 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalker-T2AV: Joint Talking Audio-Video Generation with Autoregressive Diffusion Modeling
Apr 26, 2026Joint audio-video generation models have shown that unified generation yields stronger cross-modal coherence than cascaded approaches. However, existing models couple modalities throughout denoising via pervasive attention, treating high-level semantics and low-level details in a fully entangled manner. This is suboptimal for talking head synthesis: while audio and facial motion are semantically correlated, their low-level realizations (acoustic signals and visual textures) follow distinct rendering processes. Enforcing joint modeling across all levels causes unnecessary entanglement and reduces efficiency. We propose Talker-T2AV, an autoregressive diffusion framework where high-level cross-modal modeling occurs in a shared backbone, while low-level refinement uses modality-specific decoders. A shared autoregressive language model jointly reasons over audio and video in a unified patch-level token space. Two lightweight diffusion transformer heads decode the hidden states into frame-level audio and video latents. Experiments on talking portrait benchmarks show Talker-T2AV outperforms dual-branch baselines in lip-sync accuracy, video quality, and audio quality, achieving stronger cross-modal consistency than cascaded pipelines.
Kimi-Audio Technical Report
Apr 25, 2025



We present Kimi-Audio, an open-source audio foundation model that excels in audio understanding, generation, and conversation. We detail the practices in building Kimi-Audio, including model architecture, data curation, training recipe, inference deployment, and evaluation. Specifically, we leverage a 12.5Hz audio tokenizer, design a novel LLM-based architecture with continuous features as input and discrete tokens as output, and develop a chunk-wise streaming detokenizer based on flow matching. We curate a pre-training dataset that consists of more than 13 million hours of audio data covering a wide range of modalities including speech, sound, and music, and build a pipeline to construct high-quality and diverse post-training data. Initialized from a pre-trained LLM, Kimi-Audio is continual pre-trained on both audio and text data with several carefully designed tasks, and then fine-tuned to support a diverse of audio-related tasks. Extensive evaluation shows that Kimi-Audio achieves state-of-the-art performance on a range of audio benchmarks including speech recognition, audio understanding, audio question answering, and speech conversation. We release the codes, model checkpoints, as well as the evaluation toolkits in https://github.com/MoonshotAI/Kimi-Audio.
The Best of Both Worlds: Integrating Language Models and Diffusion Models for Video Generation
Mar 06, 2025Recent advancements in text-to-video (T2V) generation have been driven by two competing paradigms: autoregressive language models and diffusion models. However, each paradigm has intrinsic limitations: language models struggle with visual quality and error accumulation, while diffusion models lack semantic understanding and causal modeling. In this work, we propose LanDiff, a hybrid framework that synergizes the strengths of both paradigms through coarse-to-fine generation. Our architecture introduces three key innovations: (1) a semantic tokenizer that compresses 3D visual features into compact 1D discrete representations through efficient semantic compression, achieving a $\sim$14,000$\times$ compression ratio; (2) a language model that generates semantic tokens with high-level semantic relationships; (3) a streaming diffusion model that refines coarse semantics into high-fidelity videos. Experiments show that LanDiff, a 5B model, achieves a score of 85.43 on the VBench T2V benchmark, surpassing the state-of-the-art open-source models Hunyuan Video (13B) and other commercial models such as Sora, Keling, and Hailuo. Furthermore, our model also achieves state-of-the-art performance in long video generation, surpassing other open-source models in this field. Our demo can be viewed at https://landiff.github.io/.
T2S-GPT: Dynamic Vector Quantization for Autoregressive Sign Language Production from Text
Jun 11, 2024In this work, we propose a two-stage sign language production (SLP) paradigm that first encodes sign language sequences into discrete codes and then autoregressively generates sign language from text based on the learned codebook. However, existing vector quantization (VQ) methods are fixed-length encodings, overlooking the uneven information density in sign language, which leads to under-encoding of important regions and over-encoding of unimportant regions. To address this issue, we propose a novel dynamic vector quantization (DVA-VAE) model that can dynamically adjust the encoding length based on the information density in sign language to achieve accurate and compact encoding. Then, a GPT-like model learns to generate code sequences and their corresponding durations from spoken language text. Extensive experiments conducted on the PHOENIX14T dataset demonstrate the effectiveness of our proposed method. To promote sign language research, we propose a new large German sign language dataset, PHOENIX-News, which contains 486 hours of sign language videos, audio, and transcription texts.Experimental analysis on PHOENIX-News shows that the performance of our model can be further improved by increasing the size of the training data. Our project homepage is https://t2sgpt-demo.yinaoxiong.cn.
