 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRASPTrack: Geometry-Reasoned Association via Segmentation and Projection for Multi-Object Tracking
Aug 11, 2025Multi-object tracking (MOT) in monocular videos is fundamentally challenged by occlusions and depth ambiguity, issues that conventional tracking-by-detection (TBD) methods struggle to resolve owing to a lack of geometric awareness. To address these limitations, we introduce GRASPTrack, a novel depth-aware MOT framework that integrates monocular depth estimation and instance segmentation into a standard TBD pipeline to generate high-fidelity 3D point clouds from 2D detections, thereby enabling explicit 3D geometric reasoning. These 3D point clouds are then voxelized to enable a precise and robust Voxel-Based 3D Intersection-over-Union (IoU) for spatial association. To further enhance tracking robustness, our approach incorporates Depth-aware Adaptive Noise Compensation, which dynamically adjusts the Kalman filter process noise based on occlusion severity for more reliable state estimation. Additionally, we propose a Depth-enhanced Observation-Centric Momentum, which extends the motion direction consistency from the image plane into 3D space to improve motion-based association cues, particularly for objects with complex trajectories. Extensive experiments on the MOT17, MOT20, and DanceTrack benchmarks demonstrate that our method achieves competitive performance, significantly improving tracking robustness in complex scenes with frequent occlusions and intricate motion patterns.
In Shift and In Variance: Assessing the Robustness of HAR Deep Learning Models against Variability
Mar 14, 2025



Human Activity Recognition (HAR) using wearable inertial measurement unit (IMU) sensors can revolutionize healthcare by enabling continual health monitoring, disease prediction, and routine recognition. Despite the high accuracy of Deep Learning (DL) HAR models, their robustness to real-world variabilities remains untested, as they have primarily been trained and tested on limited lab-confined data. In this study, we isolate subject, device, position, and orientation variability to determine their effect on DL HAR models and assess the robustness of these models in real-world conditions. We evaluated the DL HAR models using the HARVAR and REALDISP datasets, providing a comprehensive discussion on the impact of variability on data distribution shifts and changes in model performance. Our experiments measured shifts in data distribution using Maximum Mean Discrepancy (MMD) and observed DL model performance drops due to variability. We concur that studied variabilities affect DL HAR models differently, and there is an inverse relationship between data distribution shifts and model performance. The compounding effect of variability was analyzed, and the implications of variabilities in real-world scenarios were highlighted. MMD proved an effective metric for calculating data distribution shifts and explained the drop in performance due to variabilities in HARVAR and REALDISP datasets. Combining our understanding of variability with evaluating its effects will facilitate the development of more robust DL HAR models and optimal training techniques. Allowing Future models to not only be assessed based on their maximum F1 score but also on their ability to generalize effectively
Scaling laws in wearable human activity recognition
Feb 05, 2025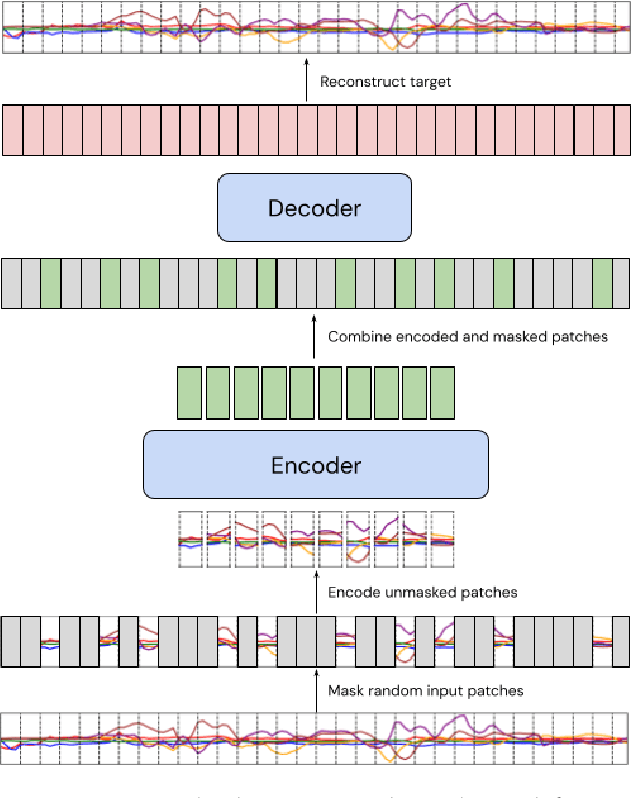
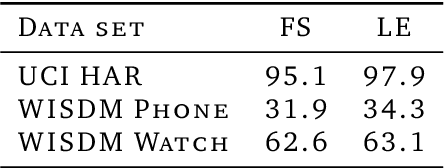
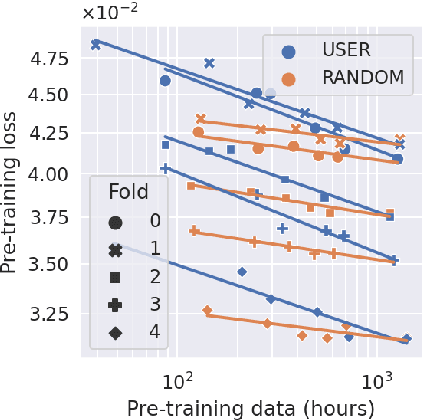
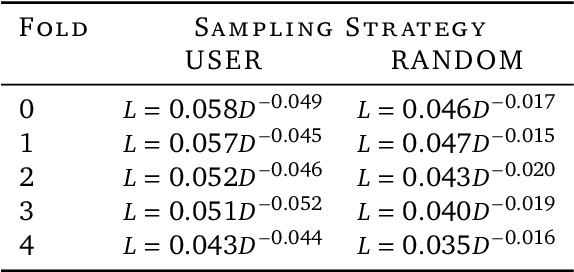
Many deep architectures and self-supervised pre-training techniques have been proposed for human activity recognition (HAR) from wearable multimodal sensors. Scaling laws have the potential to help move towards more principled design by linking model capacity with pre-training data volume. Yet, scaling laws have not been established for HAR to the same extent as in language and vision. By conducting an exhaustive grid search on both amount of pre-training data and Transformer architectures, we establish the first known scaling laws for HAR. We show that pre-training loss scales with a power law relationship to amount of data and parameter count and that increasing the number of users in a dataset results in a steeper improvement in performance than increasing data per user, indicating that diversity of pre-training data is important, which contrasts to some previously reported findings in self-supervised HAR. We show that these scaling laws translate to downstream performance improvements on three HAR benchmark datasets of postures, modes of locomotion and activities of daily living: UCI HAR and WISDM Phone and WISDM Watch. Finally, we suggest some previously published works should be revisited in light of these scaling laws with more adequate model capacities.