, illustrating the training efficiency and the potential for swift deployment in various applications.
Detecting and Mitigating Hallucination in Large Vision Language Models via Fine-Grained AI Feedback
Apr 22, 2024



The rapidly developing Large Vision Language Models (LVLMs) have shown notable capabilities on a range of multi-modal tasks, but still face the hallucination phenomena where the generated texts do not align with the given contexts, significantly restricting the usages of LVLMs. Most previous work detects and mitigates hallucination at the coarse-grained level or requires expensive annotation (e.g., labeling by proprietary models or human experts). To address these issues, we propose detecting and mitigating hallucinations in LVLMs via fine-grained AI feedback. The basic idea is that we generate a small-size sentence-level hallucination annotation dataset by proprietary models, whereby we train a hallucination detection model which can perform sentence-level hallucination detection, covering primary hallucination types (i.e., object, attribute, and relationship). Then, we propose a detect-then-rewrite pipeline to automatically construct preference dataset for training hallucination mitigating model. Furthermore, we propose differentiating the severity of hallucinations, and introducing a Hallucination Severity-Aware Direct Preference Optimization (HSA-DPO) for mitigating hallucination in LVLMs by incorporating the severity of hallucinations into preference learning. Extensive experiments demonstrate the effectiveness of our method.
TrainerAgent: Customizable and Efficient Model Training through LLM-Powered Multi-Agent System
Nov 23, 2023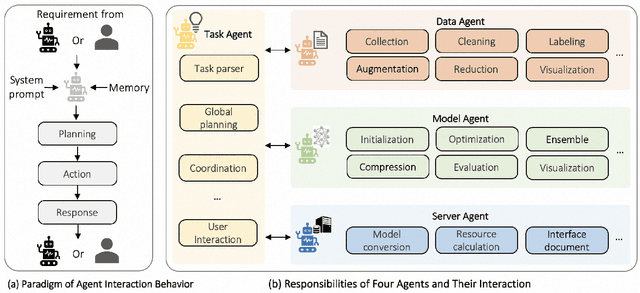
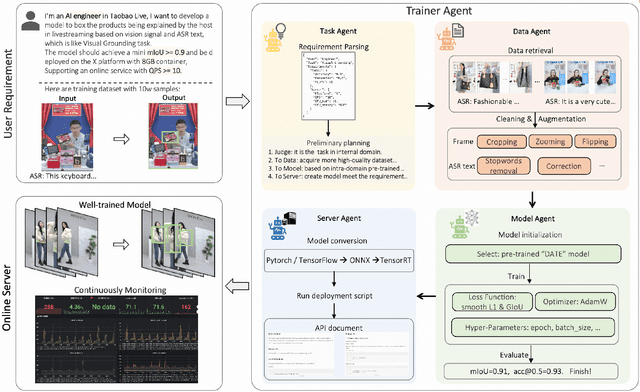
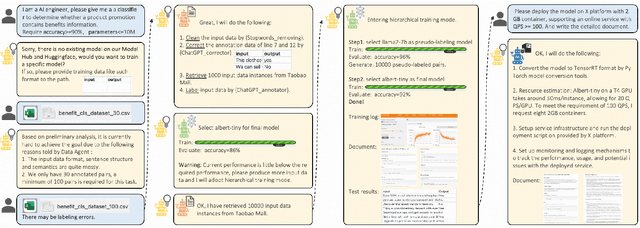
Training AI models has always been challenging, especially when there is a need for custom models to provide personalized services. Algorithm engineers often face a lengthy process to iteratively develop models tailored to specific business requirements, making it even more difficult for non-experts. The quest for high-quality and efficient model development, along with the emergence of Large Language Model (LLM) Agents, has become a key focus in the industry. Leveraging the powerful analytical, planning, and decision-making capabilities of LLM, we propose a TrainerAgent system comprising a multi-agent framework including Task, Data, Model and Server agents. These agents analyze user-defined tasks, input data, and requirements (e.g., accuracy, speed), optimizing them comprehensively from both data and model perspectives to obtain satisfactory models, and finally deploy these models as online service. Experimental evaluations on classical discriminative and generative tasks in computer vision and natural language processing domains demonstrate that our system consistently produces models that meet the desired criteria. Furthermore, the system exhibits the ability to critically identify and reject unattainable tasks, such as fantastical scenarios or unethical requests, ensuring robustness and safety. This research presents a significant advancement in achieving desired models with increased efficiency and quality as compared to traditional model development, facilitated by the integration of LLM-powered analysis, decision-making, and execution capabilities, as well as the collaboration among four agents. We anticipate that our work will contribute to the advancement of research on TrainerAgent in both academic and industry communities, potentially establishing it as a new paradigm for model development in the field of AI.