 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Pursuit of Pixel Supervision for Visual Pre-training
Dec 17, 2025At the most basic level, pixels are the source of the visual information through which we perceive the world. Pixels contain information at all levels, ranging from low-level attributes to high-level concepts. Autoencoders represent a classical and long-standing paradigm for learning representations from pixels or other raw inputs. In this work, we demonstrate that autoencoder-based self-supervised learning remains competitive today and can produce strong representations for downstream tasks, while remaining simple, stable, and efficient. Our model, codenamed "Pixio", is an enhanced masked autoencoder (MAE) with more challenging pre-training tasks and more capable architectures. The model is trained on 2B web-crawled images with a self-curation strategy with minimal human curation. Pixio performs competitively across a wide range of downstream tasks in the wild, including monocular depth estimation (e.g., Depth Anything), feed-forward 3D reconstruction (i.e., MapAnything), semantic segmentation, and robot learning, outperforming or matching DINOv3 trained at similar scales. Our results suggest that pixel-space self-supervised learning can serve as a promising alternative and a complement to latent-space approaches.
Depth Anything with Any Prior
May 15, 2025This work presents Prior Depth Anything, a framework that combines incomplete but precise metric information in depth measurement with relative but complete geometric structures in depth prediction, generating accurate, dense, and detailed metric depth maps for any scene. To this end, we design a coarse-to-fine pipeline to progressively integrate the two complementary depth sources. First, we introduce pixel-level metric alignment and distance-aware weighting to pre-fill diverse metric priors by explicitly using depth prediction. It effectively narrows the domain gap between prior patterns, enhancing generalization across varying scenarios. Second, we develop a conditioned monocular depth estimation (MDE) model to refine the inherent noise of depth priors. By conditioning on the normalized pre-filled prior and prediction, the model further implicitly merges the two complementary depth sources. Our model showcases impressive zero-shot generalization across depth completion, super-resolution, and inpainting over 7 real-world datasets, matching or even surpassing previous task-specific methods. More importantly, it performs well on challenging, unseen mixed priors and enables test-time improvements by switching prediction models, providing a flexible accuracy-efficiency trade-off while evolving with advancements in MDE models.
UniMatch V2: Pushing the Limit of Semi-Supervised Semantic Segmentation
