 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivileged Foresight Distillation: Zero-Cost Future Correction for World Action Models
Apr 28, 2026World action models jointly predict future video and action during training, raising an open question about what role the future-prediction branch actually plays. A recent finding shows that this branch can be removed at inference with little to no loss on common manipulation benchmarks, suggesting that future information may act merely as a regularizer on the shared visual backbone. We propose instead that joint training induces an action-conditioned correction that privileged future observations impose on action denoising, and that current-only policies capture this correction only partially. Making the account precise, we formulate privileged foresight as a residual in the action-denoising direction -- the difference between what a model predicts given the true future and what it predicts given only the current frame -- and introduce \emph{Privileged Foresight Distillation (PFD)}, which transfers this residual from a training-time teacher into a small adapter on a current-only student. The teacher and student share the same backbone and differ only in the attention mask over video tokens; future video is never generated at inference. Controlled experiments verify that this gain reflects a genuine future-conditioned correction rather than a side effect of capacity or regularization. Empirically, PFD achieves consistent improvements on LIBERO and RoboTwin manipulation benchmarks while preserving the current-only inference interface at negligible added latency. This view reframes the role of future information in world action models: not as a target to predict, nor as a regularizer to absorb, but as a compressible correction to be distilled.
Mitigating Preference Leakage via Strict Estimator Separation for Normative Generative Ranking
Feb 25, 2026In Generative Information Retrieval (GenIR), the bottleneck has shifted from generation to the selection of candidates, particularly for normative criteria such as cultural relevance. Current LLM-as-a-Judge evaluations often suffer from circularity and preference leakage, where overlapping supervision and evaluation models inflate performance. We address this by formalising cultural relevance as a within-query ranking task and introducing a leakage-free two-judge framework that strictly separates supervision (Judge B) from evaluation (Judge A). On a new benchmark of 33,052 (NGR-33k) culturally grounded stories, we find that while classical baselines yield only modest gains, a dense bi-encoder distilled from a Judge-B-supervised Cross-Encoder is highly effective. Although the Cross-Encoder provides a strong supervision signal for distillation, the distilled BGE-M3 model substantially outperforms it under leakage-free Judge~A evaluation. We validate our framework on the human-curated Moral Stories dataset, showing strong alignment with human norms. Our results demonstrate that rigorous evaluator separation is a prerequisite for credible GenIR evaluation, proving that subtle cultural preferences can be distilled into efficient rankers without leakage.
SEIS: Subspace-based Equivariance and Invariance Scores for Neural Representations
Feb 03, 2026Understanding how neural representations respond to geometric transformations is essential for evaluating whether learned features preserve meaningful spatial structure. Existing approaches primarily assess robustness by comparing model outputs under transformed inputs, offering limited insight into how geometric information is organized within internal representations and failing to distinguish between information loss and re-encoding. In this work, we introduce SEIS (Subspace-based Equivariance and Invariance Scores), a subspace metric for analyzing layer-wise feature representations under geometric transformations, disentangling equivariance from invariance without requiring labels or explicit knowledge of the transformation. Synthetic validation confirms that SEIS correctly recovers known transformations. Applied to trained classification networks, SEIS reveals a transition from equivariance in early layers to invariance in deeper layers, and that data augmentation increases invariance while preserving equivariance. We further show that multi-task learning induces synergistic gains in both properties at the shared encoder, and skip connections restore equivariance lost during decoding.
CALM: Culturally Self-Aware Language Models
Jan 07, 2026Cultural awareness in language models is the capacity to understand and adapt to diverse cultural contexts. However, most existing approaches treat culture as static background knowledge, overlooking its dynamic and evolving nature. This limitation reduces their reliability in downstream tasks that demand genuine cultural sensitivity. In this work, we introduce CALM, a novel framework designed to endow language models with cultural self-awareness. CALM disentangles task semantics from explicit cultural concepts and latent cultural signals, shaping them into structured cultural clusters through contrastive learning. These clusters are then aligned via cross-attention to establish fine-grained interactions among related cultural features and are adaptively integrated through a Mixture-of-Experts mechanism along culture-specific dimensions. The resulting unified representation is fused with the model's original knowledge to construct a culturally grounded internal identity state, which is further enhanced through self-prompted reflective learning, enabling continual adaptation and self-correction. Extensive experiments conducted on multiple cross-cultural benchmark datasets demonstrate that CALM consistently outperforms state-of-the-art methods.
