 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-AEG: Scalable Data Construction for Open-Vocabulary Audio Event Grounding
Jul 05, 2026Large Audio-Language Models (LALMs) reason fluently about sound yet struggle to localize precisely when events occur, while classical Sound Event Detection attains frame-level precision only over a closed label set. At the intersection of these paradigms lies the task of Open-Vocabulary Audio Event Grounding: predicting all time intervals of a target sound event described by an arbitrary natural language query. While this task is crucial for real-world audio understanding and LALM adaptation, it is bottlenecked by data scarcity. Few large-scale resources provide open-vocabulary onset/offset supervision, and manual temporal annotation is prohibitively expensive. To address this, we introduce Auto-AEG, a scalable pipeline that constructs such supervision by automatic data construction and model fine-tuning. It pairs programmatically synthesized clips, which carry exact ground-truth intervals for supervised cold-start, with multi-model pseudo-labels on real-world audio that supply the reward signal for reinforcement learning. Training with this pipeline yields promising performance gains on both the DESED SED benchmark and AEGBench, an independent difficulty-stratified benchmark we release. Our results show that automatically constructed data, coupled with interval-aware reward function design, is an effective data-side route to expanding the temporal localization capability of LALMs.
KV-Control: Parameter-Efficient K/V Injection for Trajectory-Controlled Text-to-Motion
Jun 04, 2026Text-conditioned 3D human motion models now synthesize plausible motions from prompts, but practical animation and embodied-agent workflows rarely stop at text: a character may need to follow a sketched root path, hit an end-effector target, or satisfy a multi-joint trajectory while still preserving the gait, style, and intent described by language. This exposes a control trade-off. A trajectory controller should be precise without overwriting the pretrained text-conditioned motion prior, yet existing solutions either duplicate large portions of the generator to regain per-layer control access or move much of the cost to test-time optimization. We introduce KV-Control, a compact attention-side control interface for frozen masked text-to-motion transformers. The key idea is to make geometric constraints available as memory inside self-attention rather than injecting them through a global pose token or enforcing them only at the output side. To support this interface, we co-design a part-tokenized motion substrate and controller: \textbf{PartVQ} learns anatomy-aligned part codebooks, T-Concat exposes each frame--part token as an attention-addressable site, and KV-Control injects control-conditioned key/value memories at every self-attention layer while preserving the pretrained query stream, text cross-attention, FFN, and all backbone weights. The resulting adapter adds only trainable injection parameters atop a shared trajectory encoder, yet tracks root and multi-joint constraints with sub-centimeter accuracy under the inherited refinement protocol while retaining text-conditioned motion quality. KV-Control reframes trajectory conditioning as lightweight memory retrieval, providing a small, precise, and transparent control interface for text-to-motion generation.
AnchorRoute: Human Motion Synthesis with Interval-Routed Sparse Contro
May 14, 2026Sparse anchors provide a compact interface for human motion authoring: users specify a few root positions, planar trajectory samples, or body-point targets, while the system synthesizes the full-body motion that completes the under-specified intent. We present AnchorRoute, a sparse-anchor motion synthesis framework that uses anchors as a shared scaffold for both generation and refinement. Before generation, AnchorRoute converts sparse anchors into anchor-condition features and injects the resulting condition memory into a frozen Transition Masked Diffusion prior through AnchorKV and dual-context conditioning. This preserves the generation quality of the pretrained text-to-motion prior while learning sparse spatial control. After generation, the same anchors are evaluated as residuals: their timestamps define refinement intervals, and their residuals determine where correction should be concentrated. RouteSolver then refines the motion by projecting soft-token updates onto anchor-defined piecewise-affine interval bases. This couples generation-time anchor conditioning with residual-routed refinement under one anchor scaffold. AnchorRoute supports root-3D, planar-root, and body-point control within the same formulation. In benchmark evaluations, AnchorRoute outperforms prior sparse-control methods under the sparse keyjoint protocol and consistently improves anchor adherence across control families. The results show that the learned anchor-conditioned generator and RouteSolver refinement are complementary: the generator preserves text-motion quality, while RouteSolver provides a controllable path toward stronger anchor adherence.
