 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Level Diffusion Guidance: Well Begun is Half Done
Sep 17, 2025



Diffusion models have achieved state-of-the-art image generation. However, the random Gaussian noise used to start the diffusion process influences the final output, causing variations in image quality and prompt adherence. Existing noise-level optimization approaches generally rely on extra dataset construction, additional networks, or backpropagation-based optimization, limiting their practicality. In this paper, we propose Noise Level Guidance (NLG), a simple, efficient, and general noise-level optimization approach that refines initial noise by increasing the likelihood of its alignment with general guidance - requiring no additional training data, auxiliary networks, or backpropagation. The proposed NLG approach provides a unified framework generalizable to both conditional and unconditional diffusion models, accommodating various forms of diffusion-level guidance. Extensive experiments on five standard benchmarks demonstrate that our approach enhances output generation quality and input condition adherence. By seamlessly integrating with existing guidance methods while maintaining computational efficiency, our method establishes NLG as a practical and scalable enhancement to diffusion models. Code can be found at https://github.com/harveymannering/NoiseLevelGuidance.
CornerPoint3D: Look at the Nearest Corner Instead of the Center
Apr 03, 2025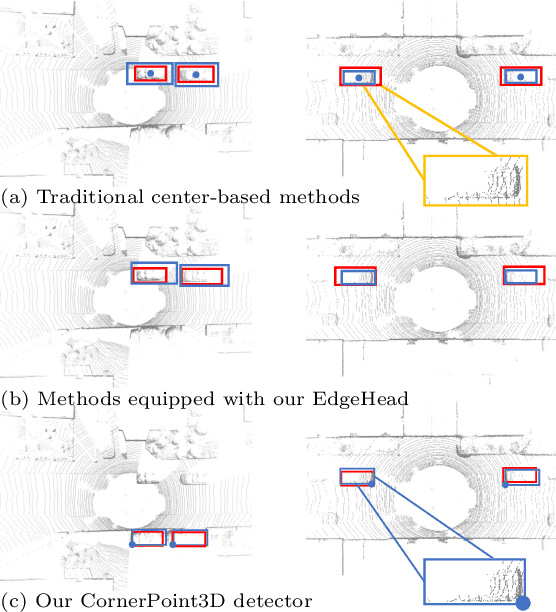
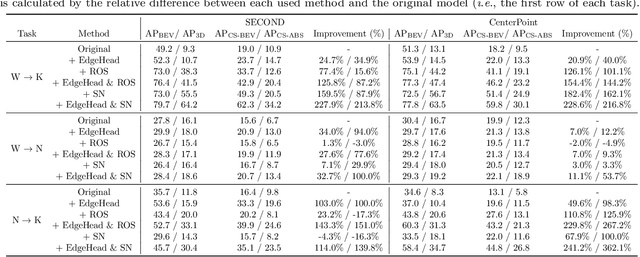
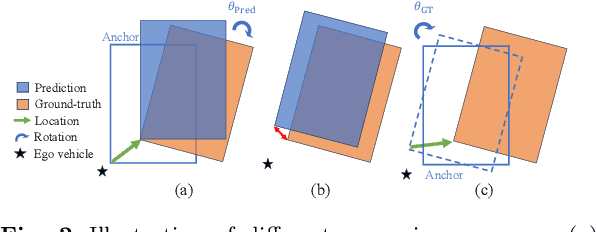
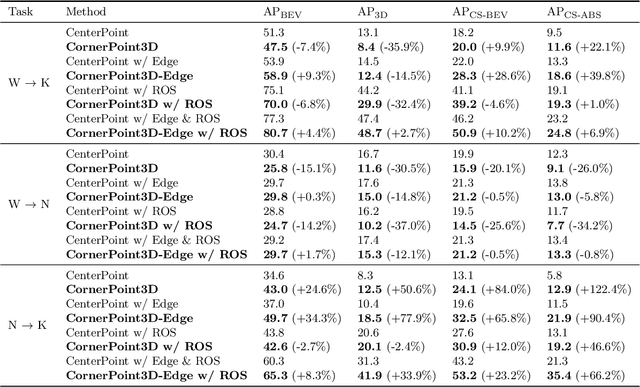
3D object detection aims to predict object centers, dimensions, and rotations from LiDAR point clouds. Despite its simplicity, LiDAR captures only the near side of objects, making center-based detectors prone to poor localization accuracy in cross-domain tasks with varying point distributions. Meanwhile, existing evaluation metrics designed for single-domain assessment also suffer from overfitting due to dataset-specific size variations. A key question arises: Do we really need models to maintain excellent performance in the entire 3D bounding boxes after being applied across domains? Actually, one of our main focuses is on preventing collisions between vehicles and other obstacles, especially in cross-domain scenarios where correctly predicting the sizes is much more difficult. To address these issues, we rethink cross-domain 3D object detection from a practical perspective. We propose two new metrics that evaluate a model's ability to detect objects' closer-surfaces to the LiDAR sensor. Additionally, we introduce EdgeHead, a refinement head that guides models to focus more on learnable closer surfaces, significantly improving cross-domain performance under both our new and traditional BEV/3D metrics. Furthermore, we argue that predicting the nearest corner rather than the object center enhances robustness. We propose a novel 3D object detector, coined as CornerPoint3D, which is built upon CenterPoint and uses heatmaps to supervise the learning and detection of the nearest corner of each object. Our proposed methods realize a balanced trade-off between the detection quality of entire bounding boxes and the locating accuracy of closer surfaces to the LiDAR sensor, outperforming the traditional center-based detector CenterPoint in multiple cross-domain tasks and providing a more practically reasonable and robust cross-domain 3D object detection solution.
Revisiting Cross-Domain Problem for LiDAR-based 3D Object Detection
Aug 22, 2024



