 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSP-Reg: Domain-Sensitive Parameter Regularization for Robust Domain Generalization
Jan 27, 2026Domain Generalization (DG) is a critical area that focuses on developing models capable of performing well on data from unseen distributions, which is essential for real-world applications. Existing approaches primarily concentrate on learning domain-invariant features, which assume that a model robust to variations in the source domains will generalize well to unseen target domains. However, these approaches neglect a deeper analysis at the parameter level, which makes the model hard to explicitly differentiate between parameters sensitive to domain shifts and those robust, potentially hindering its overall ability to generalize. In order to address these limitations, we first build a covariance-based parameter sensitivity analysis framework to quantify the sensitivity of each parameter in a model to domain shifts. By computing the covariance of parameter gradients across multiple source domains, we can identify parameters that are more susceptible to domain variations, which serves as our theoretical foundation. Based on this, we propose Domain-Sensitive Parameter Regularization (DSP-Reg), a principled framework that guides model optimization by a soft regularization technique that encourages the model to rely more on domain-invariant parameters while suppressing those that are domain-specific. This approach provides a more granular control over the model's learning process, leading to improved robustness and generalization to unseen domains. Extensive experiments on benchmarks, such as PACS, VLCS, OfficeHome, and DomainNet, demonstrate that DSP-Reg outperforms state-of-the-art approaches, achieving an average accuracy of 66.7\% and surpassing all baselines.
GRASPTrack: Geometry-Reasoned Association via Segmentation and Projection for Multi-Object Tracking
Aug 11, 2025Multi-object tracking (MOT) in monocular videos is fundamentally challenged by occlusions and depth ambiguity, issues that conventional tracking-by-detection (TBD) methods struggle to resolve owing to a lack of geometric awareness. To address these limitations, we introduce GRASPTrack, a novel depth-aware MOT framework that integrates monocular depth estimation and instance segmentation into a standard TBD pipeline to generate high-fidelity 3D point clouds from 2D detections, thereby enabling explicit 3D geometric reasoning. These 3D point clouds are then voxelized to enable a precise and robust Voxel-Based 3D Intersection-over-Union (IoU) for spatial association. To further enhance tracking robustness, our approach incorporates Depth-aware Adaptive Noise Compensation, which dynamically adjusts the Kalman filter process noise based on occlusion severity for more reliable state estimation. Additionally, we propose a Depth-enhanced Observation-Centric Momentum, which extends the motion direction consistency from the image plane into 3D space to improve motion-based association cues, particularly for objects with complex trajectories. Extensive experiments on the MOT17, MOT20, and DanceTrack benchmarks demonstrate that our method achieves competitive performance, significantly improving tracking robustness in complex scenes with frequent occlusions and intricate motion patterns.
Enhancing Fetal Plane Classification Accuracy with Data Augmentation Using Diffusion Models
Jan 25, 2025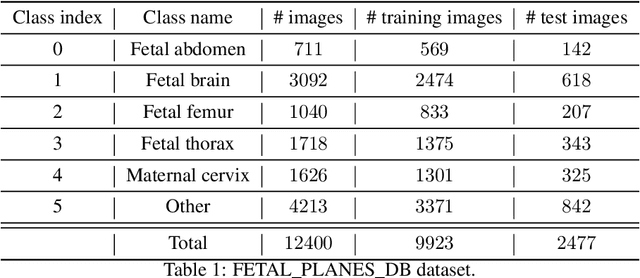
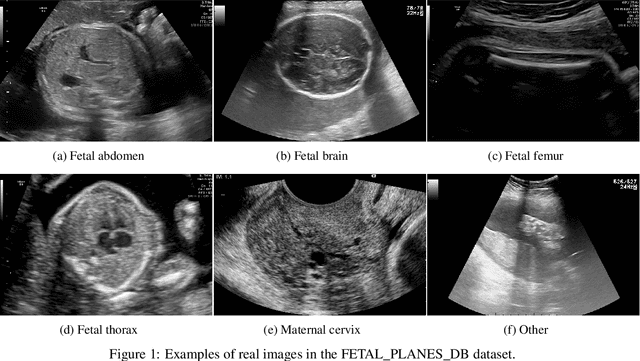
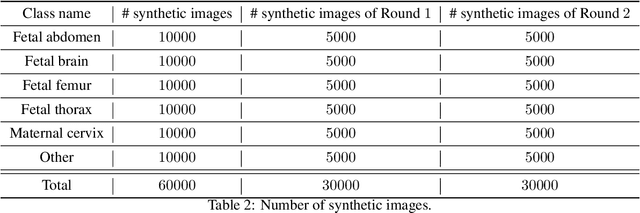
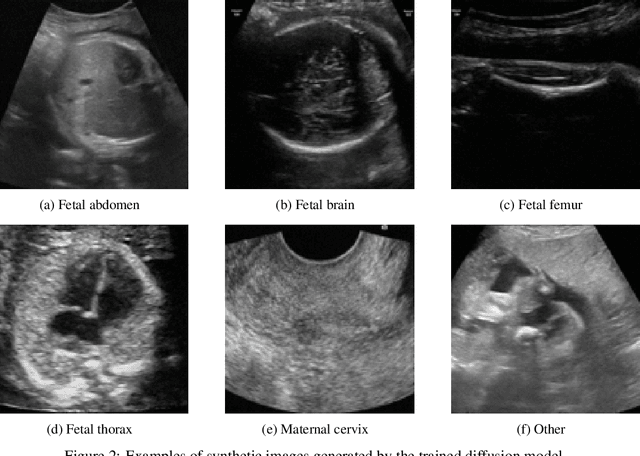
Ultrasound imaging is widely used in medical diagnosis, especially for fetal health assessment. However, the availability of high-quality annotated ultrasound images is limited, which restricts the training of machine learning models. In this paper, we investigate the use of diffusion models to generate synthetic ultrasound images to improve the performance on fetal plane classification. We train different classifiers first on synthetic images and then fine-tune them with real images. Extensive experimental results demonstrate that incorporating generated images into training pipelines leads to better classification accuracy than training with real images alone. The findings suggest that generating synthetic data using diffusion models can be a valuable tool in overcoming the challenges of data scarcity in ultrasound medical imaging.
ETTrack: Enhanced Temporal Motion Predictor for Multi-Object Tracking
May 24, 2024



Many Multi-Object Tracking (MOT) approaches exploit motion information to associate all the detected objects across frames. However, many methods that rely on filtering-based algorithms, such as the Kalman Filter, often work well in linear motion scenarios but struggle to accurately predict the locations of objects undergoing complex and non-linear movements. To tackle these scenarios, we propose a motion-based MOT approach with an enhanced temporal motion predictor, ETTrack. Specifically, the motion predictor integrates a transformer model and a Temporal Convolutional Network (TCN) to capture short-term and long-term motion patterns, and it predicts the future motion of individual objects based on the historical motion information. Additionally, we propose a novel Momentum Correction Loss function that provides additional information regarding the motion direction of objects during training. This allows the motion predictor rapidly adapt to motion variations and more accurately predict future motion. Our experimental results demonstrate that ETTrack achieves a competitive performance compared with state-of-the-art trackers on DanceTrack and SportsMOT, scoring 56.4% and 74.4% in HOTA metrics, respectively.