GRASPTrack: Geometry-Reasoned Association via Segmentation and Projection for Multi-Object Tracking
Aug 11, 2025Multi-object tracking (MOT) in monocular videos is fundamentally challenged by occlusions and depth ambiguity, issues that conventional tracking-by-detection (TBD) methods struggle to resolve owing to a lack of geometric awareness. To address these limitations, we introduce GRASPTrack, a novel depth-aware MOT framework that integrates monocular depth estimation and instance segmentation into a standard TBD pipeline to generate high-fidelity 3D point clouds from 2D detections, thereby enabling explicit 3D geometric reasoning. These 3D point clouds are then voxelized to enable a precise and robust Voxel-Based 3D Intersection-over-Union (IoU) for spatial association. To further enhance tracking robustness, our approach incorporates Depth-aware Adaptive Noise Compensation, which dynamically adjusts the Kalman filter process noise based on occlusion severity for more reliable state estimation. Additionally, we propose a Depth-enhanced Observation-Centric Momentum, which extends the motion direction consistency from the image plane into 3D space to improve motion-based association cues, particularly for objects with complex trajectories. Extensive experiments on the MOT17, MOT20, and DanceTrack benchmarks demonstrate that our method achieves competitive performance, significantly improving tracking robustness in complex scenes with frequent occlusions and intricate motion patterns.
MOGO: Residual Quantized Hierarchical Causal Transformer for High-Quality and Real-Time 3D Human Motion Generation
Jun 06, 2025Recent advances in transformer-based text-to-motion generation have led to impressive progress in synthesizing high-quality human motion. Nevertheless, jointly achieving high fidelity, streaming capability, real-time responsiveness, and scalability remains a fundamental challenge. In this paper, we propose MOGO (Motion Generation with One-pass), a novel autoregressive framework tailored for efficient and real-time 3D motion generation. MOGO comprises two key components: (1) MoSA-VQ, a motion scale-adaptive residual vector quantization module that hierarchically discretizes motion sequences with learnable scaling to produce compact yet expressive representations; and (2) RQHC-Transformer, a residual quantized hierarchical causal transformer that generates multi-layer motion tokens in a single forward pass, significantly reducing inference latency. To enhance semantic fidelity, we further introduce a text condition alignment mechanism that improves motion decoding under textual control. Extensive experiments on benchmark datasets including HumanML3D, KIT-ML, and CMP demonstrate that MOGO achieves competitive or superior generation quality compared to state-of-the-art transformer-based methods, while offering substantial improvements in real-time performance, streaming generation, and generalization under zero-shot settings.