Deep learning models such as convolutional neural networks and transformers have been widely applied to solve 3D object detection problems in the domain of autonomous driving. While existing models have achieved outstanding performance on most open benchmarks, the generalization ability of these deep networks is still in doubt. To adapt models to other domains including different cities, countries, and weather, retraining with the target domain data is currently necessary, which hinders the wide application of autonomous driving. In this paper, we deeply analyze the cross-domain performance of the state-of-the-art models. We observe that most models will overfit the training domains and it is challenging to adapt them to other domains directly. Existing domain adaptation methods for 3D object detection problems are actually shifting the models' knowledge domain instead of improving their generalization ability. We then propose additional evaluation metrics -- the side-view and front-view AP -- to better analyze the core issues of the methods' heavy drops in accuracy levels. By using the proposed metrics and further evaluating the cross-domain performance in each dimension, we conclude that the overfitting problem happens more obviously on the front-view surface and the width dimension which usually faces the sensor and has more 3D points surrounding it. Meanwhile, our experiments indicate that the density of the point cloud data also significantly influences the models' cross-domain performance.
Penny-Wise and Pound-Foolish in Deepfake Detection
Aug 15, 2024



The diffusion of deepfake technologies has sparked serious concerns about its potential misuse across various domains, prompting the urgent need for robust detection methods. Despite advancement, many current approaches prioritize short-term gains at expense of long-term effectiveness. This paper critiques the overly specialized approach of fine-tuning pre-trained models solely with a penny-wise objective on a single deepfake dataset, while disregarding the pound-wise balance for generalization and knowledge retention. To address this "Penny-Wise and Pound-Foolish" issue, we propose a novel learning framework (PoundNet) for generalization of deepfake detection on a pre-trained vision-language model. PoundNet incorporates a learnable prompt design and a balanced objective to preserve broad knowledge from upstream tasks (object classification) while enhancing generalization for downstream tasks (deepfake detection). We train PoundNet on a standard single deepfake dataset, following common practice in the literature. We then evaluate its performance across 10 public large-scale deepfake datasets with 5 main evaluation metrics-forming the largest benchmark test set for assessing the generalization ability of deepfake detection models, to our knowledge. The comprehensive benchmark evaluation demonstrates the proposed PoundNet is significantly less "Penny-Wise and Pound-Foolish", achieving a remarkable improvement of 19% in deepfake detection performance compared to state-of-the-art methods, while maintaining a strong performance of 63% on object classification tasks, where other deepfake detection models tend to be ineffective. Code and data are open-sourced at https://github.com/iamwangyabin/PoundNet.
Detect Closer Surfaces that can be Seen: New Modeling and Evaluation in Cross-domain 3D Object Detection
Jul 04, 2024



The performance of domain adaptation technologies has not yet reached an ideal level in the current 3D object detection field for autonomous driving, which is mainly due to significant differences in the size of vehicles, as well as the environments they operate in when applied across domains. These factors together hinder the effective transfer and application of knowledge learned from specific datasets. Since the existing evaluation metrics are initially designed for evaluation on a single domain by calculating the 2D or 3D overlap between the prediction and ground-truth bounding boxes, they often suffer from the overfitting problem caused by the size differences among datasets. This raises a fundamental question related to the evaluation of the 3D object detection models' cross-domain performance: Do we really need models to maintain excellent performance in their original 3D bounding boxes after being applied across domains? From a practical application perspective, one of our main focuses is actually on preventing collisions between vehicles and other obstacles, especially in cross-domain scenarios where correctly predicting the size of vehicles is much more difficult. In other words, as long as a model can accurately identify the closest surfaces to the ego vehicle, it is sufficient to effectively avoid obstacles. In this paper, we propose two metrics to measure 3D object detection models' ability of detecting the closer surfaces to the sensor on the ego vehicle, which can be used to evaluate their cross-domain performance more comprehensively and reasonably. Furthermore, we propose a refinement head, named EdgeHead, to guide models to focus more on the learnable closer surfaces, which can greatly improve the cross-domain performance of existing models not only under our new metrics, but even also under the original BEV/3D metrics.
Linear Disentangled Representations and Unsupervised Action Estimation
Aug 18, 2020