Oct 14, 2024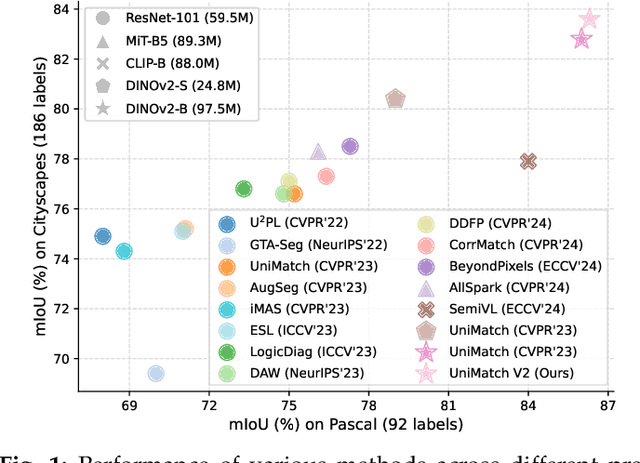
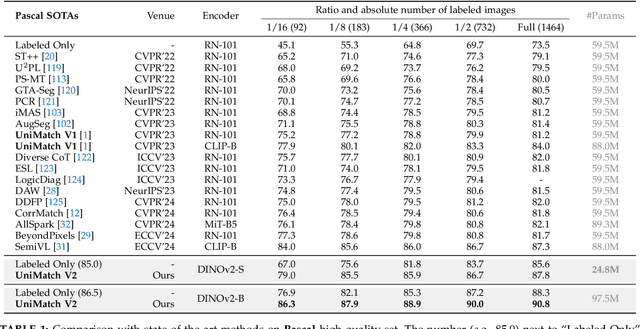
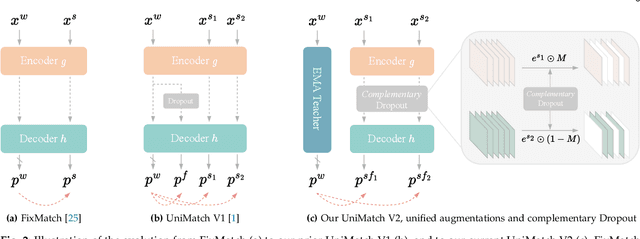
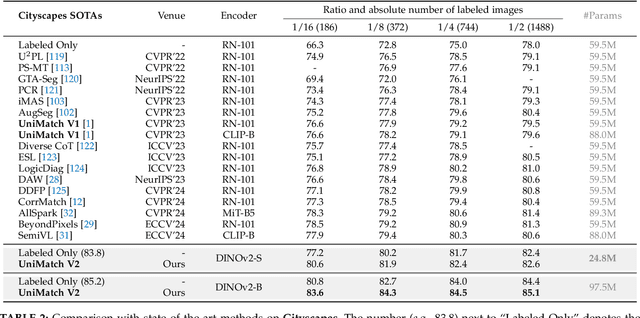
Semi-supervised semantic segmentation (SSS) aims at learning rich visual knowledge from cheap unlabeled images to enhance semantic segmentation capability. Among recent works, UniMatch improves its precedents tremendously by amplifying the practice of weak-to-strong consistency regularization. Subsequent works typically follow similar pipelines and propose various delicate designs. Despite the achieved progress, strangely, even in this flourishing era of numerous powerful vision models, almost all SSS works are still sticking to 1) using outdated ResNet encoders with small-scale ImageNet-1K pre-training, and 2) evaluation on simple Pascal and Cityscapes datasets. In this work, we argue that, it is necessary to switch the baseline of SSS from ResNet-based encoders to more capable ViT-based encoders (e.g., DINOv2) that are pre-trained on massive data. A simple update on the encoder (even using 2x fewer parameters) can bring more significant improvement than careful method designs. Built on this competitive baseline, we present our upgraded and simplified UniMatch V2, inheriting the core spirit of weak-to-strong consistency from V1, but requiring less training cost and providing consistently better results. Additionally, witnessing the gradually saturated performance on Pascal and Cityscapes, we appeal that we should focus on more challenging benchmarks with complex taxonomy, such as ADE20K and COCO datasets. Code, models, and logs of all reported values, are available at https://github.com/LiheYoung/UniMatch-V2.
Depth Anything V2
Jun 13, 2024



This work presents Depth Anything V2. Without pursuing fancy techniques, we aim to reveal crucial findings to pave the way towards building a powerful monocular depth estimation model. Notably, compared with V1, this version produces much finer and more robust depth predictions through three key practices: 1) replacing all labeled real images with synthetic images, 2) scaling up the capacity of our teacher model, and 3) teaching student models via the bridge of large-scale pseudo-labeled real images. Compared with the latest models built on Stable Diffusion, our models are significantly more efficient (more than 10x faster) and more accurate. We offer models of different scales (ranging from 25M to 1.3B params) to support extensive scenarios. Benefiting from their strong generalization capability, we fine-tune them with metric depth labels to obtain our metric depth models. In addition to our models, considering the limited diversity and frequent noise in current test sets, we construct a versatile evaluation benchmark with precise annotations and diverse scenes to facilitate future research.
Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
Jan 19, 2024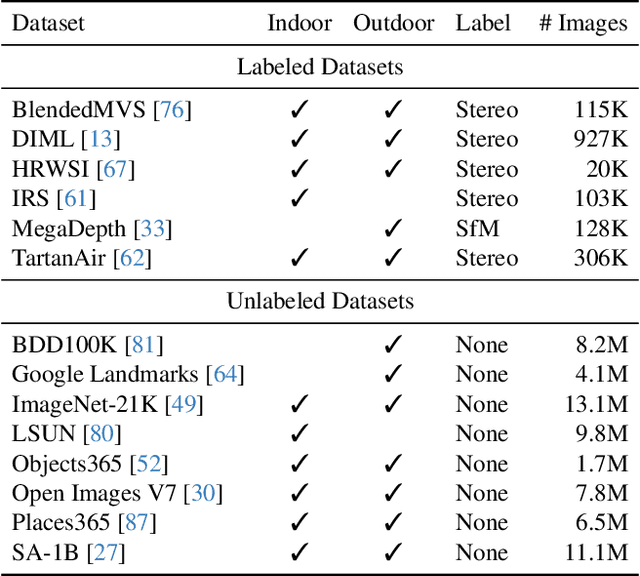
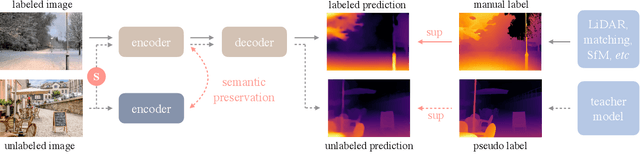

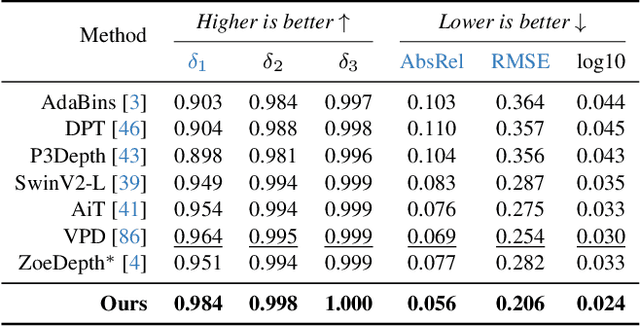
This work presents Depth Anything, a highly practical solution for robust monocular depth estimation. Without pursuing novel technical modules, we aim to build a simple yet powerful foundation model dealing with any images under any circumstances. To this end, we scale up the dataset by designing a data engine to collect and automatically annotate large-scale unlabeled data (~62M), which significantly enlarges the data coverage and thus is able to reduce the generalization error. We investigate two simple yet effective strategies that make data scaling-up promising. First, a more challenging optimization target is created by leveraging data augmentation tools. It compels the model to actively seek extra visual knowledge and acquire robust representations. Second, an auxiliary supervision is developed to enforce the model to inherit rich semantic priors from pre-trained encoders. We evaluate its zero-shot capabilities extensively, including six public datasets and randomly captured photos. It demonstrates impressive generalization ability. Further, through fine-tuning it with metric depth information from NYUv2 and KITTI, new SOTAs are set. Our better depth model also results in a better depth-conditioned ControlNet. Our models are released at https://github.com/LiheYoung/Depth-Anything.
A Lightweight Clustering Framework for Unsupervised Semantic Segmentation
Nov 30, 2023
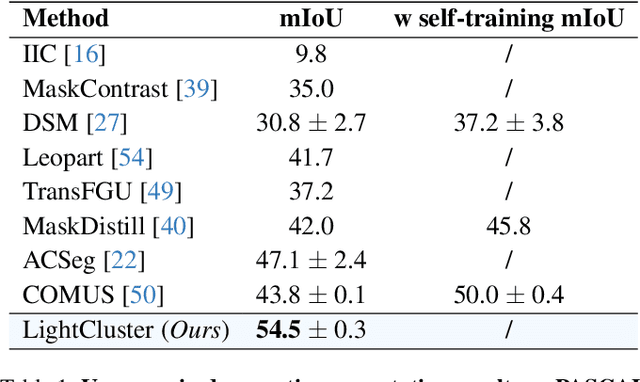
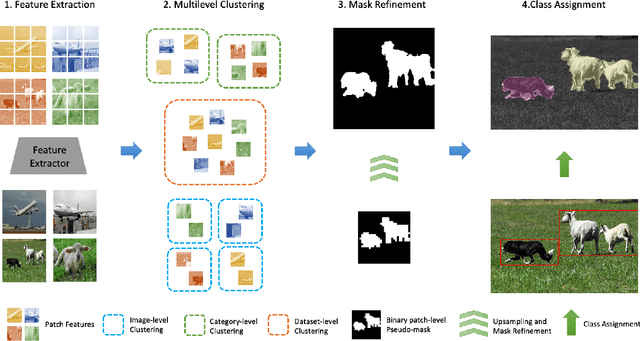
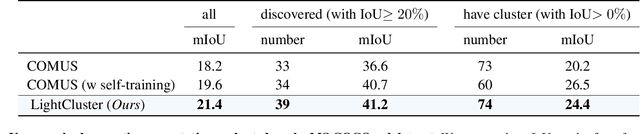
Unsupervised semantic segmentation aims to label each pixel of an image to a corresponding class without the use of annotated data. It is a widely researched area as obtaining labeled datasets are expensive. While previous works in the field demonstrated a gradual improvement in segmentation performance, most of them required neural network training. This made segmentation equally expensive, especially when dealing with large-scale datasets. We thereby propose a lightweight clustering framework for unsupervised semantic segmentation. Attention features of the self-supervised vision transformer exhibit strong foreground-background differentiability. By clustering these features into a small number of clusters, we could separate foreground and background image patches into distinct groupings. In our clustering framework, we first obtain attention features from the self-supervised vision transformer. Then we extract Dataset-level, Category-level and Image-level masks by clustering features within the same dataset, category and image. We further ensure multilevel clustering consistency across the three levels and this allows us to extract patch-level binary pseudo-masks. Finally, the pseudo-mask is upsampled, refined and class assignment is performed according to the CLS token of object regions. Our framework demonstrates great promise in unsupervised semantic segmentation and achieves state-of-the-art results on PASCAL VOC and MS COCO datasets.