Less but Better: Parameter-Efficient Fine-Tuning of Large Language Models for Personality Detection
Apr 07, 2025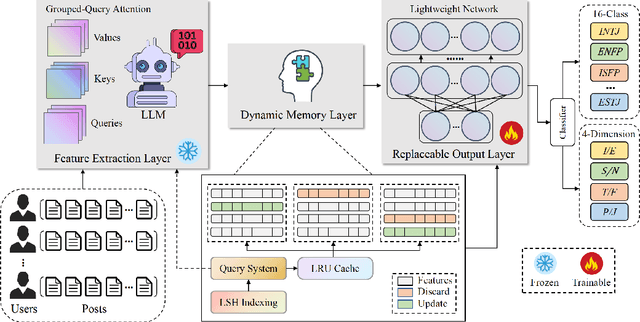
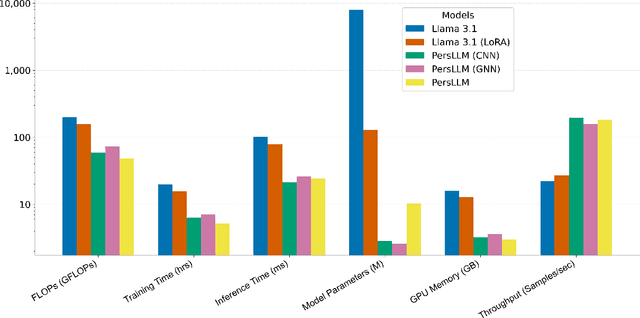
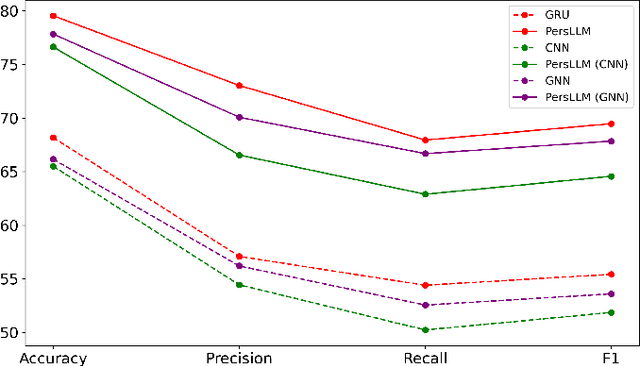
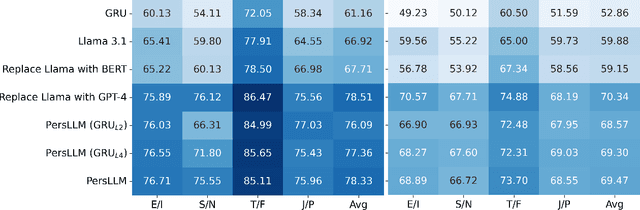
Personality detection automatically identifies an individual's personality from various data sources, such as social media texts. However, as the parameter scale of language models continues to grow, the computational cost becomes increasingly difficult to manage. Fine-tuning also grows more complex, making it harder to justify the effort and reliably predict outcomes. We introduce a novel parameter-efficient fine-tuning framework, PersLLM, to address these challenges. In PersLLM, a large language model (LLM) extracts high-dimensional representations from raw data and stores them in a dynamic memory layer. PersLLM then updates the downstream layers with a replaceable output network, enabling flexible adaptation to various personality detection scenarios. By storing the features in the memory layer, we eliminate the need for repeated complex computations by the LLM. Meanwhile, the lightweight output network serves as a proxy for evaluating the overall effectiveness of the framework, improving the predictability of results. Experimental results on key benchmark datasets like Kaggle and Pandora show that PersLLM significantly reduces computational cost while maintaining competitive performance and strong adaptability.
CornerPoint3D: Look at the Nearest Corner Instead of the Center
Apr 03, 2025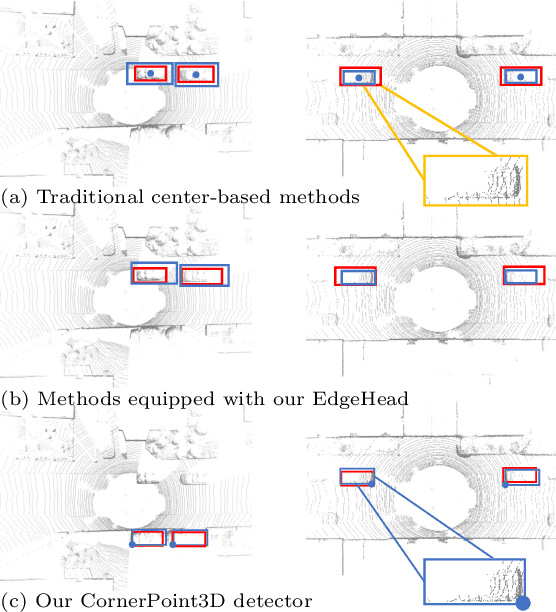
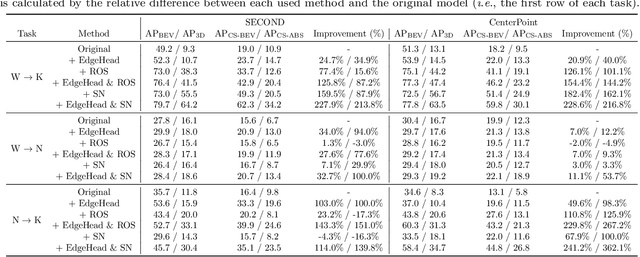
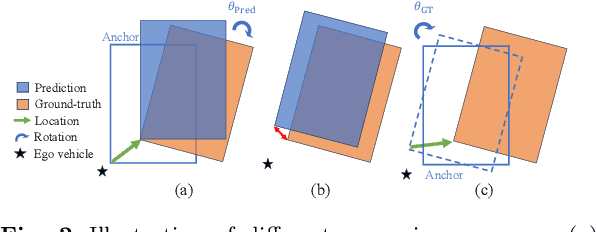
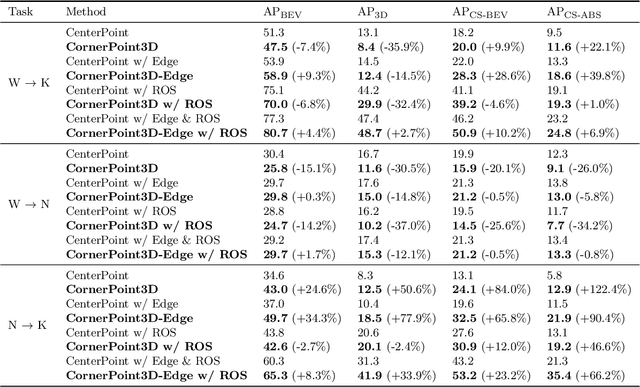
3D object detection aims to predict object centers, dimensions, and rotations from LiDAR point clouds. Despite its simplicity, LiDAR captures only the near side of objects, making center-based detectors prone to poor localization accuracy in cross-domain tasks with varying point distributions. Meanwhile, existing evaluation metrics designed for single-domain assessment also suffer from overfitting due to dataset-specific size variations. A key question arises: Do we really need models to maintain excellent performance in the entire 3D bounding boxes after being applied across domains? Actually, one