TransFace: Unit-Based Audio-Visual Speech Synthesizer for Talking Head Translation
Dec 23, 2023

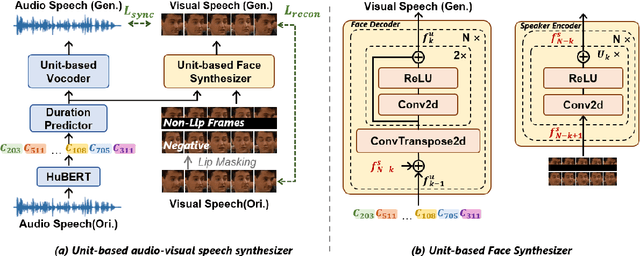
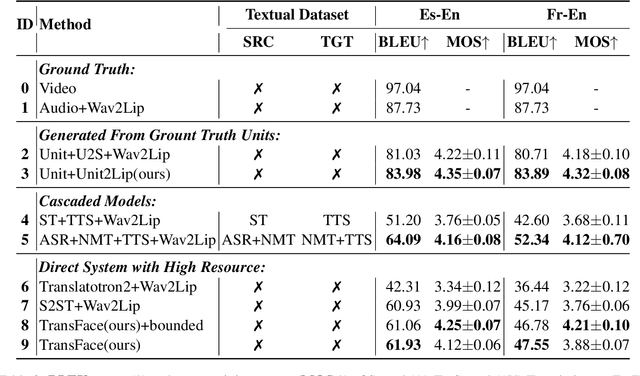
Direct speech-to-speech translation achieves high-quality results through the introduction of discrete units obtained from self-supervised learning. This approach circumvents delays and cascading errors associated with model cascading. However, talking head translation, converting audio-visual speech (i.e., talking head video) from one language into another, still confronts several challenges compared to audio speech: (1) Existing methods invariably rely on cascading, synthesizing via both audio and text, resulting in delays and cascading errors. (2) Talking head translation has a limited set of reference frames. If the generated translation exceeds the length of the original speech, the video sequence needs to be supplemented by repeating frames, leading to jarring video transitions. In this work, we propose a model for talking head translation, \textbf{TransFace}, which can directly translate audio-visual speech into audio-visual speech in other languages. It consists of a speech-to-unit translation model to convert audio speech into discrete units and a unit-based audio-visual speech synthesizer, Unit2Lip, to re-synthesize synchronized audio-visual speech from discrete units in parallel. Furthermore, we introduce a Bounded Duration Predictor, ensuring isometric talking head translation and preventing duplicate reference frames. Experiments demonstrate that our proposed Unit2Lip model significantly improves synchronization (1.601 and 0.982 on LSE-C for the original and generated audio speech, respectively) and boosts inference speed by a factor of 4.35 on LRS2. Additionally, TransFace achieves impressive BLEU scores of 61.93 and 47.55 for Es-En and Fr-En on LRS3-T and 100% isochronous translations.