UMo: Unified Sparse Motion Modeling for Real-Time Co-Speech Avatars
May 14, 2026Speech-driven gestures and facial animations are fundamental to expressive digital avatars in games, virtual production, and interactive media. However, existing methods are either limited to a single modality for audio motion alignment, failing to fully utilize the potential of massive human motion data, or are constrained by the representation ability and throughput of multimodal models, which makes it difficult to achieve high-quality motion generation or real-time performance. We present UMo, a unified sparse motion modeling architecture for real-time co-speech avatars, which processes text, audio, and motion tokens within a unified formulation. Leveraging a spatially sparse Mixture-of-Experts framework and a temporally sparse, keyframe-centric design, UMo efficiently performs real-time dense reconstruction, enabling temporally coherent and high-fidelity animation generation for both facial expressions and gestures. Furthermore, we implement a multi-stage training strategy with targeted audio augmentation to enhance acoustic diversity and semantic consistency. Consequently, UMo preserves fine-grained speech-motion alignment even under strict latency constraints. Extensive quantitative and qualitative evaluations show that UMo achieves better output quality under low latency and real-time performance constraints, offering a practical solution for high-fidelity real-time co-speech avatars.
Character Beyond Speech: Leveraging Role-Playing Evaluation in Audio Large Language Models via Reinforcement Learning
Apr 15, 2026The rapid evolution of multimodal large models has revolutionized the simulation of diverse characters in speech dialogue systems, enabling a novel interactive paradigm. Character attributes are manifested not only in textual responses but also through vocal features, as speech conveys rich paralinguistic information that is challenging to quantify. This poses significant difficulties in evaluating the character alignment of role-playing agents. To address these challenges, we present RoleJudge, an evaluation framework that leverages audio large language models to systematically assess the alignment between speech and character across multiple modalities and dimensions. Furthermore, we introduce RoleChat, the first voice role-playing evaluation dataset enriched with chain-of-thought reasoning annotations, comprising a diverse set of authentic and LLM-generated speech samples. Utilizing this dataset, we implement a multi-stage training paradigm and incorporate Standard Alignment in reinforcement learning to mitigate reward misalignment during optimization. Experimental results in terms of accuracy and subjective assessment demonstrate that RoleJudge outperforms various baseline models, validating the effectiveness of our multidimensional evaluation framework.
MOGO: Residual Quantized Hierarchical Causal Transformer for High-Quality and Real-Time 3D Human Motion Generation
Jun 06, 2025Recent advances in transformer-based text-to-motion generation have led to impressive progress in synthesizing high-quality human motion. Nevertheless, jointly achieving high fidelity, streaming capability, real-time responsiveness, and scalability remains a fundamental challenge. In this paper, we propose MOGO (Motion Generation with One-pass), a novel autoregressive framework tailored for efficient and real-time 3D motion generation. MOGO comprises two key components: (1) MoSA-VQ, a motion scale-adaptive residual vector quantization module that hierarchically discretizes motion sequences with learnable scaling to produce compact yet expressive representations; and (2) RQHC-Transformer, a residual quantized hierarchical causal transformer that generates multi-layer motion tokens in a single forward pass, significantly reducing inference latency. To enhance semantic fidelity, we further introduce a text condition alignment mechanism that improves motion decoding under textual control. Extensive experiments on benchmark datasets including HumanML3D, KIT-ML, and CMP demonstrate that MOGO achieves competitive or superior generation quality compared to state-of-the-art transformer-based methods, while offering substantial improvements in real-time performance, streaming generation, and generalization under zero-shot settings.
OmniChat: Enhancing Spoken Dialogue Systems with Scalable Synthetic Data for Diverse Scenarios
Jan 02, 2025



With the rapid development of large language models, researchers have created increasingly advanced spoken dialogue systems that can naturally converse with humans. However, these systems still struggle to handle the full complexity of real-world conversations, including audio events, musical contexts, and emotional expressions, mainly because current dialogue datasets are constrained in both scale and scenario diversity. In this paper, we propose leveraging synthetic data to enhance the dialogue models across diverse scenarios. We introduce ShareChatX, the first comprehensive, large-scale dataset for spoken dialogue that spans diverse scenarios. Based on this dataset, we introduce OmniChat, a multi-turn dialogue system with a heterogeneous feature fusion module, designed to optimize feature selection in different dialogue contexts. In addition, we explored critical aspects of training dialogue systems using synthetic data. Through comprehensive experimentation, we determined the ideal balance between synthetic and real data, achieving state-of-the-art results on the real-world dialogue dataset DailyTalk. We also highlight the crucial importance of synthetic data in tackling diverse, complex dialogue scenarios, especially those involving audio and music. For more details, please visit our demo page at \url{https://sharechatx.github.io/}.