of our main focuses is on preventing collisions between vehicles and other obstacles, especially in cross-domain scenarios where correctly predicting the sizes is much more difficult. To address these issues, we rethink cross-domain 3D object detection from a practical perspective. We propose two new metrics that evaluate a model's ability to detect objects' closer-surfaces to the LiDAR sensor. Additionally, we introduce EdgeHead, a refinement head that guides models to focus more on learnable closer surfaces, significantly improving cross-domain performance under both our new and traditional BEV/3D metrics. Furthermore, we argue that predicting the nearest corner rather than the object center enhances robustness. We propose a novel 3D object detector, coined as CornerPoint3D, which is built upon CenterPoint and uses heatmaps to supervise the learning and detection of the nearest corner of each object. Our proposed methods realize a balanced trade-off between the detection quality of entire bounding boxes and the locating accuracy of closer surfaces to the LiDAR sensor, outperforming the traditional center-based detector CenterPoint in multiple cross-domain tasks and providing a more practically reasonable and robust cross-domain 3D object detection solution.
LL4G: Self-Supervised Dynamic Optimization for Graph-Based Personality Detection
Apr 02, 2025Graph-based personality detection constructs graph structures from textual data, particularly social media posts. Current methods often struggle with sparse or noisy data and rely on static graphs, limiting their ability to capture dynamic changes between nodes and relationships. This paper introduces LL4G, a self-supervised framework leveraging large language models (LLMs) to optimize graph neural networks (GNNs). LLMs extract rich semantic features to generate node representations and to infer explicit and implicit relationships. The graph structure adaptively adds nodes and edges based on input data, continuously optimizing itself. The GNN then uses these optimized representations for joint training on node reconstruction, edge prediction, and contrastive learning tasks. This integration of semantic and structural information generates robust personality profiles. Experimental results on Kaggle and Pandora datasets show LL4G outperforms state-of-the-art models.