Language Model is a Branch Predictor for Simultaneous Machine Translation
Dec 22, 2023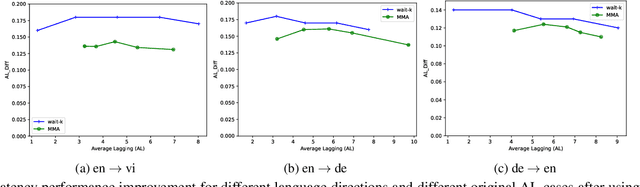

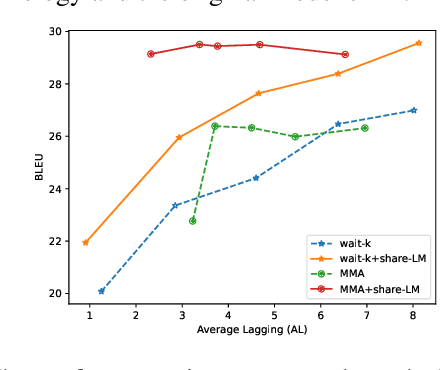

The primary objective of simultaneous machine translation (SiMT) is to minimize latency while preserving the quality of the final translation. Drawing inspiration from CPU branch prediction techniques, we propose incorporating branch prediction techniques in SiMT tasks to reduce translation latency. Specifically, we utilize a language model as a branch predictor to predict potential branch directions, namely, future source words. Subsequently, we utilize the predicted source words to decode the output in advance. When the actual source word deviates from the predicted source word, we use the real source word to decode the output again, replacing the predicted output. To further reduce computational costs, we share the parameters of the encoder and the branch predictor, and utilize a pre-trained language model for initialization. Our proposed method can be seamlessly integrated with any SiMT model. Extensive experimental results demonstrate that our approach can improve translation quality and latency at the same time. Our code is available at https://github.com/YinAoXiong/simt_branch_predictor .
TrainerAgent: Customizable and Efficient Model Training through LLM-Powered Multi-Agent System
Nov 23, 2023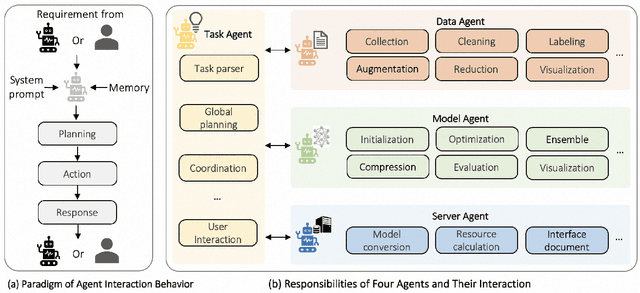
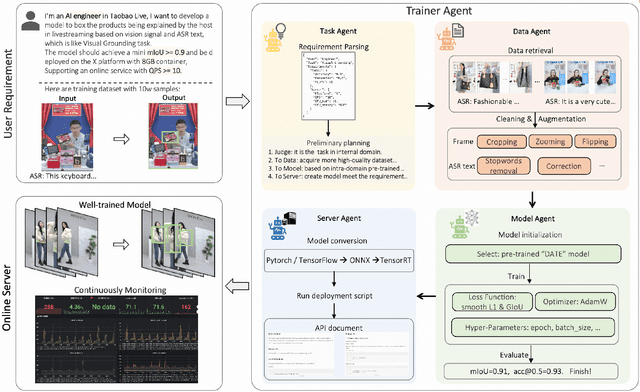
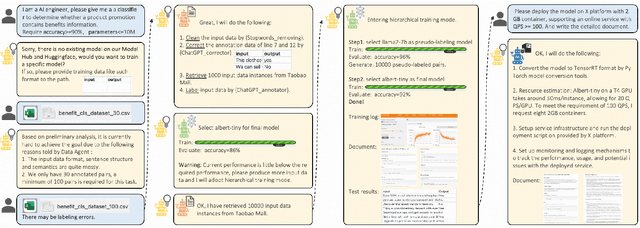
Training AI models has always been challenging, especially when there is a need for custom models to provide personalized services. Algorithm engineers often face a lengthy process to iteratively develop models tailored to specific business requirements, making it even more difficult for non-experts. The quest for high-quality and efficient model development, along with the emergence of Large Language Model (LLM) Agents, has become a key focus in the industry. Leveraging the powerful analytical, planning, and decision-making capabilities of LLM, we propose a TrainerAgent system comprising a multi-agent framework including Task, Data, Model and Server agents. These agents analyze user-defined tasks, input data, and requirements (e.g., accuracy, speed), optimizing them comprehensively from both data and model perspectives to obtain satisfactory models, and finally deploy these models as online service. Experimental evaluations on classical discriminative and generative tasks in computer vision and natural language processing domains demonstrate that our system consistently produces models that meet the desired criteria. Furthermore, the system exhibits the ability to critically identify and reject unattainable tasks, such as fantastical scenarios or unethical requests, ensuring robustness and safety. This research presents a significant advancement in achieving desired models with increased efficiency and quality as compared to traditional model development, facilitated by the integration of LLM-powered analysis, decision-making, and execution capabilities, as well as the collaboration among four agents. We anticipate that our work will contribute to the advancement of research on TrainerAgent in both academic and industry communities, potentially establishing it as a new paradigm for model development in the field of AI.