Disentangled representation learning has seen a surge in interest over recent times, generally focusing on new models to optimise one of many disparate disentanglement metrics. It was only with Symmetry Based Disentangled Representation Learning that a robust mathematical framework was introduced to define precisely what is meant by a "linear disentangled representation". This framework determines that such representations would depend on a particular decomposition of the symmetry group acting on the data, showing that actions would manifest through irreducible group representations acting on independent representational subspaces. ForwardVAE subsequently proposed the first model to induce and demonstrate a linear disentangled representation in a VAE model. In this work we empirically show that linear disentangled representations are not present in standard VAE models and that they instead require altering the loss landscape to induce them. We proceed to show that such representations are a desirable property with regard to classical disentanglement metrics. Finally we propose a method to induce irreducible representations which forgoes the need for labelled action sequences, as was required by prior work. We explore a number of properties of this method, including the ability to learn from action sequences without knowledge of intermediate states.
Extended Formulations for Online Linear Bandit Optimization
Sep 30, 2015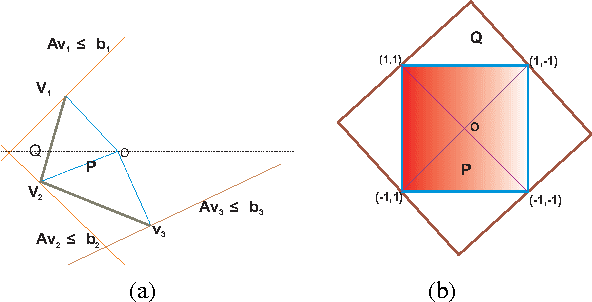
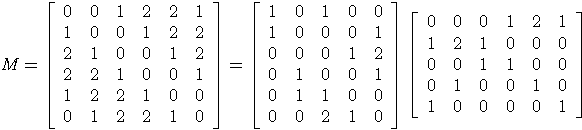
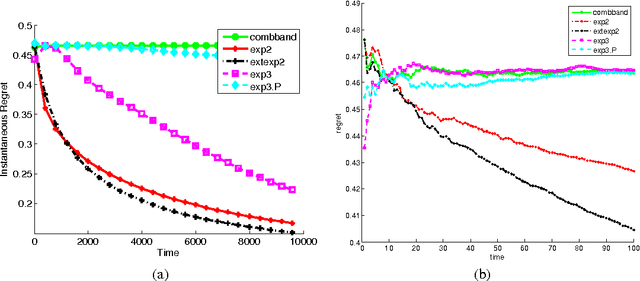
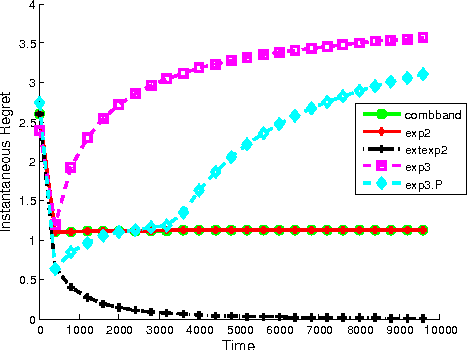
On-line linear optimization on combinatorial action sets (d-dimensional actions) with bandit feedback, is known to have complexity in the order of the dimension of the problem. The exponential weighted strategy achieves the best known regret bound that is of the order of $d^{2}\sqrt{n}$ (where $d$ is the dimension of the problem, $n$ is the time horizon). However, such strategies are provably suboptimal or computationally inefficient. The complexity is attributed to the combinatorial structure of the action set and the dearth of efficient exploration strategies of the set. Mirror descent with entropic regularization function comes close to solving this problem by enforcing a meticulous projection of weights with an inherent boundary condition. Entropic regularization in mirror descent is the only known way of achieving a logarithmic dependence on the dimension. Here, we argue otherwise and recover the original intuition of exponential weighting by borrowing a technique from discrete optimization and approximation algorithms called `extended formulation'. Such formulations appeal to the underlying geometry of the set with a guaranteed logarithmic dependence on the dimension underpinned by an information theoretic entropic analysis.