tCURLoRA: Tensor CUR Decomposition Based Low-Rank Parameter Adaptation for Medical Image Segmentation
Jan 04, 2025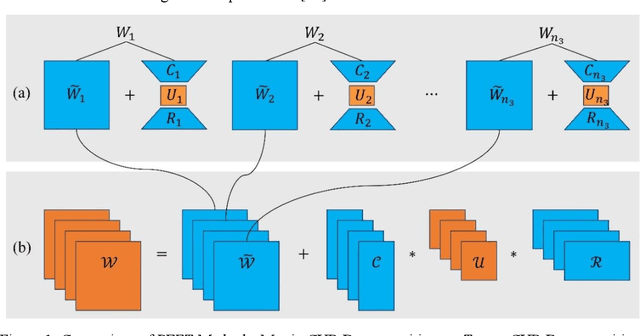

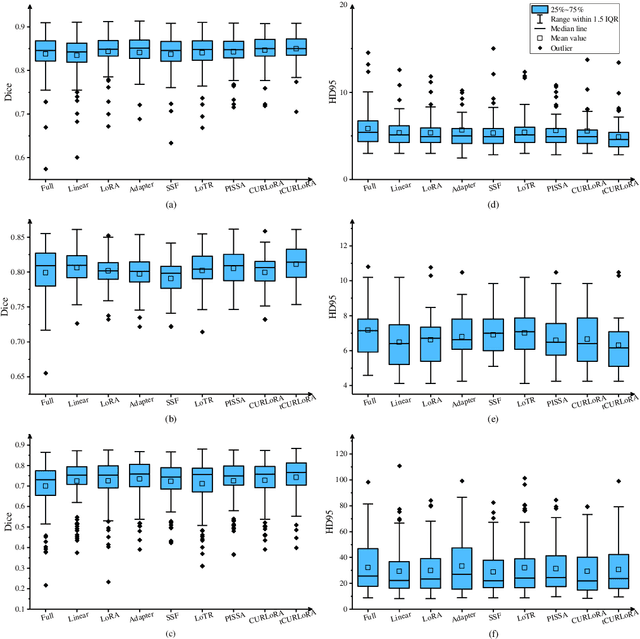
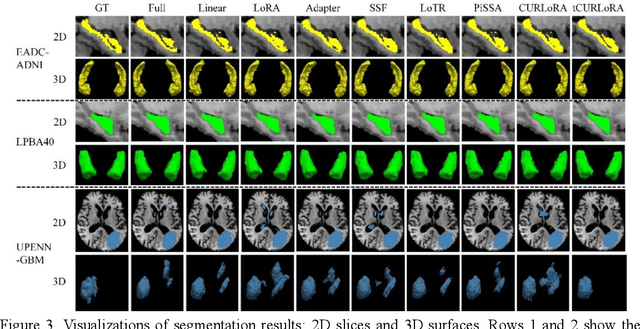
Transfer learning, by leveraging knowledge from pre-trained models, has significantly enhanced the performance of target tasks. However, as deep neural networks scale up, full fine-tuning introduces substantial computational and storage challenges in resource-constrained environments, limiting its widespread adoption. To address this, parameter-efficient fine-tuning (PEFT) methods have been developed to reduce computational complexity and storage requirements by minimizing the number of updated parameters. While matrix decomposition-based PEFT methods, such as LoRA, show promise, they struggle to fully capture the high-dimensional structural characteristics of model weights. In contrast, high-dimensional tensors offer a more natural representation of neural network weights, allowing for a more comprehensive capture of higher-order features and multi-dimensional interactions. In this paper, we propose tCURLoRA, a novel fine-tuning method based on tensor CUR decomposition. By concatenating pre-trained weight matrices into a three-dimensional tensor and applying tensor CUR decomposition, we update only the lower-order tensor components during fine-tuning, effectively reducing computational and storage overhead. Experimental results demonstrate that tCURLoRA outperforms existing PEFT methods in medical image segmentation tasks.