3DRP-Net: 3D Relative Position-aware Network for 3D Visual Grounding
Jul 25, 2023



3D visual grounding aims to localize the target object in a 3D point cloud by a free-form language description. Typically, the sentences describing the target object tend to provide information about its relative relation between other objects and its position within the whole scene. In this work, we propose a relation-aware one-stage framework, named 3D Relative Position-aware Network (3DRP-Net), which can effectively capture the relative spatial relationships between objects and enhance object attributes. Specifically, 1) we propose a 3D Relative Position Multi-head Attention (3DRP-MA) module to analyze relative relations from different directions in the context of object pairs, which helps the model to focus on the specific object relations mentioned in the sentence. 2) We designed a soft-labeling strategy to alleviate the spatial ambiguity caused by redundant points, which further stabilizes and enhances the learning process through a constant and discriminative distribution. Extensive experiments conducted on three benchmarks (i.e., ScanRefer and Nr3D/Sr3D) demonstrate that our method outperforms all the state-of-the-art methods in general. The source code will be released on GitHub.
Distilling Coarse-to-Fine Semantic Matching Knowledge for Weakly Supervised 3D Visual Grounding
Jul 18, 2023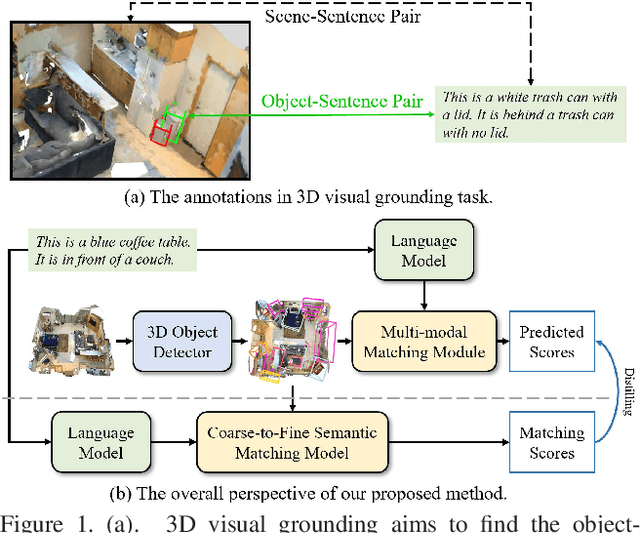
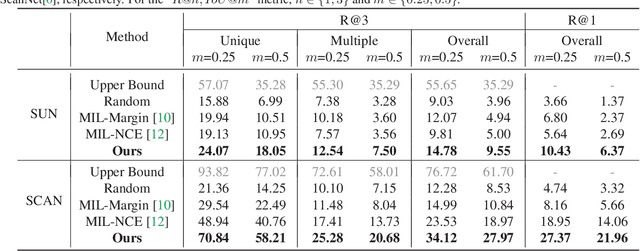
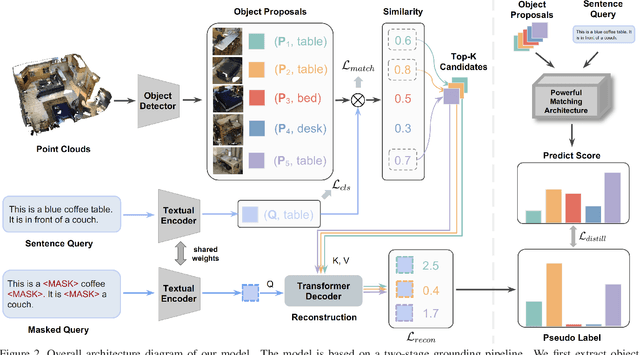
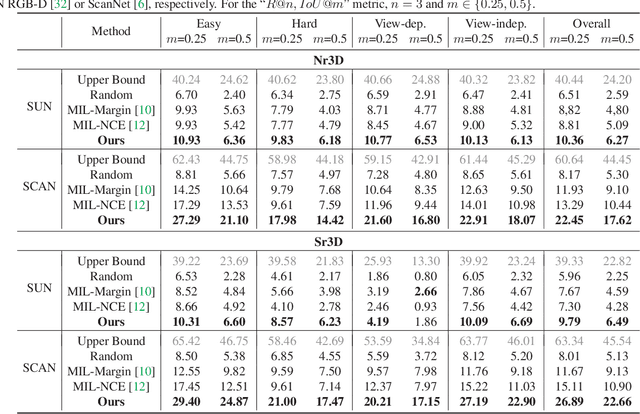
3D visual grounding involves finding a target object in a 3D scene that corresponds to a given sentence query. Although many approaches have been proposed and achieved impressive performance, they all require dense object-sentence pair annotations in 3D point clouds, which are both time-consuming and expensive. To address the problem that fine-grained annotated data is difficult to obtain, we propose to leverage weakly supervised annotations to learn the 3D visual grounding model, i.e., only coarse scene-sentence correspondences are used to learn object-sentence links. To accomplish this, we design a novel semantic matching