FreeMask: Synthetic Images with Dense Annotations Make Stronger Segmentation Models
Oct 23, 2023
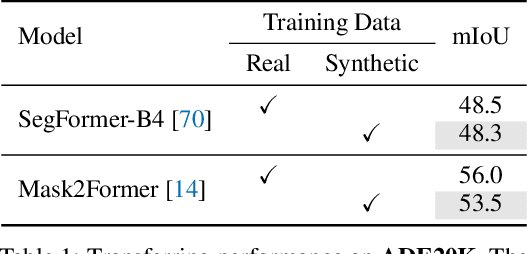
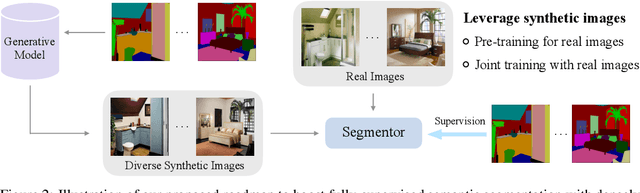

Semantic segmentation has witnessed tremendous progress due to the proposal of various advanced network architectures. However, they are extremely hungry for delicate annotations to train, and the acquisition is laborious and unaffordable. Therefore, we present FreeMask in this work, which resorts to synthetic images from generative models to ease the burden of both data collection and annotation procedures. Concretely, we first synthesize abundant training images conditioned on the semantic masks provided by realistic datasets. This yields extra well-aligned image-mask training pairs for semantic segmentation models. We surprisingly observe that, solely trained with synthetic images, we already achieve comparable performance with real ones (e.g., 48.3 vs. 48.5 mIoU on ADE20K, and 49.3 vs. 50.5 on COCO-Stuff). Then, we investigate the role of synthetic images by joint training with real images, or pre-training for real images. Meantime, we design a robust filtering principle to suppress incorrectly synthesized regions. In addition, we propose to inequally treat different semantic masks to prioritize those harder ones and sample more corresponding synthetic images for them. As a result, either jointly trained or pre-trained with our filtered and re-sampled synthesized images, segmentation models can be greatly enhanced, e.g., from 48.7 to 52.0 on ADE20K. Code is available at https://github.com/LiheYoung/FreeMask.
Diverse Cotraining Makes Strong Semi-Supervised Segmentor
Aug 18, 2023



Deep co-training has been introduced to semi-supervised segmentation and achieves impressive results, yet few studies have explored the working mechanism behind it. In this work, we revisit the core assumption that supports co-training: multiple compatible and conditionally independent views. By theoretically deriving the generalization upper bound, we prove the prediction similarity between two models negatively impacts the model's generalization ability. However, most current co-training models are tightly coupled together and violate this assumption. Such coupling leads to the homogenization of networks and confirmation bias which consequently limits the performance. To this end, we explore different dimensions of co-training and systematically increase the diversity from the aspects of input domains, different augmentations and model architectures to counteract homogenization. Our Diverse Co-training outperforms the state-of-the-art (SOTA) methods by a large margin across different evaluation protocols on the Pascal and Cityscapes. For example. we achieve the best mIoU of 76.2%, 77.7% and 80.2% on Pascal with only 92, 183 and 366 labeled images, surpassing the previous best results by more than 5%.