Mogo: RQ Hierarchical Causal Transformer for High-Quality 3D Human Motion Generation
Dec 05, 2024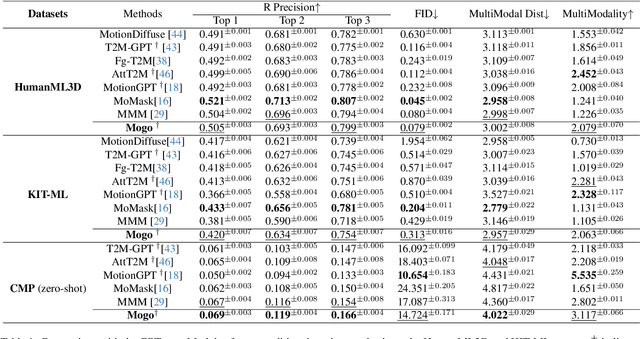
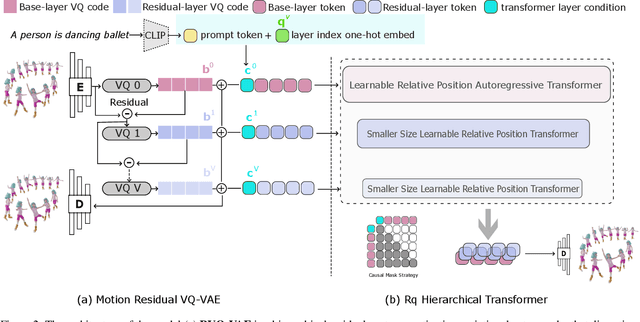
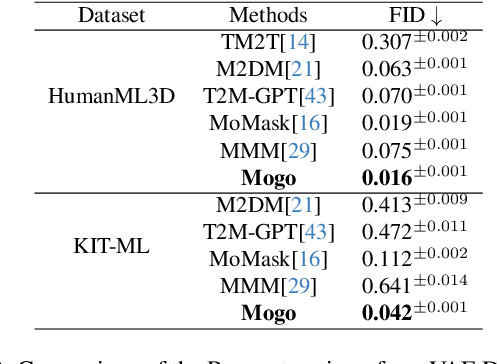
In the field of text-to-motion generation, Bert-type Masked Models (MoMask, MMM) currently produce higher-quality outputs compared to GPT-type autoregressive models (T2M-GPT). However, these Bert-type models often lack the streaming output capability required for applications in video game and multimedia environments, a feature inherent to GPT-type models. Additionally, they demonstrate weaker performance in out-of-distribution generation. To surpass the quality of BERT-type models while leveraging a GPT-type structure, without adding extra refinement models that complicate scaling data, we propose a novel architecture, Mogo (Motion Only Generate Once), which generates high-quality lifelike 3D human motions by training a single transformer model. Mogo consists of only two main components: 1) RVQ-VAE, a hierarchical residual vector quantization variational autoencoder, which discretizes continuous motion sequences with high precision; 2) Hierarchical Causal Transformer, responsible for generating the base motion sequences in an autoregressive manner while simultaneously inferring residuals across different layers. Experimental results demonstrate that Mogo can generate continuous and cyclic motion sequences up to 260 frames (13 seconds), surpassing the 196 frames (10 seconds) length limitation of existing datasets like HumanML3D. On the HumanML3D test set, Mogo achieves a FID score of 0.079, outperforming both the GPT-type model T2M-GPT (FID = 0.116), AttT2M (FID = 0.112) and the BERT-type model MMM (FID = 0.080). Furthermore, our model achieves the best quantitative performance in out-of-distribution generation.