model that analyzes the semantic similarity between object proposals and sentences in a coarse-to-fine manner. Specifically, we first extract object proposals and coarsely select the top-K candidates based on feature and class similarity matrices. Next, we reconstruct the masked keywords of the sentence using each candidate one by one, and the reconstructed accuracy finely reflects the semantic similarity of each candidate to the query. Additionally, we distill the coarse-to-fine semantic matching knowledge into a typical two-stage 3D visual grounding model, which reduces inference costs and improves performance by taking full advantage of the well-studied structure of the existing architectures. We conduct extensive experiments on ScanRefer, Nr3D, and Sr3D, which demonstrate the effectiveness of our proposed method.
Gloss Attention for Gloss-free Sign Language Translation
Jul 14, 2023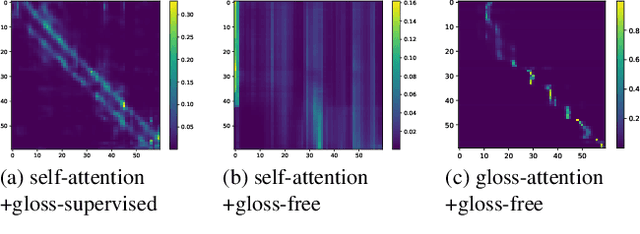
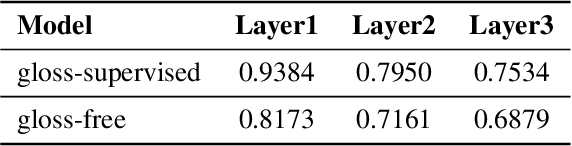

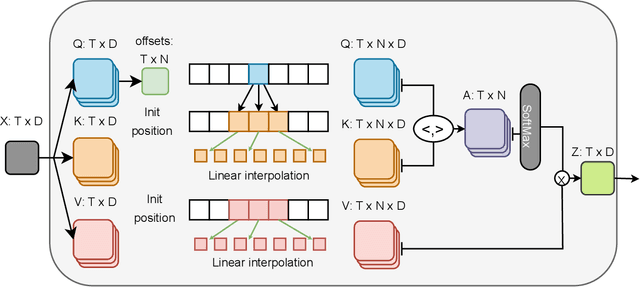
Most sign language translation (SLT) methods to date require the use of gloss annotations to provide additional supervision information, however, the acquisition of gloss is not easy. To solve this problem, we first perform an analysis of existing models to confirm how gloss annotations make SLT easier. We find that it can provide two aspects of information for the model, 1) it can help the model implicitly learn the location of semantic boundaries in continuous sign language videos, 2) it can help the model understand the sign language video globally. We then propose \emph{gloss attention}, which enables the model to keep its attention within video segments that have the same semantics locally, just as gloss helps existing models do. Furthermore, we transfer the knowledge of sentence-to-sentence similarity from the natural language model to our gloss attention SLT network (GASLT) to help it understand sign language videos at the sentence level. Experimental results on multiple large-scale sign language datasets show that our proposed GASLT model significantly outperforms existing methods. Our code is provided in \url{https://github.com/YinAoXiong/GASLT}.