Shrinking Class Space for Enhanced Certainty in Semi-Supervised Learning
Aug 13, 2023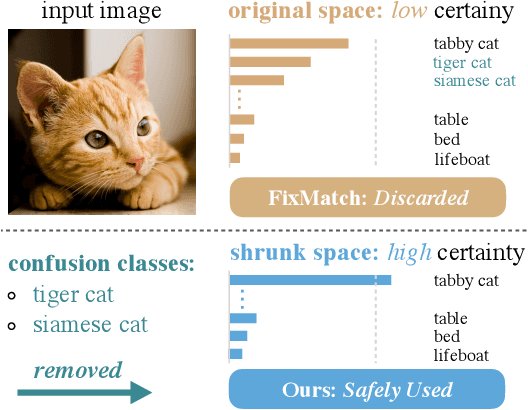
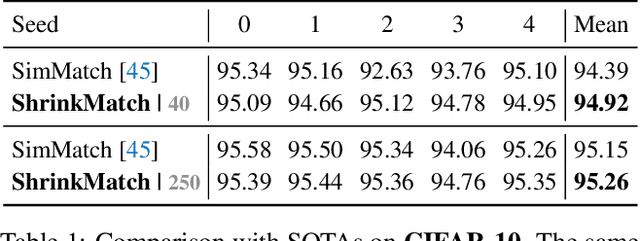
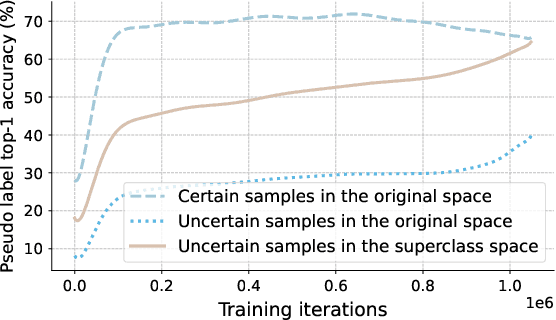
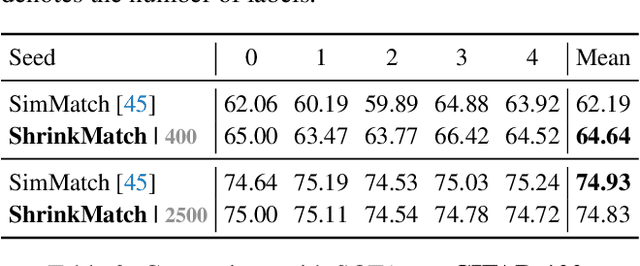
Semi-supervised learning is attracting blooming attention, due to its success in combining unlabeled data. To mitigate potentially incorrect pseudo labels, recent frameworks mostly set a fixed confidence threshold to discard uncertain samples. This practice ensures high-quality pseudo labels, but incurs a relatively low utilization of the whole unlabeled set. In this work, our key insight is that these uncertain samples can be turned into certain ones, as long as the confusion classes for the top-1 class are detected and removed. Invoked by this, we propose a novel method dubbed ShrinkMatch to learn uncertain samples. For each uncertain sample, it adaptively seeks a shrunk class space, which merely contains the original top-1 class, as well as remaining less likely classes. Since the confusion ones are removed in this space, the re-calculated top-1 confidence can satisfy the pre-defined threshold. We then impose a consistency regularization between a pair of strongly and weakly augmented samples in the shrunk space to strive for discriminative representations. Furthermore, considering the varied reliability among uncertain samples and the gradually improved model during training, we correspondingly design two reweighting principles for our uncertain loss. Our method exhibits impressive performance on widely adopted benchmarks. Code is available at https://github.com/LiheYoung/ShrinkMatch.
Augmentation Matters: A Simple-yet-Effective Approach to Semi-supervised Semantic Segmentation
Dec 09, 2022



Recent studies on semi-supervised semantic segmentation (SSS) have seen fast progress. Despite their promising performance, current state-of-the-art methods tend to increasingly complex designs at the cost of introducing more network components and additional training procedures. Differently, in this work, we follow a standard teacher-student framework and propose AugSeg, a simple and clean approach that focuses mainly on data perturbations to boost the SSS performance. We argue that various data augmentations should be adjusted to better adapt to the semi-supervised scenarios instead of directly applying these techniques from supervised learning. Specifically, we adopt a simplified intensity-based augmentation that selects a random number of data transformations with uniformly sampling distortion strengths from a continuous space. Based on the estimated confidence of the model on different unlabeled samples, we also randomly inject labelled information to augment the unlabeled samples in an adaptive manner. Without bells and whistles, our simple AugSeg can readily achieve new state-of-the-art performance on SSS benchmarks under different partition protocols.